社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
ES 读取过程分为GET和Search两种操作。
GET/MGET(批量GET):
需要指定_index、_type、_id。也就是根据id从正排索引中获取内容。
Search:
Search不指定_id,根据关键词从哪个倒排索引中获取内容
参考文献:《Elasticsearch源码解析与优化实战》
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/docs-get.html#generated-fields
eq:
curl -X GET "localhost:9200/twitter/tweet/0"
{
"_index" : "twitter",
"_type" : "tweet",
"_id" : "0",
"_version" : 1,
"found": true,
"_source" : {
"user" : "kimchy",
"date" : "2009-11-15T14:12:12",
"likes": 0,
"message" : "trying out Elasticsearch"
}
}
| 参数名称 | 参数解释 |
|---|---|
| Realtime | 默认为true。默认是实时的,不受索引刷新频率设置的影响,如果文档已近更新,但还没有refresh到segment,GET API将会发出一个refresh调用,使文档可见。 |
| Optional Type | get api允许_类型是可选的。将其设置为“_all”时,以便获取所有类型中与ID匹配的第一个文档。 |
| Source filtering | 默认情况下(true),返回文档所有内容,可以将_source设置为false,不返回文档内容。比如:curl -X GET "localhost:9200/twitter/tweet/0?_source=false"同时可以使用_source_include和_source_exclude过滤返回文档中的部分字段。比如:curl -X GET “localhost:9200/twitter/tweet/0?_source_include=*.id&_source_exclude=entities” |
| Stored Fields | 返回索引映射中store设置为true的字段。 |
| Routing | 自定义routing。比如:curl -X GET “localhost:9200/twitter/tweet/2?routing=user1” |
| Preference | 默认情况下,GET API从分片的多个副本中随机选择一个,通过指定优先级(preference)可以选择从主分片或者本地读取。 |
| Refresh | 默认是false,设置为true,可以在读取之前先执行刷新操作,但是这时对写入速度是有负面影响的 |
