社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
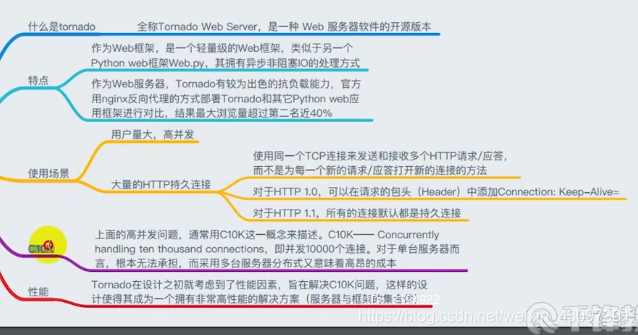
Tornado是一种 Web 服务器软件的开源版本。Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。
得利于其非阻塞的方式和对epoll的运用,Tornado 每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个 理想框架。
反向代理服务器后端的Tornado实例: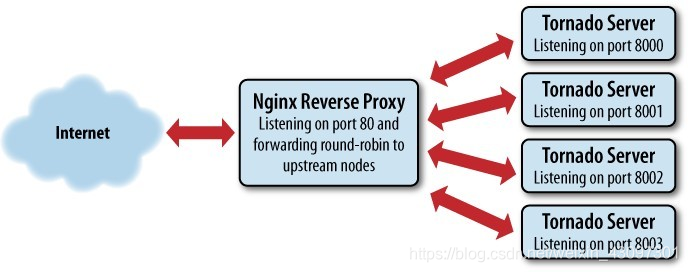
tornado.web:基础web框架模块
tornado.ioloop:核心IO循环模块,高效的基础。封装了:
1.asyncio 协程,异步处理
2. epoll模型:水平触发(状态改变就询问,select(),poll()), 边缘触发(一直询问,epoll())
3.poll 模型:I/O多路复用技术
4.BSD(UNIX操作系统中的一个分支的总称)的kqueue(kueue是在UNIX上比较高效的IO复用技术)
epoll和kqueue的区别如下:
'epoll'仅适用于文件描述符,在Unix中,一切都是文件”。
这大多是正确的,但并非总是如此。例如,计时器不是文件。
信号不是文件。信号量不是文件。进程不是文件。
(在Linux中)网络设备不是文件。类UNIX操作系统中有许多不是文件的东西
。您不能使用select()/ poll()/ epoll来复制那些“事物”。
Linux支持许多补充系统调用,signalfd(),eventfd()和timerfd_create()
它们将非文件资源转换为文件描述符,以便您可以将它们与epoll()复用。
epoll甚至不支持所有类型的文件描述符;
select()/ poll()/ epoll不适用于常规(磁盘)文件。
因为epoll 对准备模型有很强的假设; 监视套接字的准备情况,
以便套接字上的后续IO调用不会阻塞。但是,磁盘文件不适合此模型,因为它们总是准备就绪。
kqueue 中,通用的(struct kevent)系统结构支持各种非文件事件
import tornado.web #tornado.web:基础web框架模块
import tornado.ioloop #tornado.ioloop:核心IO循环模块,高效的基础。
class IndexHandler(tornado.web.RequestHandler):
#类比Django中的视图,相当于业务逻辑处理的类
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
"""
实例化一个app对象
Application:他是tornado.web框架的核心应用类,是与服务器对应的一个接口
里面保存了路由映射表,还有一个listen方法,可以认为用来创建一个http的实例
并绑定了端口
"""
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
app.listen(8888) #绑定监听端口,但此时的服务器并没有开启监听
tornado.ioloop.IOLoop.current().start()
#Application([(r"/" ,IndexHandler),])传入的第一个参数是
#路由路由映射列表,但是在此同时Application还能定义更多参数
#IOLoop.current():返回当前线程的IOLoop实例
#例如实例化对象 ss=run() ,ss.start()
#start():启动了IOloop实例的循环,连接客服端后,同时开启了监听
linux-epoll进行管理多个客服端socket
tornado-IoLoop不断进行询问epoll:小老弟,有没有我需要做的事吗?
