
<一>:特征工程:将原始数据转化为算法数据
一:特征值抽取
1:对字典数据 :from sklearn.feature_extraction import DictVectorizer
import pandas as pd import numpy as np from sklearn.feature_extraction import DictVectorizer def dict_func(): ''' 将字典数据做特征抽取(类别默认进行one-hot编码) :return:None ''' dict_ = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}] dv = DictVectorizer(sparse=False) data = dv.fit_transform(dict_) print(data) # 获取转化后的数据 (类别问题 已经进行过one-hot编码) print(dv.get_feature_names()) # 获取特征名 print(dv.inverse_transform(data)) # 将转化后的数据转化为原数据 ''' data: [[ 0. 1. 0. 100.] [ 1. 0. 0. 60.] [ 0. 0. 1. 30.]] 特征名: ['city=上海', 'city=北京', 'city=深圳', 'temperature'] 原数据:[{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0}, {'city=深圳': 1.0, 'temperature': 30.0}] '''
2:对文本特征抽取:from sklearn.feature_extraction.text import CountVectorizer
def text_func(): ''' 将文本数据做特征抽取 (默认单个字母或中文不加入特征) :return:None ''' text = '随着自然语言处理领域的顶级盛会 ACL 2019 落幕,亚马逊 Alexa AI 的机器学习科学家 Mihail Eric 对本次会议进行了一次比较全面的回顾。从奇闻轶事到学术前沿,本文一网打尽,自然语言处理领域的小伙伴们不要错过!' text_jieba = jieba.cut(text) a = list(text_jieba) text_data = ' '.join(a) # 随着 自然语言 处理 领域 的 顶级 盛会 ACL 2019 落幕 , 亚马逊 Alexa AI 的 机器 学习 科学家 Mihail Eric 对 本次 会议 进行 了 一次 比较 全面 的 回顾 。 从 奇闻 轶事 到 学术前沿 , 本文 一网打尽 , 自然语言 处理 领域 的 小伙伴 们 不要 错过 ! cv = CountVectorizer() data = cv.fit_transform([text_data,]) print(cv.get_feature_names()) print(data.toarray()) # 将数据转化为array类型 ''' 结果: ['2019', 'acl', 'ai', 'alexa', 'eric', 'mihail', '一次', '一网打尽', '不要', '亚马逊', '会议', '全面', '回顾', '处理', '奇闻', '学习', '学术前沿', '小伙伴', '本文', '本次', '机器', '比较', '盛会', '科学家', '自然语言', '落幕', '轶事', '进行', '错过', '随着', '顶级', '领域'] [[1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2]] ''' return None
3:TF-IDF表示词在全文中的重要性(结果显示为概率值) :from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
def tfidf_func(): ''' TF-IDF表示词在全文中的重要性(结果显示为概率值) :return: ''' text = ["life is short,i like python", "life is too long,i dislike python"] tf = TfidfVectorizer() data = tf.fit_transform(text) print(tf.get_feature_names()) print(data.toarray()) ''' 特征名:['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too'] 占全文概率: [[0. 0.37930349 0.37930349 0.53309782 0. 0.37930349 0.53309782 0. ] [0.47042643 0.33471228 0.33471228 0. 0.47042643 0.33471228 0. 0.47042643]] ''' return None
二:特征值预处理
1:归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,容易受异常数据的影响(比如某个值异常大或异常小)。常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间
公式:
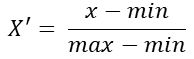
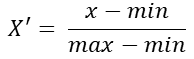
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def minmaxscaler(): """ 归一化:默认是将数据转化为 0-1 之间的数据 :return: """ num = [[90,2,10,40],[60,4,15,45],[75,3,13,46]] mm = MinMaxScaler() data = mm.fit_transform(num) print(data) ''' data: [[1. 0. 0. 0. ] [0. 1. 1. 0.83333333] [0.5 0.5 0.6 1. ]] ''' return None
2 :标准化
特点:通过对原始数据进行变换把数据变换到均值为0,方差为1范围内,解决了异常数据的影响
公式:
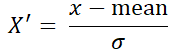
注:作用于每一列,mean为平均值,?为标准差(考量数据的稳定性)
from sklearn.preprocessing import MinMaxScaler,StandardScaler def standerscaler(): """ 标准化处理 :return: """ num = num = [[90,2,10,40],[60,4,15,45],[75,3,13,46]] std = StandardScaler() data = std.fit_transform(num) print(data) ''' 结果: [[ 1.22474487 -1.22474487 -1.29777137 -1.3970014 ] [-1.22474487 1.22474487 1.13554995 0.50800051] [ 0. 0. 0.16222142 0.88900089]] ''' return None
