社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
注释挺详细了,直接上全部代码,欢迎各位大佬批评指正。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
from lxml import etree
import os
import requests
import csv
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置一个10秒的隐式等待
browser.implicitly_wait(10)
# 使用谷歌无头浏览器来加载动态js
def start_get(url):
try:
browser.get(url)
a = []
for one in range(1, 100):
sleep(0.5)
# 翻到页底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(0.5)
# 再次翻页到底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
# 拿到页面源代码
source = browser.page_source
a.append(source)
print(f"{one}源码获取成功")
next_btn = browser.find_elements_by_xpath('.//span[@class="pagebox_next"]')
if next_btn:
next_btn[0].click()
return a
except Exception as e:
print(e)
# 对新闻列表页面进行解析
def parse_page(html):
# 创建etree对象
tree = etree.HTML(html)
new_lst = tree.xpath('//div[@id="subShowContent1_static"]') # 注意修改
for one_new in new_lst:
title = one_new.xpath('.//h2/a/text()')[0]
link = one_new.xpath('.//h2/a/@href')[0]
write_in(title, link)
# 将其写入到文件
def write_in(title, link):
alist = []
print('开始写入篇新闻{}'.format(title))
browser.get(link)
sleep(1)
source = browser.page_source
tree = etree.HTML(source)
alist.append(title)
con_link = link
alist.append(con_link)
content_lst = tree.xpath('.//div[@class="article"]//p')
con = ''
for one_content in content_lst:
if one_content.text:
con = con + 'n' + one_content.text.strip()
alist.append(con)
post_time = tree.xpath('.//span[@class="date"]')[0].text
alist.append(post_time)
post_source = tree.xpath('.//a[@class="source"]')[0].text
alist.append(post_source)
# browser.get(url)
tiecount = tree.xpath('.//a[@data-sudaclick="comment_sum_p"]')[0].text
alist.append(tiecount)
tiejoincount = tree.xpath('.//a[@data-sudaclick="comment_participatesum_p"]')[0].text
alist.append(tiejoincount)
# 1. 创建文件对象
f = open('新浪.csv', 'a+', encoding='utf-8',newline='')
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# print(alist)
csv_writer.writerow(alist)
f.close()
if __name__ == '__main__':
urls = ['https://news.163.com/domestic/','https://news.163.com/world/','https://war.163.com/','https://money.163.com/','https://tech.163.com/']
for url in urls:
html_list = start_get(url)
for h in html_list:
try:
parse_page(h)
except Exception as e:
print(e)
结果如下: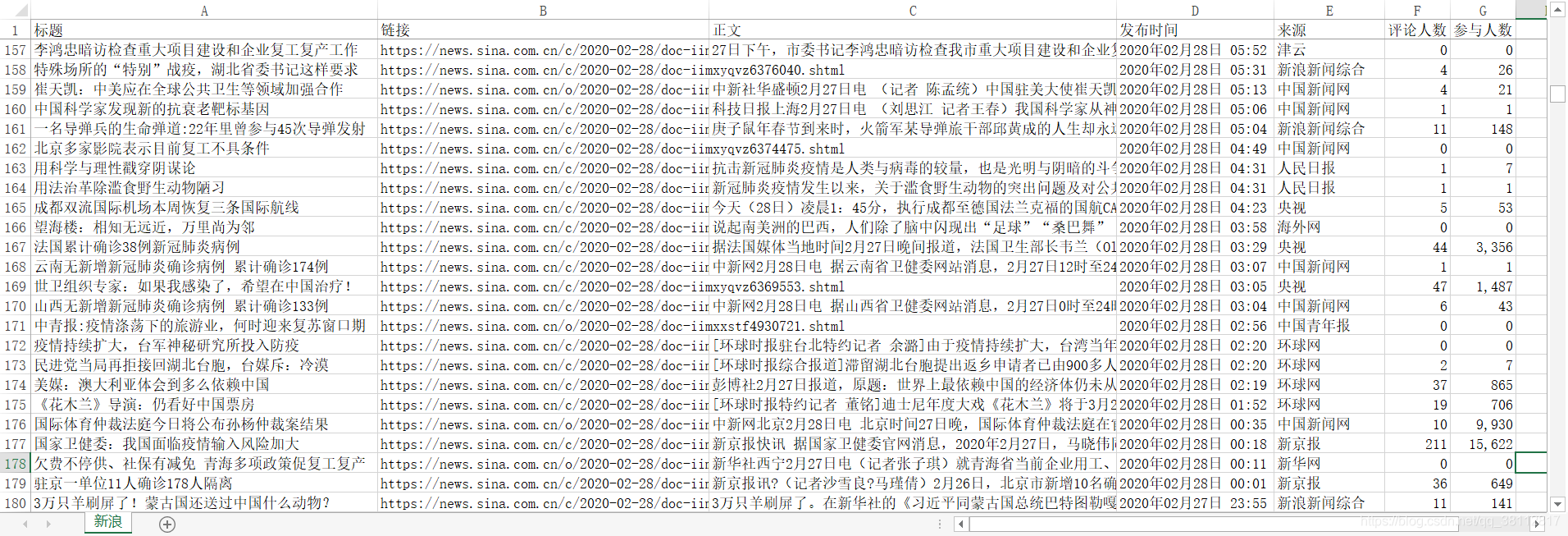
注:本文仅用于技术交流,不得用于商业用途。不遵守者,与本文作者无关。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