当epoll返回说:老哥,有活了
tornado-IoLoop将活上传给tornado.web.Application
tornado.web.Application中有 路由映射表
就会将socket进行一个路由匹配
把socket匹配给相对应的Handler(处理者)
Handler(处理者)处理后将数据返回给对应的socket,
(这里因为可能会延时响应,所以这里进行异步处理)
socket然后再传给了客服端浏览器。
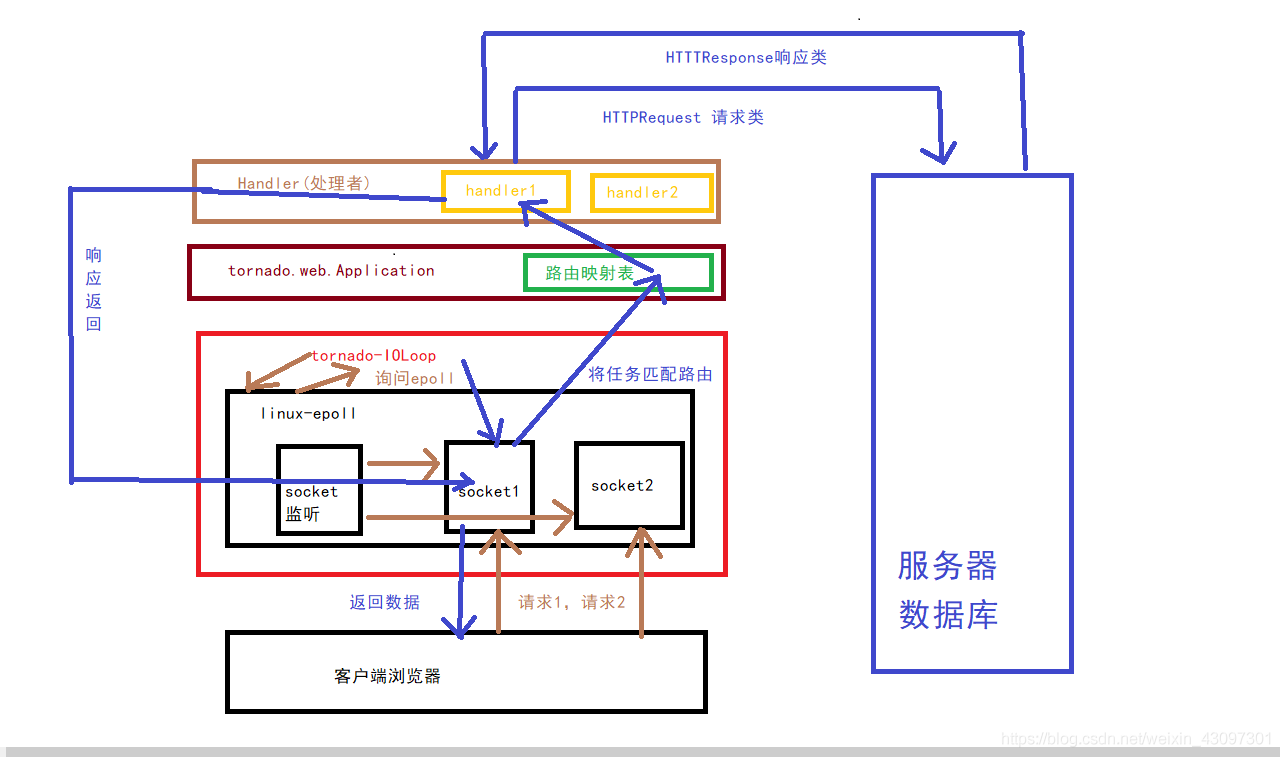
图片将就看啊,手残党。。
新加模块如下:
tornado.httpserver #tornado的HTTP服务器实现
注意:
在windows中运行多进程会报错:
AttributeError: module ‘os’ has no attribute 'fork’
这是因为fork这个系统命令,只在linux中才有用,
如果你是在windows, win7、winxp中运行的话就会出错。
所以把上面的python文件,拷贝到linux的系统中再运行就没问题了.