3:缺失值处理
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Imputer def im_extract(): ''' 缺失值处理 ''' a = [[np.nan,2,10,40],[88,4,15,45],[75,3,13,np.nan]] cv = Imputer(smissing_values="NaN", strategy="mean",axis=0, verbose=0, copy=True) # 将缺失值填充为mean data = cv.fit_transform(a) print(data)
4:PCA 降维
PCA(Principal component analysis),主成分分析。特点是保存数据集中对方差影响最大的那些特征,PCA极其容易受到数据中特征范围影响,所以在运用PCA前一定要做特征标准化,这样才能保证每维度特征的重要性等同。
from sklearn.decomposition import PCA def pca_extract(): # 降维 a = [[88, 2, 10, 40], [88, 4, 15, 45], [75, 3, 13,50]] cv = PCA(n_components=None) data = cv.fit_transform(a) print(data)
5:特征选择
from sklearn.feature_selection import VarianceThreshold
def vt_func(): """" 特征选择,删除低方差特征 """ x = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]] std = StandardScaler() vt = VarianceThreshold(threshold=(.8 * (1 - .8))) # 移除那些超过80%的数据都为1或0的特征 data = vt.fit_transform(x) print(data) ''' [[0 1] [1 0] [0 0] [1 1] [1 0] [1 1]] ''' return None
<三> 算法评估器
1:k-近邻算法
欧式公式:

from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris,fetch_20newsgroups
def K_iris(): """ K 近邻 预测花种类 :return: """ ir = load_iris() # 1 切割数据集 x_train,x_test,y_train,y_test =train_test_split(ir.data,ir.target,test_size=0.25) # 2 对数据标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 算法评估器 kn = KNeighborsClassifier() kn.fit(x_train,y_train) # 开始训练数据 y_predict = kn.predict(x_test) print(y_predict) # [0 1 1 1 0 0 0 2 2 2 1 2 0 0 1 2 2 2 0 2 1 1 2 1 0 1 1 0 1 2 1 1 0 0 0 1 22] print('准确率:',kn.score(x_test,y_test)) # 0.9473684210526315 return None
2:朴素贝叶斯
计算出数据属于各个目标值的概率,得出最大概率即对应样本属于该目标值类别。

注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston from sklearn.naive_bayes import MultinomialNB def naive_bayes(): """ 朴树贝叶斯算法实现新闻分类 :return: """ # 获取数据集 news = fetch_20newsgroups() print(len(news.data)) # 切割数据集 x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25) # 特征化出处理 ss = StandardScaler() ss.fit_transform(x_train) ss.transform(x_test) # 算法实现 nb = MultinomialNB() nb.fit(x_train,y_train) y_predict = nb.predict(x_test) score = nb.score(x_test,y_test) print() return None
3:决策树
划分依据:信息增益,信息增益最大的特征值是最有特征
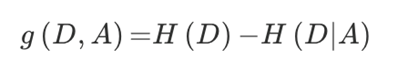
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差。
from sklearn.feature_extraction import DictVectorizer from sklearn.tree import DecisionTreeClassifier def decision_tree(): """ 决策树 :return: """ data = pd.read_csv('./data/taitan.csv') # # 对数据处理 data['age'].fillna(data['age'].mean(),inplace=True) # # 切割数据数据集 feature = data[['age','sex','pclass']] target = data['survived'] x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.25) # 对特征值做z字典特征处理》》类别-》one_hot编码 : 特征中有类别的要做one_hot 编码 dv = DictVectorizer(sparse=False) x_train = dv.fit_transform(x_train.to_dict(orient="records")) #one_hot 编码 x_test = dv.transform(x_test.to_dict(orient="records")) # 决策树 dt = DecisionTreeClassifier() dt.fit(x_train,y_train) y_predict = dt.predict(x_test) print(dt.score(x_test,y_test))
4:随机森林
包含了多个决策树,
学习算法
根据下列算法而建造每棵树:
•用N来表示训练用例(样本)的个数,M表示特征数目。
•输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
