社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
transformer是一种不同于RNN的架构,模型同样包含 encoder 和 decoder ,但是encoder 和 decoder 抛弃 了RNN,而使用各种前馈层堆叠在一起。
Encoder:
编码器是由N个完全一样的层堆叠起来的,每层又包括两个子层(sub-layer),第一个子层是multi-head self-attention mechanism层,第二个子层是一个简单的多层全连接层(fully connected feed-forward network)
Decoder:
解码器也是由N 个相同层的堆叠起来的。 但每层包括三个子层(sub-layer),第一个子层是multi-head self-attention层,第二个子层是multi-head context-attention 层,第三个子层是一个简单的多层全连接层(fully connected feed-forward network)
模型的架构如下

一 module
(1)multi-head self-attention
multi-head self-attention是key=value=query=隐层的注意力机制
Encoder的multi-head self-attention是key=value=query=编码层隐层的注意力机制
Decoder的multi-head self-attention是key=value=query=解码层隐层的注意力机制
这里介绍自注意力机制(self-attention)也就是key=value=query=H的情况下的输出
隐层所有时间序列的状态H,hihi代表第i个词对应的隐藏层状态
H=⎡⎣⎢⎢⎢h1h2...hn⎤⎦⎥⎥⎥∈Rn×dimhi∈R1×dimH=[h1h2...hn]∈Rn×dimhi∈R1×dim
H的转置为
HT=[hT1,hT2,...,hTn]∈Rdim×nhi∈R1×dimHT=[h1T,h2T,...,hnT]∈Rdim×nhi∈R1×dim
如果只计算一个单词对应的隐层状态hihi的self-attention
weighthi=softmax((hiWiquery)∗(Wikey∗[hT1hT2...hTn]))=[weighti1,weighti2,...weightin]value=⎡⎣⎢⎢⎢h1h2...hn⎤⎦⎥⎥⎥∗Wivalue=⎡⎣⎢⎢⎢⎢h1Wivalueh2Wivalue...hnWivalue⎤⎦⎥⎥⎥⎥Attentionhi=weighthi∗value=∑k=1n(hkWivalue)(weightik)weighthi=softmax((hiWqueryi)∗(Wkeyi∗[h1Th2T...hnT]))=[weighti1,weighti2,...weightin]value=[h1h2...hn]∗Wvaluei=[h1Wvalueih2Wvaluei...hnWvaluei]Attentionhi=weighthi∗value=∑k=1n(hkWvaluei)(weightik)
同理,一次性计算所有单词隐层状态hi(1<=i<=n)hi(1<=i<=n)的self-attention
weight=softmax(⎡⎣⎢⎢⎢h1h2...hn⎤⎦⎥⎥⎥Wiquery∗(Wikey∗[hT1hT2...hTn])=softmax(⎡⎣⎢⎢⎢⎢h1Wiqueryh2Wiquery...hnWiquery⎤⎦⎥⎥⎥⎥∗[WikeyhT1WikeyhT2...WikeyhTn]=softmax(⎡⎣⎢⎢⎢⎢⎢(h1Wiquery)(WikeyhT1)(h2Wiquery)(WikeyhT1)...(hnWiquery)(WikeyhT1)(h1Wiquery)(WikeyhT2)(h2Wiquery)(WikeyhT2)...(hnWiquery)(WikeyhT2)............(h1Wiquery)(WikeyhTn)(h2Wiquery)(WikeyhTn)...(hnWiquery)(WikeyhTn)⎤⎦⎥⎥⎥⎥⎥)=⎡⎣⎢⎢⎢⎢⎢softmax((h1WiqueryWikeyhT1)softmax((h2WiqueryWikeyhT1)...softmax((hnWiqueryWikeyhT1)(h1WiqueryWikeyhT2)(h2WiqueryWikeyhT2)...