| Versioning support | 如果在GET API中指定版本号,那么当文档实际版本号与请求版本号不一致时,将会返回409错误。 |
搜索和读取文档都属于读操作,可以从主分片或副分片中读取数据。
读取单个文档的流程(图片来自官网)如下图所示:
这个例子中的索引有一个主分片和两个副分片。以下是从主分片或副分片中读取时的步骤: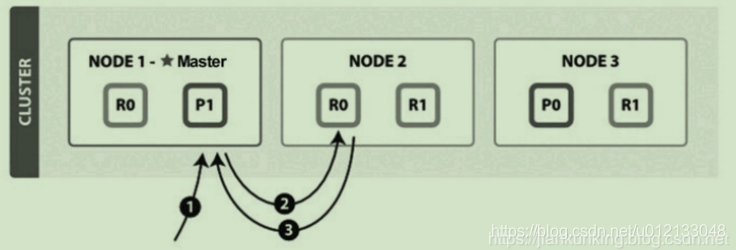
GET/MGET流程涉及两个节点:协调节点和数据节点,流程如下图所示: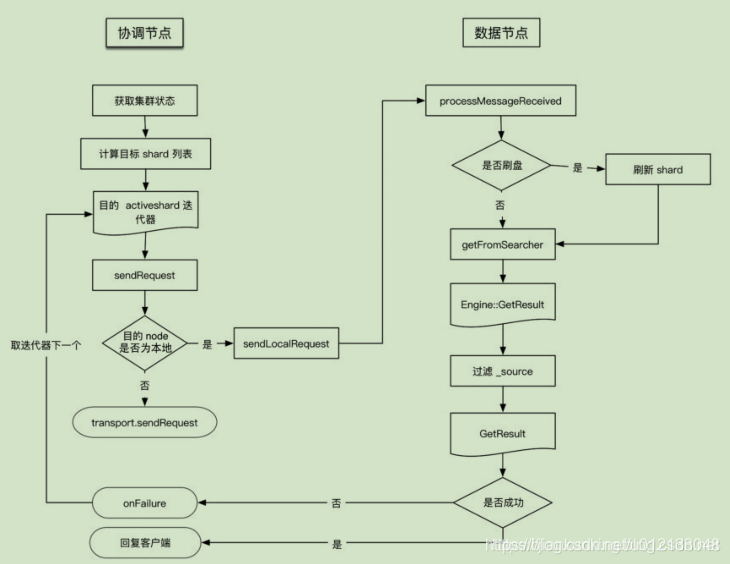
作为协调节点,像目标节点转发请求(目标节点也许是本地节点),读取数据。
1、接收来自协调节点的请求,执行messageReceived。
2、根据参数判断是否需要执行refresh,然后调用indexShard.getService().get()读取数据并存储到GetResult中。
这里分为获取数据和过滤两步,主要过程都是在ShardGetService#inneGet()函数中():
1、调用indexShard.get获取Engine.GetResult读取数据,底层会调用InternalEngine.get方法。
2、通过ShardGetService#innerGetLoadFromStroredFields,通过type、id等参数对指定的field source进行过滤,结果存于GetResult中。
向协调接待返回是否获取成功。
Get操作只能对精确的单个文档进行处理,而MGET也无非是对多个精确的文档进程处理,都需要由_index、_type和_id三元组来确定唯一文档。但搜索需要一种更复杂的模型,因为不知道查询会命中哪些文档。
从粗粒度来理解search流程,可以分为这三步:
需要两个阶段才能完成搜索的原因是,在查询的时候不知道文档位于哪个分片,因此索引的所有分片(某个副本)都要参与搜索,然后协调节点将结果合并,再根据文档ID获取文档内容。例如,有5个分片,查询返回前10个匹配度最高的文档,那么每个分片都查询出当前分片的TOP 10,协调节点将5×10 = 50的结果再次排序,返回最终TOP 10的结果给客户端。
一个简单的搜索请求示例如下:
在上面的例子中,我们从所有字段搜索“first”关键词,返回信息中几个基本字段的含义如下:
ES中的数据可以分为两类:精确值和全文。
这两种类型的数据在查询时是不同的:对精确值的比较是二进制的,查询要么匹配,要么不匹配;全文内容的查询无法给出“有”还是“没有”的结果,它只能找到结果是“看起来像”你要查询的东西,因此把查询结果按相似度排序,评分越高,相似度越大。
对数据建立索引和执行搜索的原理如下图所示: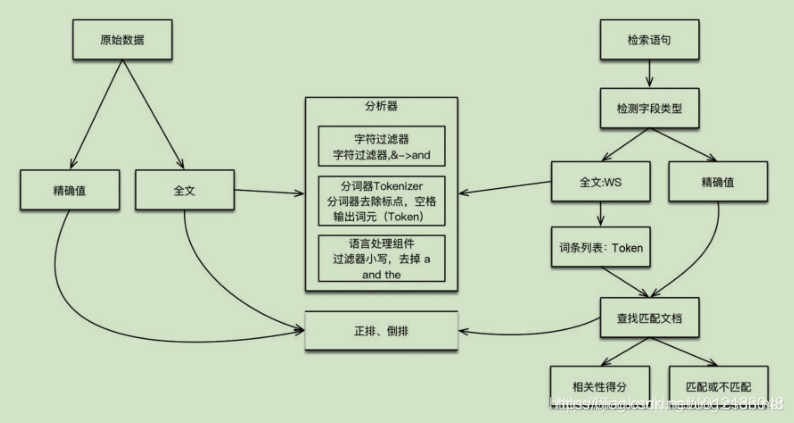
如果是全文数据,则对文本内容进行分析,这项工作在 ES 中由分析器实现。分析器实现如下功能:
搜索调用Lucene完成,如果是全文检索,则:
ES目前有四种搜索类型:
向索引的所有分片 ( shard)都发出查询请求, 各分片返回的时候把元素文档 ( document)和计算后的排名信息一起返回。
