社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
刚学python爬虫,用爬虫爬取新浪微博热搜,看看效果如何,也是对这段时间学习python的总结。
一、目的:
抓取新浪微博2020年1月3日星期五的热搜榜,将抓取到的数据进行动态展示,并生成当天的微博热点词云及微博热搜频度较高的前20个关键词的条形图。
二、思路:
三、相关实现步骤
1.网页解析
定义请求头来进行模拟浏览器,并随机生成一个请求头,方法def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
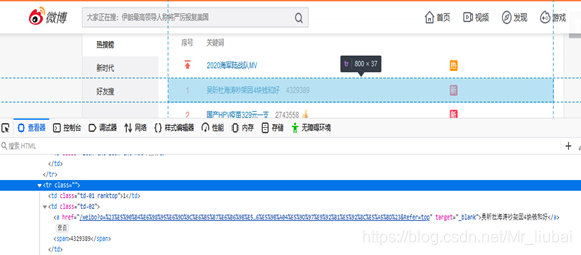
解析网站方法:def get_data(url,headers)
访问
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
通过lxml解析网页
bf = BeautifulSoup(html, "lxml")
通过观察,每一条热搜都是在tr class=””下,因此只需遍历所有的class=””
就能得到每一条热搜
div_content = bf.find_all("tr", class_="")
遍历div_content,获得每条热搜的名次,主题,讨论量
for item in div_content:
去掉置顶的那一条信息,在循环外加个变量t = 1
if (t == 1):
t = 0
continue
tr下有三条td信息,分别代表名次、热搜主题和浏览量、标签表情,前两条信息是我们想要获取的
获取当前热搜名次
num_content = item.select("td")[0].string
热搜主题和浏览量分别在td-02的a标签和span标签下
获取当前热搜主题
content = item.select("td")[1].select("a")[0].string
获取当前热搜主题讨论量
num = item.select("td")[1].select("span")[0].string
获取当前系统时间,需要在前面导入from time import strftime
current_time = strftime("%Y-%m-%d %H:%M")
将当前热搜名次、当前热搜主题、当前热搜主题讨论量、当前系统时间放入list,以便存储数据
list = [content,num_content,num,current_time]
将list整个再放入一个list中
list_content.append(list)
2.存储数据
将爬取到的数据存储起来,存储方法def store_Excel(list):
写入文件,编码方式为utf_8_sig,生成的csv文件不会乱码,不换行操作为newline=””
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
对列表进行遍历,写入
for item in list:
csv_writer.writerow(item)
关闭文件
file.close()
3.生成词云
思路:
2,通过累加的方式进行列表的遍历累加,把列表变成长字符串
3,把字符串通过结巴分词的方式进行拆分空格分词
4,找到一张轮廓清晰的图片打开并用numpy进行轮廓获取
5,用WordCloud来生成当天微博热搜热点的词云。
导入生成词云的库
rom wordcloud import WordCloud
import Image
import numpy
import jieba
定义字符串来进行字符串存储
str = ""
读取热搜热点表格
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
遍历列表
for item in csv_reader:
去掉第一条无用信息,在循环外定义变量t=1
if t == 1:
t = 0
continue
字符串拼接,热搜热点话题在第一列
str += item[0]
关闭文件
file.close()
通过结巴分词进行分词
jieba_content = jieba.cut(str)
join方法进行空格拼接
join_content=" ".join(jieba_content)
打开图片
wei_bo = Image.open("logo.jpg")
找轮廓
wei_bo_image = numpy.array(wei_bo)
制作生成词云
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜.jpg")
最终词云展示:
词云是由微博logo图片勾勒出来的,字体大小代表热度,字体越大,代表热度越高,字体越小,热度越低

4.分析数据
思路:
1.将微博热搜主题存储在txt文件中
2.读取txt文件,用jieba分词进行分词操作,生成关键词
3.对关键词进行频度统计
4.将统计好的关键词按照频度从大到小进行排序
5.将排序过的结果存储在csv文件中,以便进行后续操作
定义字典
word_dic = {}
打开文件,读取数据
with open("1.txt", "r", encoding="utf-8") as file:
txt = file.read()
file.close()
jieba分词切分数据
words = jieba.lcut(txt)
循环遍历数据
for word in words:
如果关键字数为1,不统计
if len(word) == 1:
continue
否则频度增1
else:
word_dic[word] = word_dic.get(word, 0) + 1
字典数据转换成元祖数据,用zip实现
word_zip = zip(word_dic.values(), word_dic.keys())
