社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Python有个处理大数据的库,结合xlrd库,在做一些大数据的处理统计工作的时候很好用,譬如做性能测试,你的结果数据如何统计,python有个库pandas,这个就很擅长做这个工作,这里就讲2个pandas的骚操作。 pandas中groupby、Grouper和agg函数的使用。这2个函数作用类似,都是对数据集中的一类属性进行聚合操作,比如统计一个用户在每个月内的全部花销,统计某个属性的最大、最小、累和、平均等数值。
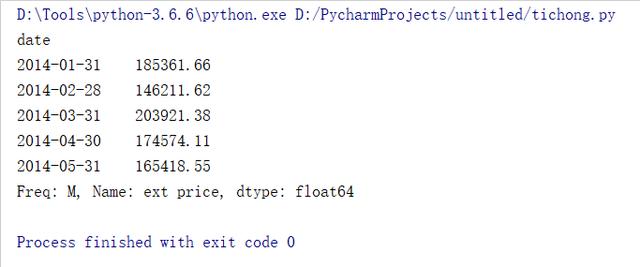
统计“ext price”这个属性在每个月的累和(sum)值
- import pandas as pd
- import collections
- df = pd.read_excel("D:/Download/chrome/sample-salesv3.xlsx")
- #print (df.head(10))
- df["date"] = pd.to_datetime(df["date"])
- # print (df.head(10))
- df1 = df.set_index("date").resample("M")['ext price'].sum()
- # print(df1.head())
统计每个用户每个月"ext price"这个属性的sum值,利用Grouper
- df2 = df.groupby(["name",pd.Grouper(key = "date",freq="M")])["ext price"]
- print(df2.head(10))

Agg
agg函数,它提供基于列的聚合操作。而groupby可以看做是基于行,或者说index的聚合操作。
从实现上看,groupby返回的是一个DataFrameGroupBy结构,这个结构必须调用聚合函数(如sum)之后,才会得到结构为Series的数据结果。
而agg是DataFrame的直接方法,返回的也是一个DataFrame。当然,很多功能用sum、mean等等也可以实现。但是agg更加简洁, 而且传给它的函数可以是字符串,也可以自定义,参数是column对应的子DataFrame
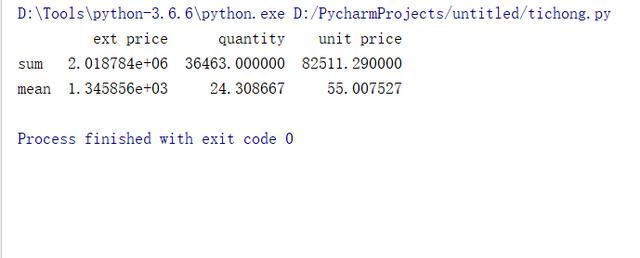
获取"ext price","quantity","unit price"3列的各自的累计值和均值
- df3 = df[["ext price","quantity","unit price"]].agg(["sum","mean"])
- print(df3.head())
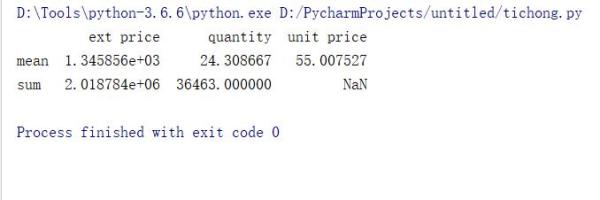
可以针对不同的列使用不同的聚合函数
- df4 = df.agg({"ext price":["sum","mean"],"quantity":["sum","mean"],"unit price":["mean"]})
- print(df4.head())
也可以自定义函数,比如,统计sku中,购买次数最多的产品编号,通过lambda表达式来做。
- #统计sku中,购买次数最多的产品编号
- get_max = lambda x:x.value_counts(dropna=False).index[0]
- get_max.__name__ = "most frequent"
- df5 = df.agg({"ext price":["sum","mean"],
- "quantity":["sum","mean"],
- "unit price":["mean"],
- "sku":[get_max]
- })
- print(df5)
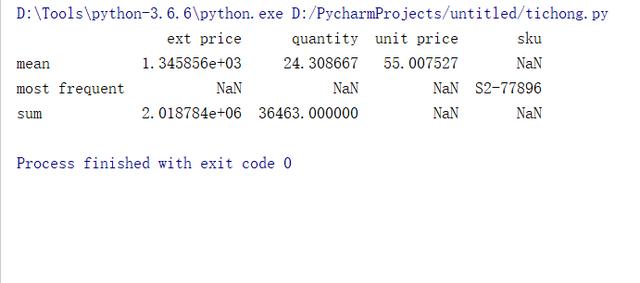
如果希望输出的列按照某个顺序排列,可以使用collections的OrderedDict
- agg_dict = {
- "ext price":["sum","mean"],
- "quantity":["sum","mean"],
- "unit price":["mean"],
- "sku":[get_max]
- }
- #按照列名的长度排序。OrderedDict的顺序是跟插入顺序一致的
- df6 = df.agg(collections.OrderedDict(sorted(agg_dict.items(),key=lambda x:len(x[0]))))
- print(df6)
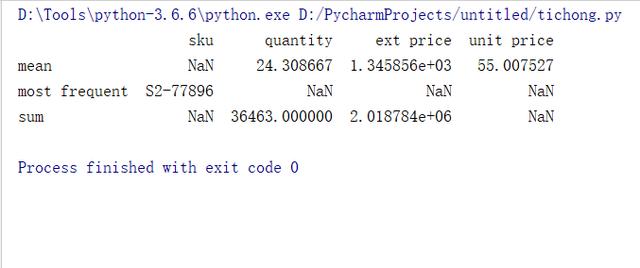
源数据的链接:https://github.com/chris1610/pbpython/tree/master/data
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