这种搜索方式是最快的。 因为相比下面的几种搜索方式, 这种查询方法只需要去 shard查询一次。 但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
优点:这种搜索方式是最快的。因为相比后面的几种es的搜索方式,这种查询方法只需要去shard查询一次。
缺点:返回的数据量不准确, 可能返回(N*分片数量)的数据并且数据排名也不准确,
同时各个shard返回的结果的数量之和可能是用户要求的size的n倍。
如果你搜索时, 没有指定搜索方式, 就是使用的这种搜索方式。 这种搜索方式, 大概分两个步骤:
第一步, 先向所有的 shard 发出请求, 各分片只返回文档 id(注意, 不包括文档 document)和排名相关的信息(也就是文档对应的分值), 然后按照各分片返回的文档的分数进行重新排序和排名, 取前 size 个文档。
第二步, 根据文档 id 去相关的 shard 取 document。 这种方式返回的 document 数量与用户要求的大小是相等的。
优点:返回的数据量是准确的。
缺点:性能一般,并且数据排名不准确。
这种方式比第一种方式多了一个 DFS 步骤,有这一步,可以更精确控制搜索打分和排名。也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块(包括文档), 再执行后面的操作。
优点:数据排名准确
缺点:性能一般;返回的数据量不准确, 可能返回(N*分片数量)的数据
在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块(不包括文档,等计算出分数排名后,根据id查询), 再执行后面的操作。
优点:返回的数据量是准确的;数据排名准确
缺点:性能最差【 这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,
如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个】
两种不同的搜索类型的区别在于查询阶段,DFS查询阶段的流程要多一些,它使用全局信息来获取更准确的评分。
一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。
当搜索任务执行在分布式系统上时,整体流程如下图所示: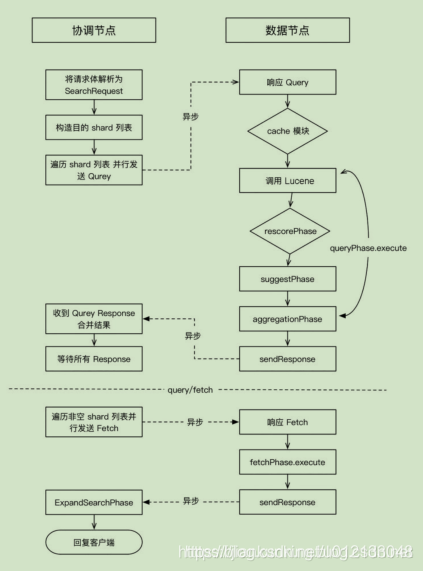
两阶段相应的实现位置:查询(Query)阶段:search.InitialSearchPhase;取回(Fetch)阶段:search.FetchSearchPhase。
它们都继承自SearchPhase,如下图所示: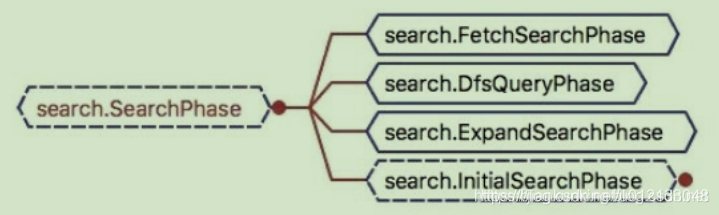
在初始查询阶段,查询会广播到索引中每一个分片副本(主分片或副分片)。每个分片在本地执行搜索并构建一个匹配文档的优先队列。