(hnWiqueryWikeyhT2)............(h1WiqueryWikeyhTn))(h2WiqueryWikeyhTn))...(hnWiqueryWikeyhTn))⎤⎦⎥⎥⎥⎥⎥weight=softmax([h1h2...hn]Wqueryi∗(Wkeyi∗[h1Th2T...hnT])=softmax([h1Wqueryih2Wqueryi...hnWqueryi]∗[Wkeyih1TWkeyih2T...WkeyihnT]=softmax([(h1Wqueryi)(Wkeyih1T)(h1Wqueryi)(Wkeyih2T)...(h1Wqueryi)(WkeyihnT)(h2Wqueryi)(Wkeyih1T)(h2Wqueryi)(Wkeyih2T)...(h2Wqueryi)(WkeyihnT)............(hnWqueryi)(Wkeyih1T)(hnWqueryi)(Wkeyih2T)...(hnWqueryi)(WkeyihnT)])=[softmax((h1WqueryiWkeyih1T)(h1WqueryiWkeyih2T)...(h1WqueryiWkeyihnT))softmax((h2WqueryiWkeyih1T)(h2WqueryiWkeyih2T)...(h2WqueryiWkeyihnT))............softmax((hnWqueryiWkeyih1T)(hnWqueryiWkeyih2T)...(hnWqueryiWkeyihnT))]
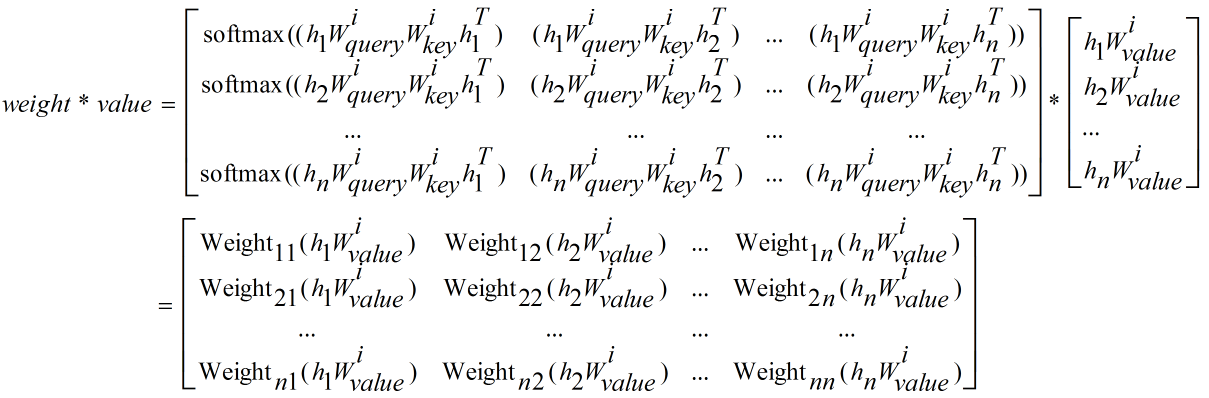
sum(weight∗value)=⎡⎣⎢⎢⎢⎢Weight11(h1Wivalue)+Weight12(h2Wivalue)+...+Weight1n(hnWivalue)Weight21(h1Wivalue)+Weight22(h2Wivalue)+...+Weight2n(hnWivalue)......Weightn1(h1Wivalue)+Weightn2(h2Wivalue)+...+Weightnn(hnWivalue)⎤⎦⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∑k=1nWeight1k(hkWivalue)∑k=1nWeight2k(hkWivalue).......∑k=1nWeightnk(hkWivalue)⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥sum(weight∗value)=[Weight11(h1Wvaluei)+Weight12(h2Wvaluei)+...+Weight1n(hnWvaluei)Weight21(h1Wvaluei)+Weight22(h2Wvaluei)+...+Weight2n(hnWvaluei)......Weightn1(h1Wvaluei)+Weightn2(h2Wvaluei)+...+Weightnn(hnWvaluei)]=[∑k=1nWeight1k(hkWvaluei)∑k=1nWeight2k(hkWvaluei).......∑k=1nWeightnk(hkWvaluei)]
所以最后的注意力向量为headiheadi
headi=Attention(QWiquery,KWiquery,VWiquery)=sum(weight∗value)=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∑k=1nWeight1k(hkWivalue)∑k=1nWeight2k(hkWivalue).......∑k=1nWeightnk(hkWivalue)⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥headi=Attention(QWqueryi,KWqueryi,VWqueryi)=sum(weight∗value)=[∑k=1nWeight1k(hkWvaluei)∑k=1nWeight2k(hkWvaluei).......∑k=1nWeightnk(hkWvaluei)]
softmax函数需要加一个平滑系数dk−−√dk
