
nosql sql
两个系列的第二部分:使用Apache Drill重新思考数据库设计
在本系列的第1部分“ 深入健康选择”中,我们探索了使用Drill创建Parquet表以及配置Drill读取不是很标准的数据格式。 我们还通过在Drill中编写一些不同的查询来探索USDA国家营养数据库。
在本系列的第二部分中,我们将利用同一数据库来思考传统数据库设计之外的问题。
传统数据库设计
在过去的30年中,软件应用程序利用RDBMS来保留其数据。 之所以一直这样,是因为RDBMS通常由IT组织支持,这使得将软件引入生产环境变得容易得多。 通常,工程师使用他们正在使用的编程语言创建数据结构,然后弄清楚如何将这些数据结构映射到一系列数据库表。 在Java领域中,有许多不同的持久性“解决方案”。 最新的是Java Persistence API和Hibernate。 这些是为了从基础数据库技术提供抽象以提供一定程度的可移植性。 主要问题在于,可移植性实际上仅是从一个RDBMS到另一个。 第二个问题是创建这些映射不是一件容易的事,并且需要大量的工作来测试它们是否按预期工作。
似乎将整个数据结构保持不变会更有意义。 这将使其真正具有便携性,并且更易于开发和测试。 让我们不要忘记,这也将使查询数据变得容易得多。 针对复杂的数据库模式编写SQL查询是一场噩梦。 针对大型架构SQL查询不仅难以编写,而且为人们研究那些复杂数据库架构中存储的数据提供了障碍。 研究人员必须弄清楚哪些表中的哪些列表示他们要寻找答案的问题范围内的含义。 在此过程的每个阶段,每个参与人员都可以轻松地完成工作。
进化的时间
让我们重新回顾上一篇涵盖USDA提供的国家营养数据库的文章的数据库架构。
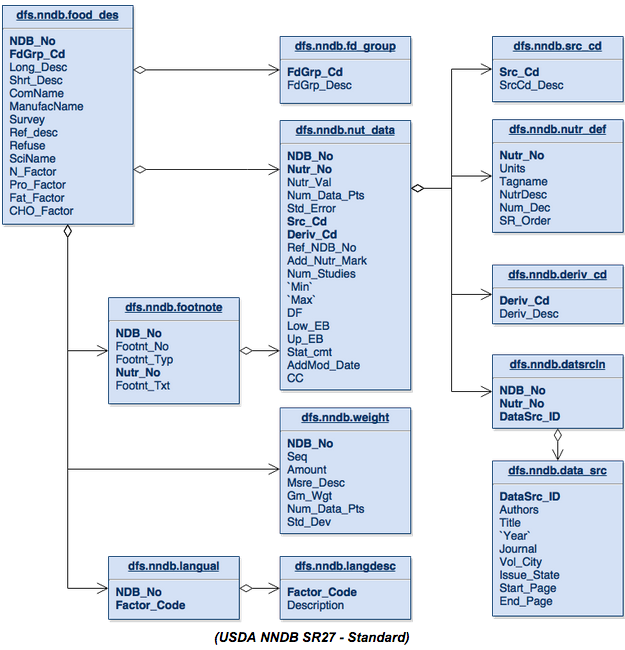
从该模式的顶部开始,我们可以看到fd_group表仅是一个明细表 ,该表在food_des表中的每个条目中最多产生一条记录。 我们还在nut_data表上看到了与src_cd , nutr_def和deriv_cd相同的关系。
nut_data , 脚注和权重表在food_des表中每个项目可以具有零个或多个条目,并产生我喜欢的列表。 datsrcln表只不过是从nut_data到data_src的联接表,对于语言表到langdesc表也是如此 。 两者都只产生数据列表。
此表结构是按其本身的方式构建的,以支持简单数据列表或复杂数据列表的概念。 这种类型的表模式以前存在的好处是可以节省磁盘存储空间。 现在的存储成本是10到30年前的数千倍,因此我们不会真正节省任何存储成本。
让我们开始简化数据库架构,以查看是否可以使其对所有相关方更好:
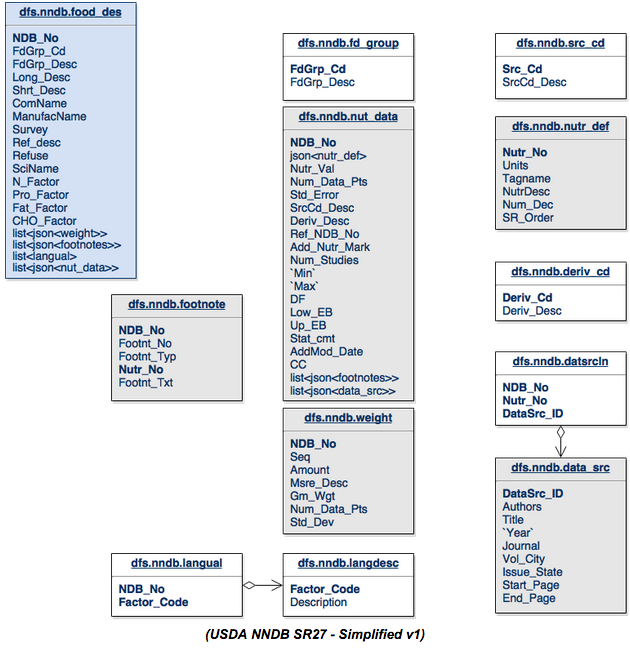
看一下food_des表中的更改。 fd_group表中的FdGrp_Desc已合并到food_des表中。 权重表作为列表合并到food_des表中。 这是一个列表,因为与food_des表相关的表中可能有零个或多个元素。 我们可以提炼出langual和langdesc表下从langdesc表“说明”的列表,并把它们存储在food_des表。 nut_data表可以成为food-des表中元素的列表。
然后,我们可以采用src_cd , nutr_def和deriv_cd并将它们直接合并到nut_data表结构中。 datasrcln表是data_src返回到nut_data的联接表,因此我们也将其合并为元素列表。
这里更有趣的情况是,从原始模式检查了脚注表后,似乎脚注和nut_data之间的关系未正确编写。 箭头可能指向相反的方向。 脚注表包含两种类型的脚注。 它包含与通过ndb_no的food_des脚注,但它也可以通过ndb_no和nutr_no的组合涉及nut_data。 为了在新模式中支持此操作,我们将分解脚注表,并在nut_data和food_des中创建脚注列表。