这个错误我暂时没有解决,后续补上。
import tornado.web
import tornado.ioloop
import tornado.httpserver #tornado的HTTP服务器实现
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(8888) #绑定在指定端口
httpServer.start(2)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
#app.listen(),只能在单进程中使用
#多进程中,虽然torna给我们提供了一次性启动多个进程的方式,但是由于一些问题,不建议使用上面打的方式启动多进程,而是手动启动多个进程,并且我们还能绑定不同的端口
问题如下:
#1.每个子进程都会从父进程中复制一份IOLoop的实例,
如果在创建子进程前修改了IOLoop,会影响所有的子进程
#2.所有的进程都是由一个命令启动的,无法做到不停止服务的情况下修改代码。
修改单个进程是需要关掉所有进程,影响客服服务使用。
#3.所有进程共享一个端口,向要分别监控很困难。
所以:我们手动启动多个进程,并且我们还能绑定不同的端口,进行单个进程操作。
新运用模块如下:
tornado.options模块:提供了全局参数的定义,储存和转换
属性和方法
tornado.options.define()
原型tornado.options.define(name, default=None, type=None, help=None, metavar=None,multiple=False, group=None, callback=None)
常用参数:
# name(选项变量名),必须保证其唯一性,
否则报错"options 'xxx' already define in '....'"
#default(设置选项变量的默认值),默认为None
#type(设置选项变量的类型),str,int,float,datetime(时间日期),等,
从命令行或配置文件导入参数时,会根据类型转换输入的值。
如果不能转化则报错,如果没有设置type的值,
会根据default的值的类型进行转换,比如default的值 8000,
而传给type的为‘8080’字符串,
则会转换成int类型。如果default也没有设置,则不转化
#multipe(设置选项变量是否为多个值),默认False 比如传递为列表,
列表包括了多个值,就要改为Ture。
#help 选项变量的提示信息。自主添加,比如 help="描述变量"
#方法
#tornado.options.options
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#获取参数的方法(命令行传入)
#1. tornado.options.parse_command_line()
#作用:转化命令行参数,接收转换并保存
#获取参数的方法(从配置文件导入参数)
#tornado.options.parse_config_file(path=)
1获取参数的方法(命令行传入)
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options #提供了全局参数的定义,储存和转换
from tornado.options import options #全局的options对象,所有定义的选项变量都会作为该对象的属性
#定义两个参数
tornado.options.define('port', default=8000, type=int)
tornado.options.define('list', default=[], type=str,multiple=True) #multiple=True接收多个值
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
tornado.options.parse_command_line()
#转化命令行参数,接收转换并保存在tornado.options.options里面
print('list',options.list)
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(options.port) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
#注意这里不能直接启动,应为没有进行传值,那要在怎么启动,用命令行cmd进行
#cmd进行当前py文件目录 python server.py --port=9000 --list=good,nice,cool
#启动
#> python server.py --port=9000 --list=good,nice,cool
#启动的时候就指定了端口号,就会启动指定端口号的服务器,也就是说我们不用每次用都去修改我们的代码的端口
#(输出)list ['good', 'nice', 'cool']
2.获取参数的方法(从配置文件导入参数)
将上面的代码中的tornado.options.parse_command_line()进行更改为
tornado.options.parse_config_file(“config”)
#"config"为配置文件,这里因为是在同一级目录下,所以直接写文件名,如果不在则需要进行书写路径。
#需要创建名为config的普通文件,作为配置文件
在里面进行书写配置。
config配置文件 例如:
port=7000
list=["job","good","nice"]
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options #提供了全局参数的定义,储存和转换
from tornado.options import options #全局的options对象,所有定义的选项变量都会作为该对象的属性
#定义两个参数
tornado.options.define('port', default=8000, type=int)
tornado.options.define('list', default=[], type=str,multiple=True) #multiple=True接收多个值
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
tornado.options.parse_config_file("config")
#需要创建名为config的普通文件
print('list',options.list)
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(options.port) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
说明:这两种方法以后都不常用,常用的是文件配置,但是是.py文件进行配置。
因为书写格式人需要按照Python的语法要求,并且普通的文件不支持字典类型
创建config.py文件编写配置文件
#定义字典
#新建文件config.py文件,配置模型:
options = {
‘port’:8080,
‘list’:[‘good’,‘nicd’,‘job’]
}
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
import tornado1.config #直接导入配置的py文件
class IndexHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
print('list=',tornado1.config.options["list"])
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
httpServer.bind(tornado1.config.options["port"]) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
http://127.0.0.1:9000/error?flag=0
向error页面传递flag=0这个值,其中?表示传值
页面中接收flag
def get(self, *args, **kwargs):
flag = self.get_query_argument("flag")
get_query_argument()/get_query_arguments()/get_body_argument()/get_body_arguments()
上述四个获取值方法统一参数:(name, default=_ARG_DEFAULT, strip=True)
# name:获取name属性的值
default:设置默认值,如果没有参数传递过来,那么就是用默认值
strip: 去除左右空格
复制代码
# 使用get方式传递参数
def get(self):
# 获取单个键值
get_a = self.get_query_argument('a') # 如果同时传递多个a的参数,那么会采用后面覆盖前面的原则
self.write(get_a)
# 其中获取多个使用:get_query_arguments()
# 使用post传递参数
def post(self):
# 接收单个参数
post_a = self.get_body_argument('a')
self.write(post_a)
# 其中获取多个参数传递使用get_body_arguments()
复制代码
使用get_argument()/get_arguments()可以不区分post/get传递方式
def post(self):
# 接收单个参数
post_a = self.get_argument('a')
self.write(post_a)
# 其中获取多个参数传递使用get_arguments()
值得注意的是:使用上述方法获取参数只能够获取headers报头为"application/x-www-form-urlencoded"或者"multipart/form-data"的数据,如果想获取json或者xml方式传递的数据需要使用self.request方式获取
def post(self):
self.write(self.request.headers.get('Content-Type')) # 获取“application/json”类型传递
# 如果想获取内容,可以使用self.request.body
当我们使用命令行传递参数parse_command_line()或者配置文件parse_config_file(path)传递参数是,tornado会默认开启日志,向终端打印信息。
比如在传递参数parse_command_line()类型中。
python server.py --port=9000 --list=good,job,nice 启动py文件后
在进行网页登录本地地址(ipconfig可查看)192.168.22.33:7000进入后
cmd终端就会打印[I 181215 19:13:39 web:2162] 304 GET / (192.168.22.33) 1.00ms #I为信息(information) 或者 [W 181215 19:18:10 web:2162] 404 GET /index (192.168.43.145) 0.50ms #W为错误(wrong)
如果不想让终端打印
在tornado.options.parse_command_line()之前加上tornado.options.options.logging=None
或者在cmd中
python server.py --port=9000 --list=good,job,nice --logging=none
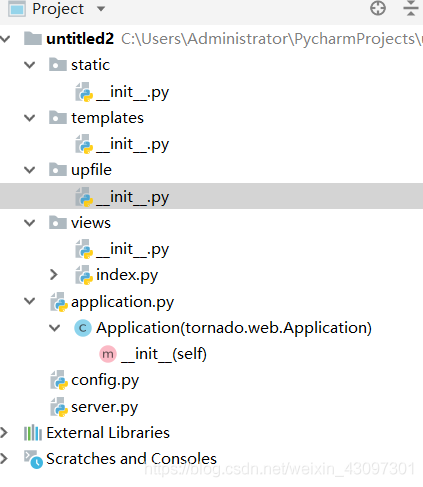
1.static文件夹-----------------静态页面存放
2.templates文件夹-----------模板存放
3.upfile文件夹----------------上传文件存放
4.views文件夹----------------视屏存放
5.application文件-------------视屏编写
6.config文件 ------------------配置文件编写
7.server文件------------------服务编写
1.server文件基本样式
import tornado.web #web框架模块
import tornado.ioloop #核心IO循环模块
import tornado.httpserver #tornado的HTTP服务
import tornado.options #全局参数定义,存储和转化模块
import config #导入自定义配置的py文件
import application #导入自定义的应用程序模块
"""
#server
服务设置
"""
if __name__=="__main__":
app = application.Application #处理请求服务类
httpServer = tornado.httpserver.HTTPServer(app) #设置HTTP服务器
httpServer.bind(config.options["port"]) #绑定在指定端口
httpServer.start(1) #线程数
tornado.ioloop.IOLoop.current().start() #启动
2.congif文件
"""
#config
存放参数
"""
options ={
"port" : 8000,
}
"""
#config
配置文件,相当于django里面的setting
配置application应用程序路由,即文件地址路径
##BASE_DIRS = os.path.dirname(__file__)
当前file文件路径
##os.path.join(BASE_DIRS,"static")
拼接路径:如(BASE_DIRS/static),当然BASE_DIRS=当前文件的父类的文件路径
"""
import os
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转义
"cookie_secret":"OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks", #混淆加密
"xsrf_cookies":True, #开启xsrf保护
"login_url":"/login",
}
3.application文件夹中Application
import tornado.web
from views import index
from config import setting #导入配置文件setting
"""
#application中设置一个函数子类Application
存放路由
"""