headi=Attention(QWiquery,KWikey,VWivalue)=softmax((QWiquery)(KWikey)Tdk√)VWivalue=softmax(⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢(h1Wiquery)(WikeyhT1)dk√(h2Wiquery)(WikeyhT1)dk√...(hnWiquery)(WikeyhT1)dk√(h1Wiquery)(WikeyhT2)dk√(h2Wiquery)(WikeyhT2)dk√...(hnWiquery)(WikeyhT2)dk√............(h1Wiquery)(WikeyhTn)dk√(h2Wiquery)(WikeyhTn)dk√...(hnWiquery)(WikeyhTn)dk√⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥)VWivalue=sum(weightdk√∗value)headi=Attention(QWqueryi,KWkeyi,VWvaluei)=softmax((QWqueryi)(KWkeyi)Tdk)VWvaluei=softmax([(h1Wqueryi)(Wkeyih1T)dk(h1Wqueryi)(Wkeyih2T)dk...(h1Wqueryi)(WkeyihnT)dk(h2Wqueryi)(Wkeyih1T)dk(h2Wqueryi)(Wkeyih2T)dk...(h2Wqueryi)(WkeyihnT)dk............(hnWqueryi)(Wkeyih1T)dk(hnWqueryi)(Wkeyih2T)dk...(hnWqueryi)(WkeyihnT)dk])VWvaluei=sum(weightdk∗value)
注意d−−√kdk 是softmax中的temperature参数:
pi=elogitsiτ∑ielogitsiτipi=elogitsiτ∑ieilogitsiτ
t越大,则经过softmax的得到的概率值之间越接近。t越小,则经过softmax得到的概率值之间越差异越大。当t趋近于0的时候,只有最大的一项是1,其他均几乎为0:
limτ→0pi→1ifpi=max(pk)1≤k≤Nelse0limτ→0pi→1ifpi=max(pk)1≤k≤Nelse0
MultiHead注意力向量由多个headiheadi拼接后过一个线性层得到最终的MultiHead Attention
MulitiHead=Concat(head1,head2,...,headn)Wowhereheadi=Attention(QWiquery,KWikey,VWivalue)=softmax((QWiquery)(KWikey)Tdk√)VWivalueMulitiHead=Concat(head1,head2,...,headn)Wowhereheadi=Attention(QWqueryi,KWkeyi,VWvaluei)=softmax((QWqueryi)(KWkeyi)Tdk)VWvaluei
(2)LayerNorm+Position-wise Feed-Forward Networks
FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW1+b1)W2+b2
注意这里实现上和论文中有点区别,具体实现是先LayerNorm然后再FFN

class PositionwiseFeedForward(nn.Module):
""" A two-layer Feed-Forward-Network with residual layer norm.
Args:
d_model (int): the size of input for the first-layer of the FFN.
d_ff (int): the hidden layer size of the second-layer
of the FNN.
dropout (float): dropout probability(0-1.0).
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.layer_norm = onmt.modules.LayerNorm(d_model)
self.dropout_1 = nn.Dropout(dropout)
self.relu = nn.ReLU()
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x):
"""
Layer definition.