对元祖里面的数据按照value从大到小进行排序
word_sort = list(sorted(word_zip, reverse=True))
定义两个list进行数据的存储
list_1 = ["name", "count_name"]
list_2 = []
list_2.append(list_1)
for item in word_sort:
# 词频数
count = item[0]
# 关键字
name = item[1]
list_1 = [name, count]
list_2.append(list_1)
写入文件
with open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")as file:
csv_writer = csv.writer(file)
遍历list_2,写入每行
for i in list_2:
csv_writer.writerow(i)
5.生成绘图
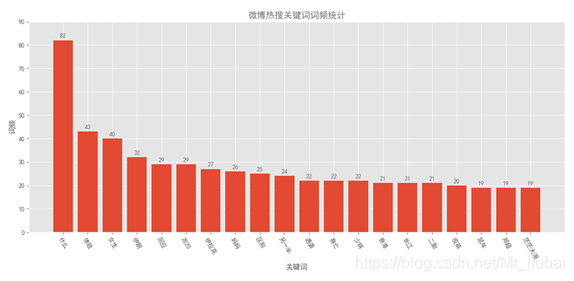
思路:根据排序好的热搜关键字的文件,提取前20个频率高的数据进行条形图的绘制
导入绘图工具包
import pandas as pd
import matplotlib.pyplot as plt
定义绘图风格及颜色
plt.style.use('ggplot')
colors1 = '#6D6D6D'
读取排序好的文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
提取排名前20的关键词和频度
name1 = df.name[:20]
count1 = df.count_name[:20]
绘制条形图,用range()能保持x轴正确顺序
plt.bar(range(20),count1,tick_label = name1)
设置纵坐标范围
plt.ylim(0,90)
显示中文字体标签
plt.rcParams['font.sans-serif'] = ['SimHei']
标题
plt.title('微博热搜关键词词频统计',color = colors1)
x轴标题、y轴标题
plt.title('微博热搜关键词词频统计',color = colors1)
plt.xlabel('关键词')
为每个条形图添加数值标签
for x,y in enumerate(list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
x轴关键字旋转300度
plt.xticks(rotation = 300)
自动控制空白边缘,以全部显示x轴坐标
plt.tight_layout()
保存图片
plt.savefig('微博热搜关键词词频统计top20.png')
显示图片
plt.show()
绘图结果展示:
本次爬虫共抓取大约20多组数据,每组数据对应50条热搜榜单,抓取时间为2020年1月1日9:30-21:00,每次抓取时间间隔为20-30分钟。抓取这么多组数据主要是为了做数据的动态效果,展示一天来微博热搜的动态变化情况
数据动态展示效果图:
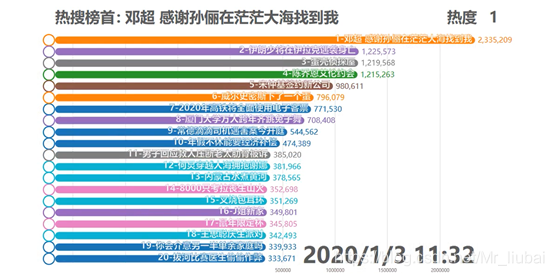
完整数据动态效果视频详见微博热搜数据动态展示.mp4
完整代码如下:
import requests
from bs4 import BeautifulSoup
import lxml
import random
import time
import csv
from time import strftime
from wordcloud import WordCloud
import Image
import numpy
import jieba.analyse
import jieba
import pandas as pd
import matplotlib.pyplot as plt
list_content = []
list_t = []
#list = ["name","type","value","date"]
#list_content.append(list)
def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
pass
#从微博网站获取数据
def get_data(url,headers):
time_sleep = random.randint(0, 1)
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
#print("响应码:", req.status_code)
print("名次","微博热搜话题","微博热搜话题量","当前时间")
html = req.text
# print(html)
bf = BeautifulSoup(html, "lxml")
# print(bf)
div_content = bf.find_all("tr", class_="")
t = 1
for item in div_content:
#去掉第一条信息
if (t == 1):
t = 0
continue
time.sleep(time_sleep)
#获取当前热搜名次
num_content = item.select("td")[0].string
#获取当前热搜主题
content = item.select("td")[1].select("a")[0].string
# 获取当前热搜主题讨论量
num = item.select("td")[1].select("span")[0].string
#获取当前时间
current_time = strftime("%Y-%m-%d %H:%M")
# print(num)
list_t = [content,num_content,num,current_time]
