社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
我对数据清洗的理解是:
1、确认数据有效性
2,清除异常数据
3,优化数据结构
非常粗糙的理解哈〜
1是因为如果数据无效,爬下来都是错的......后面的也没事意义
2是可能需要的去重啊,多余的介词啊,符号啊,也应该洗一洗
3方便细分。
上一篇利用Python的+ PowerBi拉进行网勾杭州站网站的数据采集及可视化分析之爬虫篇 中,我已经完成了爬虫。
大概是爬下了7万多条数据。
1,确认数据有效性
随机抽了文件里的几个数据去拉勾看,数据无误。
随机在拉勾杭州站挑了几个岗位搜文件。也存在。
确认数据有效性完成!
2,清除异常数据
我直接将数据导入到可视化工具POWER BI中查看。(毕竟GUI界面的可视化还是比Python的敲敲代码来得快啊!)
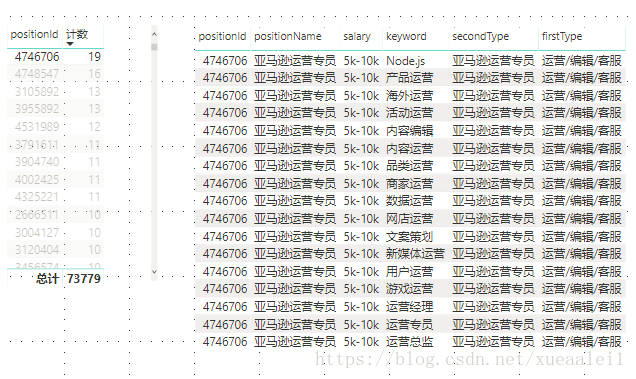
果然有大量的重复数据。点击筛选4746706这个positionId
发现,同一个岗位,被不同的关键词反复的爬下来。亚马逊运营专员居然能被Node.js的这个关键词搜到...
好吧..可能是拉勾的模糊搜索太模糊了。从这点来看,关键词这一栏完全没有意义了。
同时,对整体数据来说,亚马逊运营专员,太细致了。如果呈现成报表的话,这么细的统计数据,没什么意义。
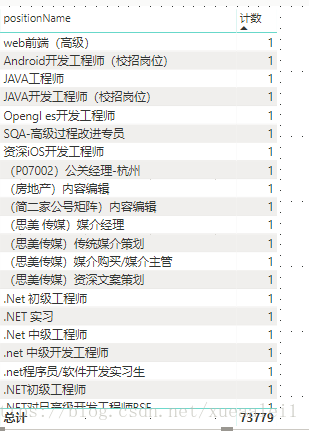
按照positionName查看数量,数量多的岗位名字都是高度的概括,统一的。但是明显有些岗位......名字明显的太细致了。哪家公司都要强行写上。如果直接按positionName,不经清洗进行统计,那么后面这些都会被忽略掉。这样可不行。这里的一个思路是利用分词,拆分关键词。利用关键词进行统计,而不单单是positionName。
工作1:positionName分词然后要去掉(),[]这种符号及其里面的内容。
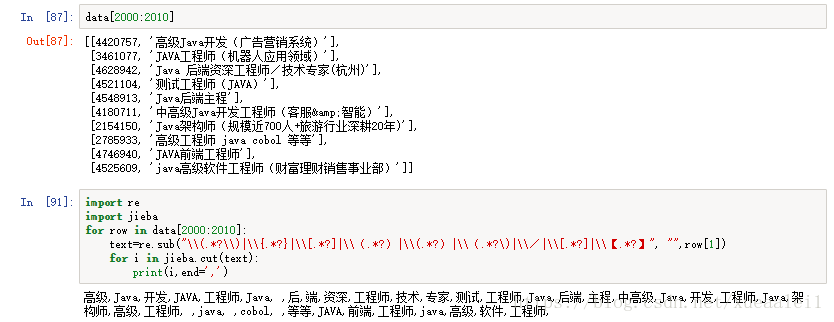
这个,因为涉及到分词,所以POWER BI稍微不够用了。这里用python读取csv,重新写一个csv出来。
数据就是pisitionid + positionname的列表。
然后利用正则表达式提取多余的符号。解霸进行分词。
然后一条positionid对应多个nameKeyWord。
很快就弄完啦〜
导入到power bi。洗去无效的数据
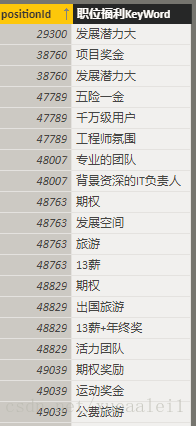
工作2:positionAdvantage分词
然后在positionAdvantage这里。职位福利吧。这个可以根据,或者空格拆分,也分词,来看看基础福利是啥
同理,还有公司福利。
清洗一下
工作3:industryLables分词
清洗完了。
工作4:薪水取平均值计算
同理,在工资这里。薪水直接取一个平均值计算吧。
这样子,基本上的数据清洗就完成啦~
然后就是利用POWER BI进行建模了~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!