Args:
input: [ batch_size, input_len, model_dim ]
Returns:
output: [ batch_size, input_len, model_dim ]
"""
inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))
output = self.dropout_2(self.w_2(inter))
return output + x
(3)Layer Normalization
x=[x1x2...xn]x=[x1x2...xn]
x1,x2,x3,...,xnx1,x2,x3,...,xn为样本xx的不同特征
x^i=xi−E(x)Var(x)−−−−−−√x^i=xi−E(x)Var(x)
x^=[x^1x^2...x^n]x^=[x^1x^2...x^n]
最终x^x^为layer normalization的输出,并且x^x^均值为0,方差为1:
E(x^)=1n∑i=1nx^i=1n∑i=1nxi−E(x)Var(x)√=1n[(x1+x2+...+xn)−nE(x)]Var(x)√=0Var(x^)=1n−1∑i=1n(x^−E(x^))2=1n−1∑i=1nx^2=1n−1∑i=1n(xi−E(x))2Var(x)=1n−1∑i=1n(xi−E(x))2Var(x)=Var(x)Var(x)=1E(x^)=1n∑i=1nx^i=1n∑i=1nxi−E(x)Var(x)=1n[(x1+x2+...+xn)−nE(x)]Var(x)=0Var(x^)=1n−1∑i=1n(x^−E(x^))2=1n−1∑i=1nx^2=1n−1∑i=1n(xi−E(x))2Var(x)=1n−1∑i=1n(xi−E(x))2Var(x)=Var(x)Var(x)=1
但是通常引入两个超参数w和bias, w和bias通过反向传递更新,但是初始值winitial=1,biasbias=0winitial=1,biasbias=0,εε防止分母为0:
x^i=w∗xi−E(x)Var(x)+ε−−−−−−−−−√+biasx^i=w∗xi−E(x)Var(x)+ε+bias
伪代码如下:
class LayerNorm(nn.Module):
"""
Layer Normalization class
"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"""
x=[-0.0101, 1.4038, -0.0116, 1.4277],
[ 1.2195, 0.7676, 0.0129, 1.4265]
"""
mean = x.mean(-1, keepdim=True)
"""
mean=[[ 0.7025],
[ 0.8566]]
"""
std = x.std(-1, keepdim=True)
"""
std=[[0.8237],
[0.6262]]
"""
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
"""
self.a_2=[1,1,1,1]
self.b_2=[0,0,0,0]
return [[-0.8651, 0.8515, -0.8668, 0.8804],
[ 0.5795, -0.1422, -1.3475, 0.9101]]
"""
(4)Embedding
位置向量 Position Embedding
PEpos,2i=sin(pos100002idmodel)=sin(pos∗div_term)PEpos,2i+1=cos(pos100002idmodel)=cos(pos∗div_term)div_term=elog(1100002idmodel)=e−2idmodellog(10000)=e2i∗(−log(10000)dmodel)PEpos,2i=sin(pos100002idmodel)=sin(pos∗div_term)PEpos,2i+1=cos(pos100002idmodel)=cos(pos∗div_term)div_term=elog(1100002idmodel)=e−2idmodellog(10000)=e2i∗(−log(10000)dmodel)
计算Position Embedding举例:
输入句子S=[w1,w2,...,wmax_len]S=[w1,w2,...,wmax_len], m为句子长度 ,假设max_len=3,且dmodel=4dmodel=4:
pe = torch.zeros(max_len, dim)
position = torch.arange(0, max_len).unsqueeze(1)
#position=[0,1,2] position.shape=(3,1)
div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim)))
"""
torch.arange(0, dim, 2, dtype=torch.float)=[0,2,4] shape=(3)
-(math.log(10000.0) / dim)=-1.5350567286626973
(torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim))=[0,2,4]*-1.5350567286626973=[-0.0000, -3.0701, -6.1402]
div_term=exp([-0.0000, -3.0701, -6.1402])=[1.0000, 0.0464, 0.0022]
"""
pe[:, 0::2] = torch.sin(position.float() * div_term)
"""
pe=[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.8415, 0.0000, 0.0464, 0.0000, 0.0022, 0.0000],
[ 0.9093, 0.0000, 0.0927, 0.0000, 0.0043, 0.0000]]
"""
pe[:, 1::2] = torch.cos(position.float() * div_term)
"""
pe=[[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0464, 0.9989, 0.0022, 1.0000],
[ 0.9093, -0.4161, 0.0927, 0.9957, 0.0043, 1.0000]]
"""
pe = pe.unsqueeze(1)
#pe.shape=[3,1,6]
max_len=20,dmodel=4dmodel=4Position Embedding,可以观察到同一个时间序列内t位置内大约只有前半部分起到区分位置的作用:
语义向量normal Embedding:
x=[x1,x2,x3,...,xn]x=[x1,x2,x3,...,xn],xixi为one-hot行向量