现在灰色的表是另一个表中的JSON格式的数据结构。 白表基本上只是直接或作为列表合并到其父表中。
通过“浪费”一点空间(与标准设计相比),我们现在得到一张数据表,该数据表现在突然可以被任何人理解。 这是此数据模式的简单视图:
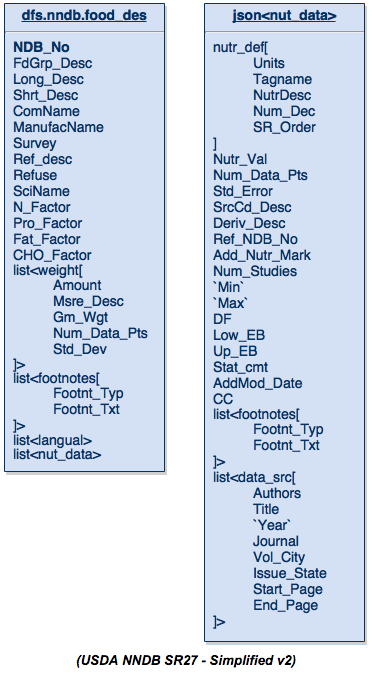
左边的表是food_des表,右边的表只是以前包含营养数据( nut_data )的JSON数据结构。 当您浏览此内容时,您会发现它包含表中最初定义的所有字段,减去一些不再相关的字段,例如序列号或因子代码,或仅用于创建的其他任何字段表之间的关系。
这是原始数据库中的某些数据的数据提取,并使用此JSON结构供您测试。 该数据包含一个food_des记录(我手动添加了一个语言条目,该记录在原始数据库中不存在)。 复制此数据并将其放入文件/tmp/food_des.json中 ,您将可以自行运行其余查询。
{
"ndb_no":"08613",
"shrt_desc":"CEREALS RTE,KELLOGG'S SPL K MULTIGRAIN OATS & HONEY",
"nut_data":[{
"nutr_no": "203",
"nutr_val": "7.80",
"nutr_def": {"num_dec":2,"tagname":"PROCNT","nutrdesc":"Protein"},
"data_src":[{
"datasrc_id": "S6941",
"authors": "A Kellogg, Co.",
"title": "Kellogg Company Data",
"Year": "2011"
}]
}, {
"nutr_no": "204",
"nutr_val": "1.80",
"nutr_def": {"num_dec":2,"tagname":"FAT","nutrdesc":"Total lipid (fat)"},
"data_src":[{
"datasrc_id": "S6941",
"authors": "B Kellogg, Co.",
"title": "Kellogg Company Data",
"Year": "2011"
}]
}, {
"nutr_no": "205",
"nutr_val": "85.00",
"nutr_def": {"num_dec":2,"tagname":"CHOCDF","nutrdesc":"Carbohydrate, by difference"},
"data_src":[{
"datasrc_id": "S6941",
"authors": "C Kellogg, Co.",
"title": "Kellogg Company Data",
"Year": "2011"
}]
}],
"langual":["ANISE","FRUIT","WHOLE, NATURAL SHAPE","NOT HEAT-TREATED","COOKING METHOD NOT APPLICABLE","WATER REMOVED","HEAT DRIED","HUMAN FOOD, NO AGE SPECIFICATION"]
}复杂的数据结构查询能力
Apache Drill的构建旨在能够查询复杂的数据结构,例如上面的表格。 我们可以从最简单的用例之一开始,即表中的列表$ lt; langual> 。 该列表是描述food_des项的常用方法。 为了在原始模式中找到单个项目的公共语言信息,我们必须运行以下查询:
SELECT fd.NDB_No, ld.Description FROM dfs.nndb.food_des fd
