社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬取妹子网的低级教程连接如下:[爬妹子网](https://blog.csdn.net/baidu_35085676/article/details/68958267)
ps:只支持单个套图下载,不支持整体下载
在说说我的这个爬虫代码的设计思路:
①当我们浏览这个网站时,会发现,每一个页面的URL都是以网站的域名+page+页数组成,这样我们就可以逐一的访问该网站的网页了
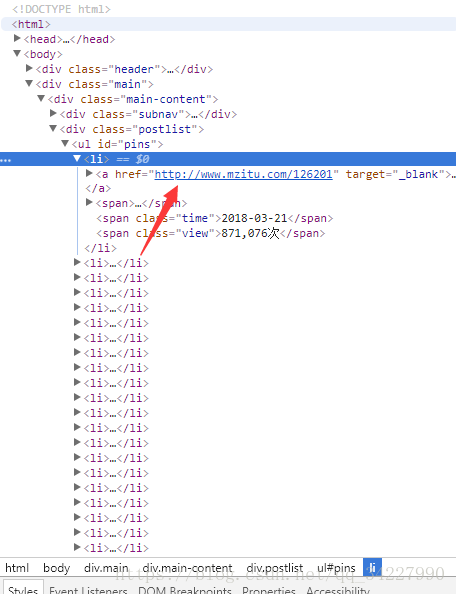
②当我们看图片列表时中,把鼠标放到图片,右击检查,我们发现,图片的内容由ul包裹的li组成,箭头所指的地方为每个套图的地址,这样我们就可以进入套图,一个这样的页面包含有24个这样的套图,我们用BeautifulSoup,处理。
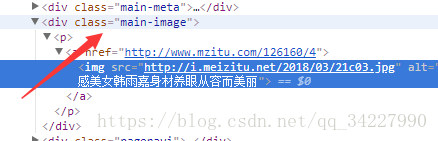
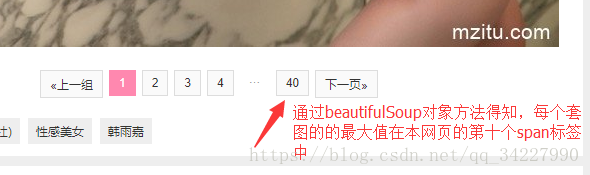
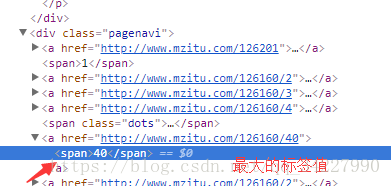
③我们进入套图,鼠标放到40处,右击,发现该套图图片的最大图片数为第十个span的值,而且每个套图的url同①原理相同为套图的url+第几张图片(如下图3为第二张图片),最后下载的url由一个class为main-titleDIV组成。提取img标签的src属性即
可获得下载链接
from bs4 import BeautifulSoup
import requests
import os
base_url='http://www.mzitu.com/page/'
#反‘反盗链’
header = { 'Referer':'http://www.mzitu.com'}
for x in range(11,20):
#盗取第十一页到19页图片
html_a=requests.get(base_url+str(x),headers=header)
soup_a=BeautifulSoup(html_a.text,features='lxml')
#解析第一个网页
pages=soup_a.find('ul',{'id':'pins'}).find_all('a')
#选出a标签,如第二步的箭头所指的地方
b=1
for y in pages:
if(b%2!=0):
#因为一个li标签里面有两个a标签,所以要去除重复
html=requests.get(y['href'],headers=header)
soup_b=BeautifulSoup(html.text,features='lxml')
#进入套图,解析套图
pic_max=soup_b.find_all('span')[10].text
#选出该套图的最大图片数
tittle=soup_b.find('h2',{'class':'main-title'}).text
os.makedirs('./img/'+str(tittle))
#制造一个目录
for i in range(1,int(pic_max)+1):
#循环,下载套图图片,
href=y['href']+'/'+str(i)
html2=requests.get(href,headers=header)
soup2=BeautifulSoup(html2.text,features='lxml')
pic_url=soup2.find('img',alt=tittle)
html_name=requests.get(pic_url['src'],headers=header,stream=True)
file_name=pic_url['src'].split(r'/')[-1]
with open('./img/'+str(tittle)+'/'+file_name,'wb') as f:
#按32字节下载
for x in html_name.iter_content(chunk_size=32):
f.write(x)
b=b+1
print('ok')#判断程序是否结束
from bs4 import BeautifulSoup
import requests
import os
import re
base_url='
header = { 'Referer':'http://www.mzitu.com'}
for x in range(61,62):
html_a=requests.get(base_url+str(x),headers=header)
soup_a=BeautifulSoup(html_a.text,features='lxml')
pages=soup_a.find('ul',{'id':'pins'}).find_all('a')
test=re.findall('"href":"(.*?)"',pages)
print(test)
b=1
for y in pages:
if(b%2!=0):
html=requests.get(y['href'],headers=header)
soup_b=BeautifulSoup(html.text,features='lxml')
pic_max=soup_b.find_all('span')[10].text
tittle=soup_b.find('h2',{'class':'main-title'}).text
u=str(tittle).replace(':','').replace('!','').replace('?','').replace(',','').replace(' ','')
os.makedirs('./img/'+u)
for i in range(1,int(pic_max)+1):
href=y['href']+'/'+str(i)
html2=requests.get(href,headers=header)
soup2=BeautifulSoup(html2.text,features='lxml')
pic_url=soup2.find('img',alt=tittle)
html_name=requests.get(pic_url['src'],headers=header,stream=True)
file_name=pic_url['src'].split(r'/')[-1]
with open('./img/'+u+'/'+file_name,'wb') as f:
for x in html_name.iter_content(chunk_size=32):
f.write(x)
b=b+1
print('ok')
以上代码为原创代码,
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!