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
(r"/",index.IndexHandler)
#(r"/(.*)$",tornado.web.StaticFileHandler{"path":os.path.join(config.BASE_DIRS,"static/html"),"default_filename":"index.html"}),
#StaticFileHandler应用静态文件,注意要放在所有路由的下面。用来放静态主页
(r"/(.*)$", index.Static_FileHandler,{"path": os.path.join(config.BASE_DIRS, "static/html"), "default_filename": "index.html"}),
#由于我们想让用户进入主页即自动设置xsrf_cookie,所以我们用到继承 的方式,让index.StaticFileHandler继承父类tornado.web.StaticFileHandler,再向里面添加设置xsrf设置
]
super().__init__(handlers,**setting)
#super()函数是用于调用父类(超类)的一个方法。
#Python3可以使用直接使用super().xxx代替super(Class, self).xxx:
#执行的是tornado.web.Application的init,再将handlers传参
#添加配置文件,参数里面加入**setting,(即**kwargs)
4.views中的index基本样式
import tornado.web
from tornado.web import RequestHandler
"""
#views中的index
存放视图
"""
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
import os
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"),
"template_path":os.path.join(BASE_DIRS,"templates"),
"debug":True
}
1.debug
debug:
设置tornado是否工作在调试模式下,默认为debug:False即工作在生产模式下(上线后)。
设置为True即在开发模式(开发中调试)。
debug:True特性如下:
##1.自动重启:
tornado应用会监控源代码文件,当有保存改动时重新启动服务器,会减少手动重启的时间和次数,提高开发效率。
但是:如果保存后代码有错误导致重启失败后,将会变为手动重启,再次重启可能由于之前的端口不是正常关闭,
而导致端口没有被释放,这时候重新切换端口,或者等待端口释放,即可。
如果只想引用这一个特性:通过编写 autoreload = True 进行设置,在config配置文件中字典模式"autoreload" : True
##2.取消缓存编译的模板
用于开放阶段:
修改代码后,并没有发生改变,是因为缓存的存在,并没有应该用达到实际文件上。
通过参数compiled.template_cache=False设置,但在配置文件中用字典形式"compiled.template_cache":False设置
##3.取消缓存静态文件的hash值
用于开发阶段:
加载css文件的时候,tornado中在css文件后面还有hash值(比如a.css?hash=jsajdjafahafasddasdfasdadsasd)
而取消后,相当于为新文件加载,后面得hash值就会变,这样我们就能看到每一次更改后的效果
可以通过参数设置static_hash_cache=False单独设置,配置文件中字典形式"static_hash_cache":False设置
##4.提供追踪信息(不常用)
没有捕获异常时,会生成一个追中页面的信息
可以通过参数serve_traceback=True设置 , 配置文件中字典形式"serve_traceback":True设置
2.static_path
设置静态文件目录
3.static_path
设置模板目录
import tornado.web
from views import index
from config import setting #导入配置文件中的setting
"""
#application中设置一个函数子类Application
存放路由
##简单的形式(r"/",index.IndexHandler)
## 传参形式(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),这里是服务器自己传参,如果要进行用户传参,则对应修改编辑方法
"""
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
(r"/",index.IndexHandler),
(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),
(r"/write",index.WriteHandler),
(r"/json1",index.Json1Handler), #测试json1
(r"/json2", index.Json2Handler), #测试json2
(r"/header",index.HanderHander) , #响应头字段(Respose Headers)
(r"/status",index.StatuscodeHander), #状态码
tornado.web.url(r"/boy",index.BoyHandler,{"word3":"who","word4":"are you"},name="boy"), #反向解析
]
super().__init__(handlers,**setting)
#super()函数是用于调用父类(超类)的一个方法。
#Python3可以使用直接使用super().xxx代替super(Class, self).xxx:
#执行的是tornado.web.Application的init,再将handlers传参
#添加配置文件,参数里面加入**setting,(即**kwargs)
application中设置一个函数子类Application
存放路由
##简单的形式(r"/",index.IndexHandler)
##传参的形式(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),
对应的在index里面建立对应GoodHandler类后,
定义接收函数def initialize(self,str1,str2),然后在调用str1,str2
这里是服务器自己传参,如果要进行用户传参,则对应修改编辑方法
#views中的index
存放视图
##def initialize
接收传递过来的参数,并以 self.参数=参数 形式进行绑定
##self.write
将chunk(数据块)数据写到缓冲区
##刷新缓冲区
self.finish
刷新缓冲区,并关闭当前请求通道,即后面的数据不在传输
##缓冲区的内容输出到浏览器不用等待请求处理完成
self. flush()
self.write()会先把内容放在缓冲区,正常情况下,当请求处理完成的时候会自动把缓冲区的内容输出到浏览器,但是可以调用 self.flush()方法,这样可以直接把缓冲区的内容输出到浏览器,不用等待请求处理完成.