那么,代表语义的embedding是emb=[emb1,emb2,emb3,...,embnemb=[emb1,emb2,emb3,...,embn embi=xiWembi=xiW,transformer中的词向量表示为语义向量emb_{i}和位置向量pe_{i}之和
embfinali=embi+peiembifinal=embi+pei
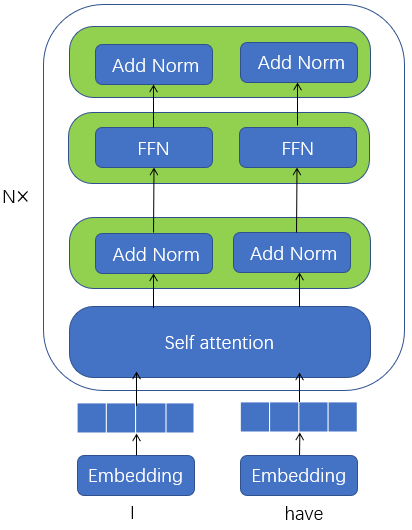
二 Encoder
(1)Encoder是由多个相同的层堆叠在一起的:[input→embedding→self−attention→AddNorm→FFN→AddNorm][input→embedding→self−attention→AddNorm→FFN→AddNorm]:
(2)Encoder的self-attention是既考虑前面的词也考虑后面的词的,而Decoder的self-attention只考虑前面的词,因此mask矩阵是全1。因此encoder的self-attention如下图:
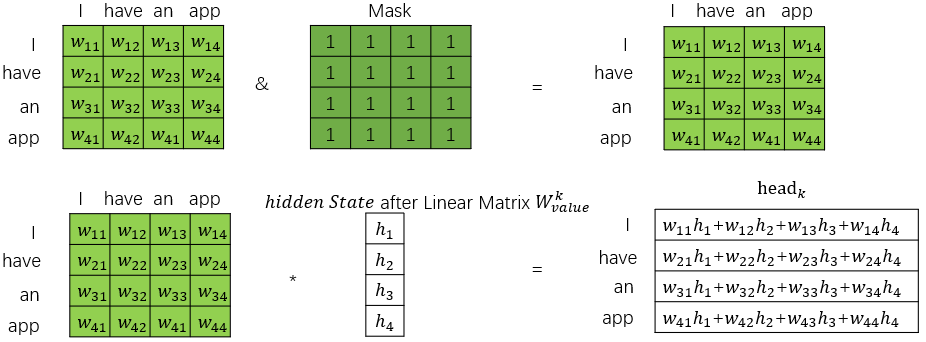
伪代码如下:
class TransformerEncoderLayer(nn.Module):
"""
A single layer of the transformer encoder.
Args:
d_model (int): the dimension of keys/values/queries in
MultiHeadedAttention, also the input size of
the first-layer of the PositionwiseFeedForward.
heads (int): the number of head for MultiHeadedAttention.
d_ff (int): the second-layer of the PositionwiseFeedForward.
dropout (float): dropout probability(0-1.0).
"""
def __init__(self, d_model, heads, d_ff, dropout):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = onmt.modules.MultiHeadedAttention(
heads, d_model, dropout=dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm = onmt.modules.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, inputs, mask):
"""
Transformer Encoder Layer definition.
Args:
inputs (`FloatTensor`): `[batch_size x src_len x model_dim]`
mask (`LongTensor`): `[batch_size x src_len x src_len]`
Returns:
(`FloatTensor`):
* outputs `[batch_size x src_len x model_dim]`
"""
input_norm = self.layer_norm(inputs)
context, _ = self.self_attn(input_norm, input_norm, input_norm,
mask=mask)
out = self.dropout(context) + inputs
return self.feed_forward(out)
二 Decoder
(1)decoder中的self attention层在计算self attention的时候,因为实际预测中只能知道前面的词,因此在训练过程中只需要计算当前位置和前面位置的self attention,通过掩码来计算Masked Multi-head Attention层。
例如"I have an app",中翻译出第一个词后"I",
"I"的self attention只计算与"I"与自己的self attention: Attention("I","I"),来预测下一个词
翻译出"I have"后,计算"have"与"have","have"与"I"的self attention: Attention("have","I"), Attention("have","have"),来预测下一个词
翻译出"I have an"后,计算"an"与"an","an"与"have","an"与"I"的self attention: Attention("an","an"), Attention("an","have"),Attention("an","I")来预测下一个词
可以用下图来表示:
self-attention的伪代码如下:
class MultiHeadedAttention(nn.Module):
"""
Args:
head_count (int): number of parallel heads
model_dim (int): the dimension of keys/values/queries,
must be divisible by head_count
dropout (float): dropout parameter
"""
def __init__(self, head_count, model_dim, dropout=0.1):
assert model_dim % head_count == 0
self.dim_per_head = model_dim // head_count
self.model_dim = model_dim
super(MultiHeadedAttention, self).__init__()
self.head_count = head_count
self.linear_keys = nn.Linear(model_dim,model_dim)
self.linear_values = nn.Linear(model_dim,model_dim)
self.linear_query = nn.Linear(model_dim,model_dim)
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
self.final_linear = nn.Linear(model_dim, model_dim)
def forward(self, key, value, query, mask=None,
layer_cache=None, type=None):
"""
Compute the context vector and the attention vectors.