•从N个训练用例(样本)中以有放回抽样一个样本,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
from sklearn.feature_extraction import DictVectorizer from sklearn.ensemble import RandomForestClassifier def decision_tree(): """ 决策树 :return: """ data = pd.read_csv('./data/taitan.csv') # # 对数据处理 data['age'].fillna(data['age'].mean(),inplace=True) # # 切割数据数据集 feature = data[['age','sex','pclass']] target = data['survived'] x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.25) # 对特征值做z字典特征处理》》类别-》one_hot编码 : 特征中有类别的要做one_hot 编码 dv = DictVectorizer(sparse=False) x_train = dv.fit_transform(x_train.to_dict(orient="records")) #one_hot 编码 x_test = dv.transform(x_test.to_dict(orient="records")) # 决策树 dt = DecisionTreeClassifier() dt.fit(x_train,y_train) y_predict = dt.predict(x_test) print(dt.score(x_test,y_test)) # 随机森林 rfc = RandomForestClassifier() rfc.fit(x_train, y_train) # 开始训练数据 y_predict = rfc.predict(x_test) print(y_predict) print('随机森林准确率:', rfc.score(x_test, y_test))
5:逻辑回归
解决二分类的利器
from sklearn.linear_model import LogisticRegression def logistic(): """ 逻辑回归:预测癌症 :return: """ # 获取数据集和整理数据集 column = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape', 'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli', 'Mitoses', 'Class'] data = pd.read_csv('./data/cancer.csv',names=column) # 原数据中有 ? 值 要做替换 data = data.replace(to_replace='?',value=np.nan) data = data.dropna() data_train = data[column[1:10]] data_target = data[column[10]] # 切割数据集 x_train, x_test, y_train, y_test = train_test_split(data_train, data_target, test_size=0.25) # 特征处理 ss = StandardScaler() ss.fit_transform(x_train) ss.transform(x_test) # 逻辑回归算法 lg = LogisticRegression() lg.fit(x_train,y_train) print(lg.score(x_test,y_test)) print(lg.coef_) cf = classification_report(y_test,lg.predict(x_test), labels=[2, 4], target_names=["良性", "恶性"]) print(cf) return None
6:线性回归和岭回归
线性回归原理:y = matmul(x,w) + bias
def linear(): """ 正规方程和梯度下降预测波士顿房价 :return: None """ # 获取波士顿数据集 lb = load_boston() # 切割数据集 x_train, x_test, y_train, y_test = train_test_split(lb.data,lb.target,test_size=0.25) # 特征值和目标值都做 标准化特征处理 std_x = StandardScaler() x_train = std_x.fit_transform(x_train) x_test = std_x.transform(x_test) std_y = StandardScaler() y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # sklearn 中 必须将一维矩阵转化为二维 y_test = std_y.transform(y_test.reshape(-1, 1)) # 正规方程实现 : lr = LinearRegression() lr.fit(x_train,y_train) print('正规方程',lr.coef_) print('正规方程',lr.score(x_test,y_test)) y_true = std_y.inverse_transform(y_test) y_pre = std_y.inverse_transform(lr.predict(x_test)) ms = mean_squared_error(y_true,y_pre) print('正规方程均方差评价:',ms) # 梯度下降 sgd = SGDRegressor() sgd.fit(x_train,y_train) print('梯度下降',sgd.coef_) print('梯度下降',sgd.score(x_test,y_test)) y_true = std_y.inverse_transform(y_test) y_pre1 = std_y.inverse_transform(sgd.predict(x_test)) ms1 = mean_squared_error(y_true,y_pre1) print('梯度下降均方差评价:',ms1) # 岭回归 rd = Ridge() rd.fit(x_train,y_train) print('岭回归',rd.coef_) print('岭回归',rd.score(x_test,y_test)) y_true = std_y.inverse_transform(y_test) y_pre_r = std_y.inverse_transform(rd.predict(x_test)) ms1 = mean_squared_error(y_true,y_pre_r) print('岭回归均方差评价:',ms1) return None