##序列化
json,jsonStr = json.dumps()
需要导入json库,对应的Handler中编写字典, jsonStr = json.dumps(per) 将字典转化为json的字符串
#(浏览器输出){"name": "nick", "age": 18, "height:": 170, "weight": 70}
但是你会发现,其实我们不需要这样写,直接用write也能转化。json还要进行下文的设置响应头
但是前者json转化的在谷歌浏览器F12中Network中json1文本中的Respose Headers里面,
Content Type 为 text/heml,而后者write转换后为appliction/json。
text/heml浏览器会将这个当成页面进行渲染,所以应为json类型
###在线解析json数据结构 ,https://c.runoob.com/front-end/53
##设置响应头
self.set_header(name,value)
self.set_header("Content-Type","applictions/json;charset=UTF-8")
self.set_header("good","boy") #自定义设置
作用:手动设置一个名为name值为value的响应头字段(Respose Headers)
参数:name:字段名称
value:字段值
###text/html和text/plain的区别
1、text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
2、text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理
##默认的headers
set_default_headers()
作用:
def set_default_headers(self):
在进入http响应方法之前被调用,可以重写该方法来预先设置默认的headers
这样类下面的各种方法都不用再去设置header了,默认为set_default_headers里面的
以后规范都在set_default_headers里面进行设置header
注意:
在http处理方法中(这里暂为get方法)使用set_header设置的子弹会覆盖set_default_headers里的默认设置字段
##设置状态码
self.set_status(status_code,reason=None)
作用:为响应设置状态码
self.set_status(404,"bad boy")
参数:status_code (状态码的值,int类型)
如果reason=None,则状态码必须为正常值,列如999
reason (描述状态码的词组,sting字符串类型)
##重定向
self.redirect()
重定向跳转到其他页面,比如self.redirect("/write")跳转到http://127.0.0.1:9000/wtite
##抛出HTTP错误状态码,默认为500, tornado会调用write_error()方法并处理
self.send_error(status_code=500,**kwargs)
抛出错误
##接收错误,并处理。所以说上面这两个必须连用。
self.write_error(status_code,**kwargs)
接收返回来的错误并处理错误
import tornado.web
from tornado.web import RequestHandler
import json
#------------------------------------------------
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
#-------------------------------
class WriteHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
self.write("good boy1")
self.write("good boy2")
self.write("good boy3")
self.finish() #刷新缓存区,并关闭请求通道,导致后面的good boy4无法传输
self.write("good boy4")
#---------------------------------------------------
class Json1Handler(RequestHandler):
def get(self, *args, **kwargs):
per = {
"name":"小白",
"gae":"22",
"height":170,
"weight":60,
}
jsonStr = json.dumps(per) #导入json库,将字典转化为json字符串
self.set_header("Content-Type", "applictions/json;charset=UTF-8")
self.write(jsonStr)
#----------------------------------------------------------------------
class Json2Handler(RequestHandler):
def get(self, *args, **kwargs):
per = {
"name":"小白",
"gae":"22",
"height":170,
"weight":60,
}
self.write(per)
#----------------------------------------------------------#------------
#预先设置报文头
class Headerhandler(RequestHandler):
def set_default_headers(self):
self.set_header("Content-Type", "applictions/json;charset=UTF-8") #预先设置报文头
def post(self, *args, **kwargs): #下面的就不必再次书写了
pass
def get(self, *args, **kwargs):
pass
#------------------------------------------------------
#设置状态码
class StatusHandler(RequestHandler):
def get(self, *args, **kwargs):
self.set_status(404,reason="Dont find!")
self.write("*****") #返回Status Code:404 Dont find!