Args:
key (`FloatTensor`): set of `key_len`
key vectors `[batch, key_len, dim]`
value (`FloatTensor`): set of `key_len`
value vectors `[batch, key_len, dim]`
query (`FloatTensor`): set of `query_len`
query vectors `[batch, query_len, dim]`
mask: binary mask indicating which keys have
non-zero attention `[batch, query_len, key_len]`
Returns:
(`FloatTensor`, `FloatTensor`) :
* output context vectors `[batch, query_len, dim]`
* one of the attention vectors `[batch, query_len, key_len]`
"""
batch_size = key.size(0)
dim_per_head = self.dim_per_head
head_count = self.head_count
key_len = key.size(1)
query_len = query.size(1)
def shape(x):
""" projection """
return x.view(batch_size, -1, head_count, dim_per_head)
.transpose(1, 2)
def unshape(x):
""" compute context """
return x.transpose(1, 2).contiguous()
.view(batch_size, -1, head_count * dim_per_head)
# 1) Project key, value, and query.
if layer_cache is not None:
key = self.linear_keys(key)
#key.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim]
value = self.linear_values(value)
#value.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim]
query = self.linear_query(query)
#query.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim]
key = shape(key)
#key.shape=[batch_size,head_count,key_len,dim_per_head]
value = shape(value)
#value.shape=[batch_size,head_count,value_len,dim_per_head]
query = shape(query)
#query.shape=[batch_size,head_count,query_len,dim_per_head]
key_len = key.size(2)
query_len = query.size(2)
# 2) Calculate and scale scores.
query = query / math.sqrt(dim_per_head)
scores = torch.matmul(query, key.transpose(2, 3))
#query.shape=[batch_size,head_count,query_len,dim_per_head]
#key.transpose(2, 3).shape=[batch_size,head_count,dim_per_head,key_len]
#scores.shape=[batch_size,head_count,query_len,key_len]
if mask is not None:
mask = mask.unsqueeze(1).expand_as(scores)
scores = scores.masked_fill(mask, -1e18)
# 3) Apply attention dropout and compute context vectors.
attn = self.softmax(scores)
#scores.shape=[batch_size,head_count,query_len,key_len]
drop_attn = self.dropout(attn)
context = unshape(torch.matmul(drop_attn, value))
#drop_attn.shape=[batch_size,head_count,query_len,key_len]
#value.shape=[batch_size,head_count,value_len,dim_per_head]
#torch.matmul(drop_attn, value).shape=[batch_size,head_count,query_len,dim_per_head]
#context.shape=[batch_size,query_len,head_count*dim_per_head]
output = self.final_linear(context)
#context.shape=[batch_size,query_len,head_count*dim_per_head]
return output
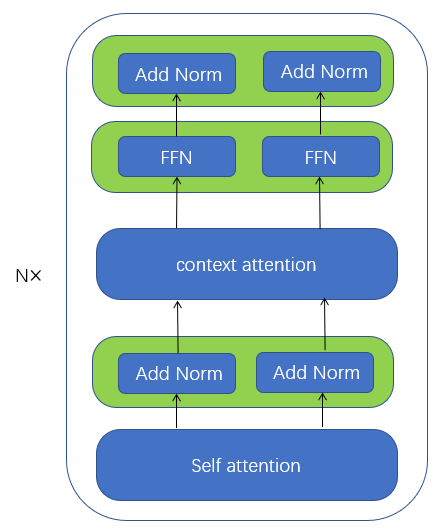
(2)Decoder的结构为[input→embedding→self−attention→AddNorm→context−attention→FFN→AddNorm][input→embedding→self−attention→AddNorm→context−attention→FFN→AddNorm]:
class TransformerDecoderLayer(nn.Module):
"""
Args:
d_model (int): the dimension of keys/values/queries in
MultiHeadedAttention, also the input size of
the first-layer of the PositionwiseFeedForward.
heads (int): the number of heads for MultiHeadedAttention.