LEFT JOIN dfs.nndb.langual lf ON (fd.NDB_No=lf.NDB_No)
LEFT JOIN dfs.nndb.langdesc ld ON (lf.FACTOR_CODE=ld.FACTOR_CODE)
where fd.NDB_No=02001;这是新模式中的查询,它利用了Drill中的FLATTEN函数:
SELECT NDB_No, FLATTEN(langual) FROM dfs.tmp.`food_des.json` fd where fd.NDB_No=08613;这两个查询对于语言列表中的每个描述都返回一行。 第二个查询更易于理解和编写。 对于任何想进行研究的人来说,这都将直接节省时间,因为他们将有更多的时间来处理数据。
让我们看一下一个查询,它要复杂得多。 我们将从多个表中选择一些字段,以查找有关食品的详细信息以及这些详细信息的来源。 此查询并非全部包含所有可以提取的详细信息,并且仅限于三个nutr_no记录:
SELECT fd.ndb_no, fd.shrt_desc, nd.nutr_no, nd.nutr_val, ndd.num_dec, ndd.tagname, ndd.nutrdesc, ds.authors, ds.title, ds.`year`
FROM dfs.nndb.food_des fd, dfs.nndb.nut_data nd, dfs.nndb.nutr_def ndd, dfs.nndb.datsrcln dsl, dfs.nndb.data_src ds
WHERE fd.NDB_No=nd.NDB_No
AND nd.Nutr_No=ndd.Nutr_No
AND nd.NDB_No=dsl.NDB_No
AND nd.nutr_no=dsl.Nutr_No
AND dsl.DataSrc_ID=ds.DataSrc_ID
AND fd.NDB_No=08613
AND nd.nutr_no IN (203,204,205);这是针对新架构的相同查询所希望的内容:
SELECT fd.ndb_no, fd.shrt_desc, fd.nut_data.nutr_no as nutr_no, fd.nut_data.nutr_val as nutr_val, fd.nut_data.nutr_def.num_dec as num_dec, fd.nut_data.nutr_def.tagname as tagname,
fd.nut_data.nutr_def.nutrdesc as nutrdesc, fd.data_src.datasrc_id as datasrc_id, fd.data_src.authors as authors, fd.data_src.title, fd.data_src.`year` as `year`
FROM (SELECT *, FLATTEN(fd1.nut_data.data_src) as data_src
FROM (SELECT *, FLATTEN(fd2.nut_data) FROM dfs.tmp.`food_des.json` fd2) fd1) fd
WHERE fd.ndb_no=08613
AND fd.nut_data.nutr_no IN (203,204,205); 虽然这两个查询的长度相似,但它们的复杂性却截然不同。 由于select语句中所有字段的命名,第二个查询看起来很长。
将查询更改为SELECT *将使我们拥有:
SELECT *
FROM (SELECT *, FLATTEN(fd1.nut_data.data_src) as data_src
FROM (SELECT *, FLATTEN(fd2.nut_data) FROM dfs.tmp.`food_des.json` fd2) fd1) fd