优先队列是一个存有topN匹配文档的有序列表。优先队列大小为分页参数from + size。
分布式搜索的Query阶段(图片来自官网)如下图所示: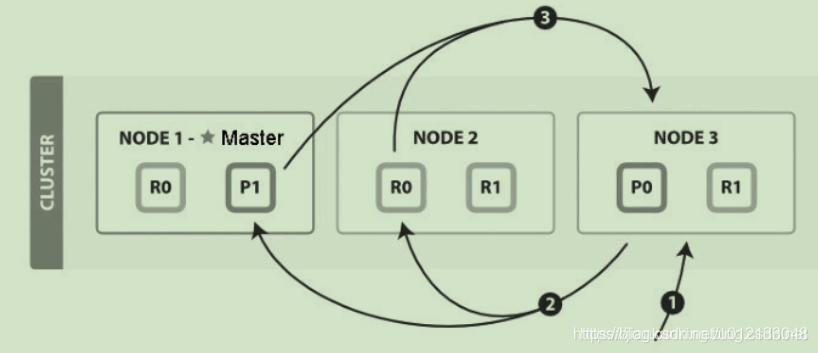
QUERY_THEN_FETCH搜索类型的查询阶段步骤如下:
协调节点广播查询请求到所有相关分片时,可以是主分片或副分片,协调节点将在之后的请求中轮询所有的分片副本来分摊负载。
查询阶段并不会对搜索请求的内容进行解析,无论搜索什么内容,只看本次搜索需要命中哪些shard,然后针对每个特定shard选择一个副本,转发搜索请求。
Query阶段知道了要取哪些数据,但是并没有取具体的数据,这就是Fetch阶段要做的。
Fetch阶段相当于GET
分布式搜索的Fetch阶段(图片来自官网)如下图所示: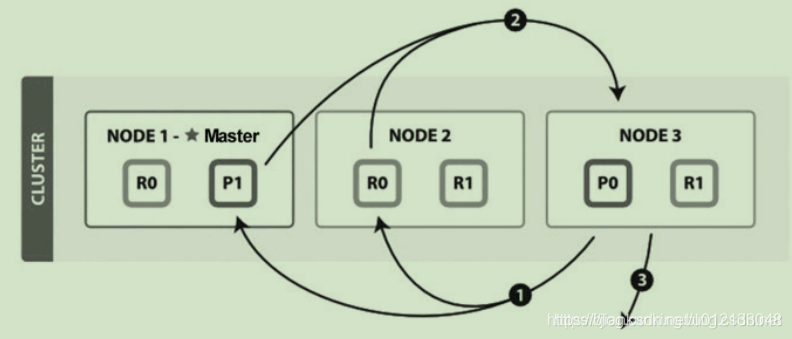
Fetch阶段由以下步骤构成:
协调节点首先决定哪些文档“确实”需要被取回,例如,如果查询指定了{ "from": 90, "size":10 },则只有从第91个开始的10个结果需要被取回。
为了避免在协调节点中创建的number_of_shards * (from + size)优先队列过大,应尽量控制分页深度。
常见的Query请求为:
indices:data/read/search/[phase/query]
其中包含几个核心功能:
a) execute(),调用lucene,searcher.search()实现搜索。
b) rescorePhare,全文检索且需要打分
c) suggestPhase,自动补全以及纠错
d) aggregationPhase,实现聚合。(在es中,而非Lucene中,在检索后完成)
响应Fetch请求,以常见的基于id进程fetch请求为例:
indices:data/read/search/[phase/fetch/id]
主要过程是执行Fetch,然后发送Response:
对Fetch响应的实现封装在searchService.executeFetchPhase中,核心是调用fetchPhase.executor(context),按照命中的文档获取相关内容,填充到SearchHits中,最终封装到FetchSearchResult中。
1、聚合是在ES中实现的,而非Lucene。
2、Query和Fetch请求之间是无状态的,除非是scroll方式。
3、分页搜索不会单独“cache”,cache和分页没有关系。
4、每次分页的请求都是一次重新搜索的过程,而不是从第一次搜索的结果中获取。看上去不太符合常规的做法,事实上互联网的搜索引擎都是重新执行了搜索过程:人们基本只看前几页,很少深度分页;重新执行一次搜索很快;如果缓存第一次搜索结果等待翻页命中,则这种缓存的代价较大,意义却不大,因此不如重新执行一次搜索。
5、搜索需要遍历分片所有的Lucene分段,因此合并Lucene分段对搜索性能有好处。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
