社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
导读:本项目是基于论文《语义分割全卷积网络的Tensorflow实现》的基础上实现的,该实现主要是基于论文作者给的参考代码。该模型应用于麻省理工学院(http://sceneparsing.csail.mit.edu/)提供的场景识别挑战数据集。
项目所需的七大条件
结果是在12GB TitanX上训练大约6~7小时后获得的。
该代码最初是用tensorflow0.11和python2.7编写和测试的。 tf.summary的调用已更新tensorflow 0.12版本。如果要使用旧版本的tensorflow,请使用另一分支tf.0.11_compatible(https://github.com/shekkizh/FCN.tensorflow/tree/tf.0.11_compatible)。
在使用tensorflow1.0和windows时会有一些问题。这些问题已经在issue#9(https://github.com/shekkizh/FCN.tensorflow/issues/9)中讨论过了。
训练模型只需执行python FCN.py
要可视化一个随机批次的图像的结果,zhi'yao'yo使用标志--mode=visualize
debug标志可以在训练期间设置,以添加关于激活函数,梯度,变量等的信息。
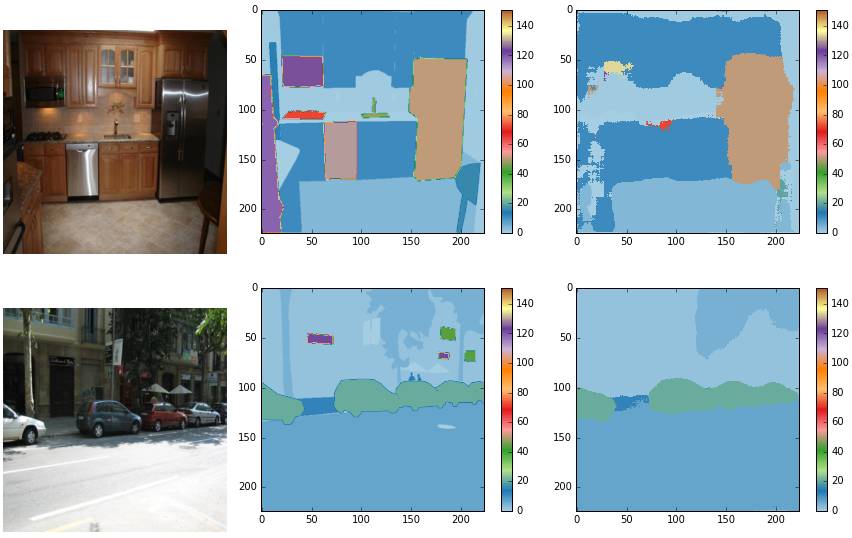
这个IPython笔记本(https://github.com/shekkizh/FCN.tensorflow/blob/master/logs/images/Image_Cmaped.ipynb)可以用于查看彩色结果,如下方图片所示。
实验结果:时间更短 效率更高
通过批次大小为2,缩放大小为256*256的图片训练模型得到以下结果。请注意,虽然训练图片是256*256,dan没有任何东西可以防止模型在任意大小的图像上工作。预测图像没有进行后处理。通过9轮训练 - 训练时间较短,这解释了为什么某些概念似乎在模型中能被语义理解,而另一些概念似乎没有。下面的结果来自验证数据集的随机图像。
网络设计和原论文在caffe中设置的几乎一样。添加的新层的权重用小值进行初始化,并使用Adam 优化器(学习率= 1e-4)进行学习。

数据观察
小批量是必要的,以适应内存大小,但这导致训练过程慢
有很多例子的概念似乎被正确识别和feng- 在上面的例子中可以看到,汽车和人被识别得更好。我相信这可以通过训练更长的时间来解决。
此外,图像大小调整会导致信息丢失 - 可以注意到,实际上较小的对象被分割的准确率较低。

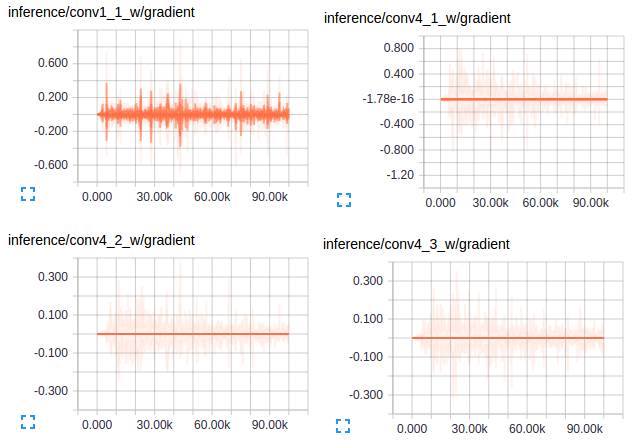
对于梯度:
如果仔细观察梯度,你会注意到初始训练几乎完全集中在添加的新层次上 - 只有在这些层被合理训练之后,我们才能看到VGG层获得一些梯度流。这是可以理解的,因为新层次在开始时更多地影响损失目标。
使用VGG权重初始化网络的前几层,因此在概念上讲这些层需要较少的调整,除非训练数据是非常多样的- 在这种情况下不是。
卷积模型的第一层捕获低级别的信息,并且由于这些信息依赖于数据集,你会注意到梯度tong'g调整第一层权重以使模型适应数据集。
来自VGG的其他卷积层具有非常小的梯度流动,因为这里捕获的概念对于我们的最终目标 - 分割是足够好的。
这是转移学习运作良好的核心原因。我只是想到在这里指出一下。
论文地址:https://arxiv.org/pdf/1605.06211v1.pdf
论文视频地址:http://techtalks.tv/talks/fully-convolutional-networks-for-semantic-segmentation/61606/
GitHub资源:https://github.com/shekkizh/FCN.tensorflow
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