#------------------------------------------------
#重定向
class RedirectHandler(RequestHandler):
def get(self,*args,**kwargs):
self.redirect("/write") #self.redirect重定向
#------------------------------------------------------
#自定义错误页面
访问http://127.0.0.1:9000/error?flag=0 进行测试
class ErrorHandler(RequestHandler):
def write_error(self, status_code, **kwargs):
if status_code==500:
code = 500
#返回500界面
self.write("服务器内部错误")
elif status_code==400:
code = 400
#返回404界面
self.write("预先设置错误")
self.set_status(code)
def get(self, *args, **kwargs):
flag = self.get_query_argument("flag")# 获取单个键值
#self.get_query_argument('a') # 如果同时传递多个a的参数,那么会采用后面覆盖前面的原则
if flag == "0":
self.send_error(500)
#注意在self.send_error(500)以下同级的内容不会继续执行,
self.write("right")
#-------------------------------------
#反向解析
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
# self.write("good boy") #响应http的请求
url = self.reverse_url("boy") #找到别名为boy的url
self.write("<a href='%s'>跳转到另一个页面</a>"%(url)) #点击a标签跳转到页面/boy
class BoyHandler(RequestHandler):
def initialize(self,word3,word4): #该方法会在http方法(这里为get方法)之前调用
self.word3=word3
self.word4= word4
def get(self, *args, **kwargs):
print(self.word3,self.word4)
self.write("good boy")
11.1 利用HTTP协议向服务器传递参数
1提取URI的特定部分
(r"/movies/(w+)/(w+)/(w+)",index.MoviesHandler) # w匹配包括下划线的任何单词字符 +只有一个 *零到多个
(r"/movies1/(?Pw+)/(?Pw+)/(?Pw+)",index.movies1Handler)
class MoviesHandler(RequestHandler):
def get(self, h1,h2,h3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
#application中
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
#(省略部分url)
(r"/movies/(w+)/(w+)/(w+)",index.MoviesHandler)
#//127.0.0.1:9000/movies/good/boy/job
# w匹配包括下划线的任何单词字符 +只有一个 *零到多个
(r"/movies1/(?P<p1>w+)/(?P<p2>w+)/(?P<p3>w+)",index.movies1Handler)
#//127.0.0.1:9000/movies/good/boy/job
]
#views/index中
from tornado.web import RequestHandler
class MoviesHandler(RequestHandler):
def get(self, h1,h2,h3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
print(h1 + "-"+h2+"_"+h3)
self.write("move go !")
#----------------------------------
class movies1Handler(RequestHandler):
def get(self, p1,p2,p3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
print(p1 + "-"+p2+"_"+p3)
self.write("move go to !")
访问http://127.0.0.1:9000/movies/good/boy/job
#(浏览器输出):move go!
#(pycharm输出):good-boy_job
#--------------------------------------------------
访问http://127.0.0.1:9000/movies1/good/boy/job 、
#(浏览器输出):move go to !
#(pycharm输出):good-boy_job
2get方式传递参数
路由比如(r"/movies2",index.Movies2Handler)
self.get_query_argument(name,default=ARG_DEFAULT(参数默认值),strip=True)#原型,这样去拿到参数a,b,c的值
self.get_query_arguments(name,strip=True)有重复的参数,参数原型
#127.0.0.1:8000/movies2?a=1&b=2&c=3第一种情况
#127.0.0.1:8000/movies2?a=1%20%20&b=2%20%20%20&c=3第二种情况
#127.0.0.1:8000/movies2?a=1&a=2&c=3第三种情况
#views/index中比如接收参数
class Movies2Handler(RequestHandler): #127.0.0.1:8000/movies2?a=1&b=2&c=3
def get(self, *args, **kwargs):
self.get_query_argument(name,default=ARG_DEFAULT(参数默认值),strip=True)#原型,这样去拿到参数a,b,c的值
#self.get_query_arguments(name, strip=True)有重复的参数,参数原型
参数:
name:
从get请求参数字符传中返回指定参数的值,如果出现多个同名参数,则返回最后一个的值
default:
设置未传的参数时),返回默认的值 ,比如这里传过来一个a(存在127.0.0.1:8000/movies2?a=1&b=2&c=3)没有任何赋值,而default=100,则默认a=100。
如果传过来没有的值,default也没有设置,比如d没有这样的值,会跑出一个错误:tor
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