d_ff (int): the second-layer of the PositionwiseFeedForward.
dropout (float): dropout probability(0-1.0).
self_attn_type (string): type of self-attention scaled-dot, average
"""
def __init__(self, d_model, heads, d_ff, dropout,
self_attn_type="scaled-dot"):
super(TransformerDecoderLayer, self).__init__()
self.self_attn_type = self_attn_type
if self_attn_type == "scaled-dot":
self.self_attn = onmt.modules.MultiHeadedAttention(
heads, d_model, dropout=dropout)
elif self_attn_type == "average":
self.self_attn = onmt.modules.AverageAttention(
d_model, dropout=dropout)
self.context_attn = onmt.modules.MultiHeadedAttention(
heads, d_model, dropout=dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm_1 = onmt.modules.LayerNorm(d_model)
self.layer_norm_2 = onmt.modules.LayerNorm(d_model)
self.dropout = dropout
self.drop = nn.Dropout(dropout)
mask = self._get_attn_subsequent_mask(MAX_SIZE)
# Register self.mask as a buffer in TransformerDecoderLayer, so
# it gets TransformerDecoderLayer's cuda behavior automatically.
self.register_buffer('mask', mask)
def forward(self, inputs, memory_bank, src_pad_mask, tgt_pad_mask,
previous_input=None, layer_cache=None, step=None):
"""
Args:
inputs (`FloatTensor`): `[batch_size x 1 x model_dim]`
memory_bank (`FloatTensor`): `[batch_size x src_len x model_dim]`
src_pad_mask (`LongTensor`): `[batch_size x 1 x src_len]`
tgt_pad_mask (`LongTensor`): `[batch_size x 1 x 1]`
Returns:
(`FloatTensor`, `FloatTensor`, `FloatTensor`):
* output `[batch_size x 1 x model_dim]`
* attn `[batch_size x 1 x src_len]`
* all_input `[batch_size x current_step x model_dim]`
"""
dec_mask = torch.gt(tgt_pad_mask +
self.mask[:, :tgt_pad_mask.size(1),
:tgt_pad_mask.size(1)], 0)
input_norm = self.layer_norm_1(inputs)
all_input = input_norm
if previous_input is not None:
all_input = torch.cat((previous_input, input_norm), dim=1)
dec_mask = None
if self.self_attn_type == "scaled-dot":
query, attn = self.self_attn(all_input, all_input, input_norm,
mask=dec_mask,
layer_cache=layer_cache,
type="self")
elif self.self_attn_type == "average":
query, attn = self.self_attn(input_norm, mask=dec_mask,
layer_cache=layer_cache, step=step)
query = self.drop(query) + inputs
query_norm = self.layer_norm_2(query)
mid, attn = self.context_attn(memory_bank, memory_bank, query_norm,
mask=src_pad_mask,
layer_cache=layer_cache,
type="context")
output = self.feed_forward(self.drop(mid) + query)
return output, attn, all_input
五 label smoothing (标签平滑)
普通的交叉熵损失函数:
loss=−∑k=1Ktrueklog(p(k|x))p(k|x)=softmax(logitsk)logitsk=∑iwikziloss=−∑k=1Ktrueklog(p(k|x))p(k|x)=softmax(logitsk)logitsk=∑iwikzi
梯度为:
Δwik=∂loss∂wik=∂loss∂logitsik∂logits∂wik=(yk−labelk)zklabel=[α4α41−αα4α4]Δwik=∂loss∂wik=∂loss∂logitsik∂logits∂wik=(yk−labelk)zklabel=[α4α41−αα4α4]
有一个问题
只有正确的那一个类别有贡献,其他标注数据中不正确的类别概率是0,无贡献,朝一个方向优化,容易导致过拟合
因此提出label smoothing 让标注数据中正确的类别概率小于1,其他不正确类别的概率大于0:
也就是之前label=[0,0,0,1,0]label=[0,0,0,1,0],通过标签平滑,给定一个固定参数αα, 概率为1地方减去这个小概率,标签为0的地方平分这个小概率αα变成:
labelnew=[α4α41−αα4α4]labelnew=[α4α41−αα4α4]
损失函数为
loss=−∑k=1Klabelnewklogp(k|x)labelnewk=(1−α)δk,y+αK(δk,y=1ifk==yelse0)loss=−(1−α)∑k=1Klabellogp(k|x)−αK∑k=1K(αK)logp(k|x)loss=(1−α)CrossEntropy(label,p(k|x))+αKCrossEntropy(αK,p(k|x))loss=−∑k=1Klabelknewlogp(k|x)labelknew=(1−α)δk,y+αK(δk,y=1ifk==yelse0)loss=−(1−α)∑k=1Klabellogp(k|x)−αK∑k=1K(αK)logp(k|x)loss=(1−α)CrossEntropy(label,p(k|x))+αKCrossEntropy(αK,p(k|x))
引入相对熵函数:
DKL(Y||X)=∑iY(i)log(Y(i)X(i))=∑iY(i)logY(i)−Y(i)logX(i)DKL(Y||X)=∑iY(i)log(Y(i)X(i))=∑iY(i)logY(i)−Y(i)logX(i)
pytorch中的torch.nn.function.kl_div用来计算相对熵:
torch.nn.function.kl_div(y,x):x=[x1,x2,...,xN]y=[y1,y2,...,yN]x=[x1,x2,...,xN]y=[y1,y2,...,yN]:
L=l1+l2+...+lN其中li=xi∗(log(xi)−yi)L=l1+l2+...+lN其中li=xi∗(log(xi)−yi)
举例:x=[3] y=[2] torch.nn.function.kl_div(y,x)=3(log3-2)=-2.7042
class LabelSmoothingLoss(nn.Module):
"""
With label smoothing,
KL-divergence between q_{smoothed ground truth prob.}(w)
and p_{prob. computed by model}(w) is minimized.
"""
def __init__(self, label_smoothing, tgt_vocab_size, ignore_index=-100):
assert 0.0 < label_smoothing <= 1.0
self.padding_idx = ignore_index
super(LabelSmoothingLoss, self).__init__()
smoothing_value = label_smoothing / (tgt_vocab_size - 2)
one_hot = torch.full((tgt_vocab_size,), smoothing_value)
one_hot[self.padding_idx] = 0
self.register_buffer('one_hot', one_hot.unsqueeze(0))
self.confidence = 1.0 - label_smoothing
def forward(self, output, target):
"""
output (FloatTensor): batch_size x n_classes
target (LongTensor): batch_size
"""
model_prob = self.one_hot.repeat(target.size(0), 1)
model_prob.scatter_(1, target.unsqueeze(1), self.confidence)
model_prob.masked_fill_((target == self.padding_idx).unsqueeze(1), 0)
return F.kl_div(output, model_prob, size_average=False)
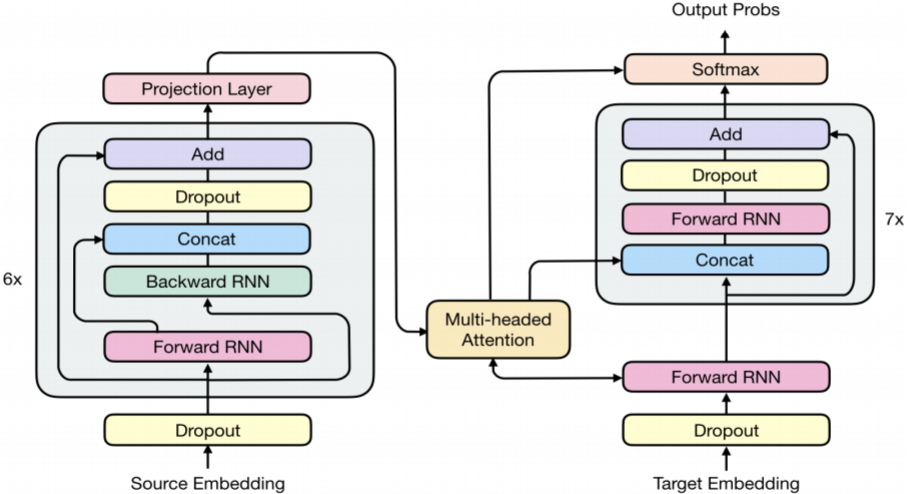
附: Transformer与RNN的结合RNMT+(The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation)
(1)RNN:难以训练并且表达能力较弱 trainability versus expressivity
(2)Transformer:有很强的特征提取能力(a strong feature extractor),但是没有memory机制,因此需要额外引入位置向量。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
