社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
目录
2019-nCoV新型冠状病毒引发的肺炎牵动全国人民的心,无数无畏的英雄儿女逆行而上奔赴前线,本人晚上刷手机刷这刷着觉得也要像那些医务人员一样勇敢,为疫情做点什么,于是有了这次2019-nCoV项目,本项目包括如下三部分
第二部分 地理可视化
第三部分 病例数据规律探索
很多大型门户网站和手机应用都开设了专门的疫情实时追踪数据网站和功能,比较友好的有腾讯新闻,网易新闻,新浪新闻,三者网页感官大体差不多,有疫情最新总数,疫情地图,疫情病例曲线等,数据来源于国家及各地卫生健康委员会每日发布的信息,今天我们就以腾讯新闻为例来获取疫情实时数据。
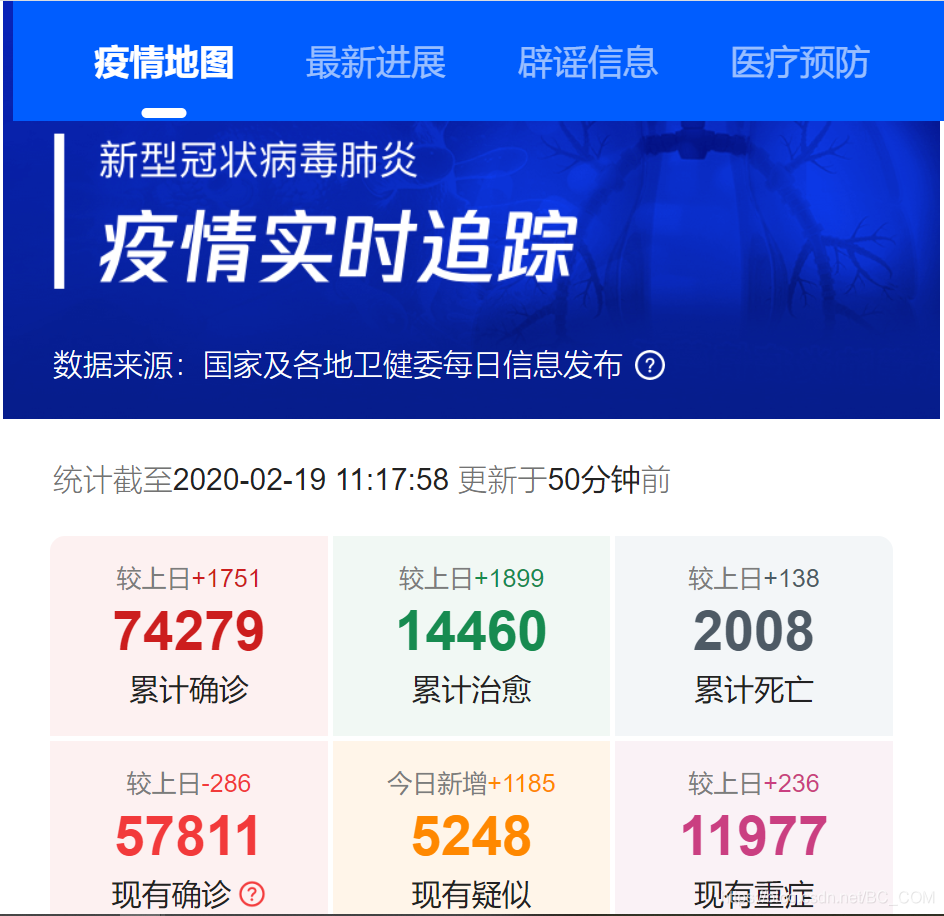
具体操作
1,打开目标网站
2,按住F12,进入开发者模式,再按Ctrl+R刷新
3,在NetWork下找到getOnsInfo?name=disease_h5列

4, 双击该条目,跳转到一个类似于https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery34106817348088859214_1580806762734&_=1580806762735网站,发现里面网站都是非常工整的json格式数据,即我们想要获取的疫情数据,但是我们请求的url为https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5即可,因为后面callback参数只是记录你访问的一个标识。
疫情数据找到了,接下来就是通过requests模块访问并获取并加以整理数据的事情了。
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 18 19:18:22 2020
project name:2019-nCoV
@author: berlin
"""
import json, csv, requests #导入请求模块
def get_data(): #定义获取数据并写入csv文件里的函数
url = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5" #请求网址
response=requests.get(url).json() #发出请求并json化处理
#print(response) #测试一下是否获取数据了
data = json.loads(response['data']) #提取数据部分
#print(data.keys()) #获取数据组成部分['chinaTotal', 'chinaAdd', 'lastUpdateTime', 'areaTree', 'chinaDayList', 'chinaDayAddList']
update_time=data["lastUpdateTime"]
chinaDayList=data["chinaDayList"] #历史数据
with open("./data/每日病例.csv","w+",newline="") as csv_file:
writer=csv.writer(csv_file)
header=["date","confirm","suspect","dead","heal", "update_time"] #定义表头
writer.writerow(header)
for i in range(len(chinaDayList)):
data_row1=[chinaDayList[i]["date"],chinaDayList[i]["confirm"],chinaDayList[i]["suspect"],chinaDayList[i]["dead"],chinaDayList[i]["heal"], update_time]
writer.writerow(data_row1)
chinaDayAddList=data["chinaDayAddList"] #历史新增数据
with open("./data/每日新增病例.csv","w+",newline="") as csv_file:
writer=csv.writer(csv_file)
header=["date","confirm","suspect","dead","heal","update_time"] #定义表头
writer.writerow(header)
for i in range(len(chinaDayAddList)):
data_row2=[chinaDayAddList[i]["date"],chinaDayAddList[i]["confirm"],chinaDayAddList[i]["suspect"],chinaDayAddList[i]["dead"],chinaDayAddList[i]["heal"], update_time]
writer.writerow(data_row2)