WHERE fd.ndb_no=08613
AND fd.nut_data.nutr_no IN (203,204,205);从这种观点可以很容易地看出,我们除了对嵌套SQL语句进行FLATTEN处理这些嵌套的数据列表以外,实际上并没有做很多事情。 这实际上并不需要主题专业知识,例如加入复杂的表集。 从所有方面来看,这个国家营养数据库的重量只有12个表格,与我研究过的大多数数据库相比,这很容易,因为这些数据库很容易就可以计入数百个表格。
还有两个其他功能对于检查嵌套数据非常方便。 第一个是REPEATED_COUNT。 您可能会猜到,此函数计算列表中的项目数。 通过此查询,我们可以看到语言列表中有多少个元素:
SELECT fd.ndb_no, fd.shrt_desc, REPEATED_COUNT(fd.langual) as lang_count FROM dfs.tmp.`food_des.json` fd;下一个函数是REPEATED_CONTAINS。 此函数检查列表以查找关键字是否存在。 在这里,我们将检查该项目是否用FRUIT字样描述。 您还可以将其更改为任意文本,以验证其返回false:
SELECT fd.ndb_no, fd.shrt_desc, REPEATED_CONTAINS(fd.langual, 'FRUIT') as `Fruit?` FROM dfs.tmp.`food_des.json` fd;这两个功能非常易于使用。 REPEATED_CONTAINS在WHERE子句中很有用,可以在进行研究时限制结果集。 例如,在上述情况下,将查询限制为仅包括列为FRUIT的项目。
NoSQL抢救
到目前为止,我们已经学习了如何简化数据库架构以使其成为可能,以便任何人都可以在对数据库的了解最少的情况下访问数据。 我们还学习了如何使用此SQL查询引擎查询非常复杂的JSON结构。 现在,我们需要研究可以在哪里持久存储数据。
从应用程序的角度来看,在Java之类的语言中以JSON格式持久化(序列化)数据结构非常简单,并且只需要几行代码。 无需复杂的表映射。
// 1 - Serialize a Java POJO using the Google GSON library
Gson gson = new Gson();
String json = gson.toJson(yourObject);
// 2 - Deserialize a Java POJO using the Google GSON library
YourObject yourObject2 = gson.fromJson(json, YourObject.class);现在,我们可以避免所有其他工作,以弄清如何将YourObject.java数据结构映射到数据库模式中的一组表。 这将为您节省大量时间和痛苦。
现在,您可以利用NoSQL存储(例如HBase)的好处。 您可以将其用于在线事务处理(OLTP),以在数据库级别为任何应用程序启用线性可伸缩性。 这意味着在那些企业应用程序中,不再需要担心在达到性能限制(如传统RDBMS系统中)时如何扩展平台。 只需将服务器添加到群集中即可扩展。
您还可以使用Drill直接针对HBase对JSON数据执行实时分析,因为Drill具有开箱即用地查询HBase的能力。 无需进行数据提取或将数据转换为其他格式。
我希望本文能够激发您去思考数据库设计和数据库系统的传统方法之外的问题。 请在下面分享您对这些主题的想法。 我希望收到您的来信。
翻译自: https://www.javacodegeeks.com/2015/07/the-evolution-of-database-schemas-using-sql-nosql.html
nosql sql