areaTree=data["areaTree"] #各地方数据
with open("./data/全国各城市病例数据.csv","w+",newline="") as csv_file:
writer=csv.writer(csv_file)
header=["province", "city_name", "total_confirm", "total_suspect", "total_dead", "total_heal", "today_confirm", "today_suspect", "today_dead", "today_heal","update_time"]
writer.writerow(header)
china_data=areaTree[0]["children"] #中国数据
for j in range(len(china_data)):
province=china_data[j]["name"] #省份
city_list=china_data[j]["children"] #该省份下面城市列表
for k in range(len(city_list)):
city_name=city_list[k]["name"] #城市名称
total_confirm=city_list[k]["total"]["confirm"] #总确认病例
total_suspect=city_list[k]["total"]["suspect"] #总疑似病例
total_dead=city_list[k]["total"]["dead"] #总死亡病例
total_heal=city_list[k]["total"]["heal"] #总治愈病例
today_confirm=city_list[k]["today"]["confirm"] #今日确认病例
today_suspect=city_list[k]["total"]["suspect"] #今日疑似病例
today_dead=city_list[k]["today"]["dead"] #今日死亡病例
today_heal=city_list[k]["today"]["heal"] #今日治愈病例
print(province, city_name, total_confirm, total_suspect, total_dead, total_heal, today_confirm, today_suspect, today_dead, today_heal,update_time)
data_row3=[province, city_name, total_confirm, total_suspect, total_dead, total_heal, today_confirm, today_suspect, today_dead, today_heal, update_time]
writer.writerow(data_row3)
if __name__=="__main__":
get_data()
这里主要用到json, csv, requests三个模块,用requests发出请求,获取返回的json格式数据,我们可以用data.keys()打印出数据构成,一共有’chinaTotal’, ‘chinaAdd’, ‘lastUpdateTime’, ‘areaTree’, ‘chinaDayList’ 和 ‘chinaDayAddList’ 6部分数据,分别对应中国疫情总数,当日新增疫情总数,最近一次更新时间,各地方疫情明细,历史疫情总数和历史新增总数,其中areaTree还包括海外数据,在厘清数据组成之后就需要把各部分数据分别弄下来,对于’chinaTotal’, ‘chinaAdd’, ‘lastUpdateTime’这三部分数据都只有一条数据,对后面的研究不大,故这次只准备获取后面三部分’areaTree’, ‘chinaDayList’ 和 ‘chinaDayAddList’ ,采取了3次分别写入csv文件中,并在每次写入的时候增加了更新时间字段,使得字段完备。

1,获取数据后接下来工作是可视化了,有两个方向,一个是pyecharts, 一个是basemap。
2,这里代码每次获取都是获取三份数据,一份是每日总病例,一份是每日新增病例,这两份都是全国汇总数据,第三份是全国各城市病例数据,这个有明细,如果要看地图变迁的话需要不同日期的数据。
3,在探索病例曲线特征的时候,可以简单的按照[时间序列拟合出logistic模型,求解模型参数,再对未来时日加以预测。
参考资料
1,https://blog.csdn.net/weixin_43130164/article/details/104113559
2,https://mp.weixin.qq.com/s/NVUn0gVK9AiEm1II8c3g4g
3,https://blog.csdn.net/zengbowengood/article/details/104171607
数据获取链接:待附
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