list_content.append(list_t)
print(num_content, content, num,current_time)
#print(list_content)
pass
#存储数据
def store_Excel(list):
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
for item in list:
csv_writer.writerow(item)
file.close()
pass
#生成词云
def get_cloud():
str = ""
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
t = 1
for item in csv_reader:
# 去掉第一行无用信息
if t == 1:
t = 0
continue
str += item[0]
#print(str)
file.close()
jieba_content = jieba.cut(str)
#print(jieba_content)
join_content=" ".join(jieba_content)
#print(jieba_content)
wei_bo = Image.open("logo.jpg")
wei_bo_image = numpy.array(wei_bo)
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜3.jpg")
with open("1.txt","w",encoding="utf-8") as file:
file.write(str)
file.close()
pass
#分析数据
def analysis_data():
word_dic = {}
with open("1.txt", "r", encoding="utf-8") as file:
txt = file.read()
file.close()
# jieba分词切分数据
words = jieba.lcut(txt)
#print(words)
for word in words:
# 如果关键字字数为1,不统计
if len(word) == 1:
continue
# 否则增1
else:
word_dic[word] = word_dic.get(word, 0) + 1
# print(word_dic)
# 字典数据转换成元祖
word_zip = zip(word_dic.values(), word_dic.keys())
# 对元祖里面的元素按照value从大到小进行排序
word_sort = list(sorted(word_zip, reverse=True))
# print(word_sort)
list_1 = ["name", "count_name"]
list_2 = []
list_2.append(list_1)
for item in word_sort:
# 词频数
count = item[0]
# 关键字
name = item[1]
list_1 = [name, count]
list_2.append(list_1)
#print(list_2)
with open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")as file:
csv_writer = csv.writer(file)
for i in list_2:
csv_writer.writerow(i)
file.close()
pass
#数据绘图
def draw_data():
#绘图风格
plt.style.use('ggplot')
colors1 = '#6D6D6D'
#读取csv文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
#print(df)
#df_data = df.sort_values('count_name',ascending=False)
name1 = df.name[:20]
count1 = df.count_name[:20]
#print(name1,count1)
#绘制条形图,用range()能保持x轴正确顺序
plt.bar(range(20),count1,tick_label = name1)
#设置纵坐标范围
plt.ylim(0,90)
#显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
#标题
plt.title('微博热搜关键词词频统计',color = colors1)
#x轴标题
plt.xlabel('关键词')
#y轴标题
plt.ylabel('词频')
#为每个条形图添加数值标签
for x,y in enumerate(list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
#x轴关键字旋转300度
plt.xticks(rotation = 300)
#自动控制空白边缘,以全部显示x轴坐标
plt.tight_layout()
#plt.savefig('微博热搜关键词词频统计top20.png')
plt.show()
pass
if __name__ == '__main__':
url = "https://s.weibo.com/top/summary?cate=realtimehot"
print("*********************微博热搜榜*********************")
#获取微博热搜数据
get_data(url,get_header())
#存储微博热搜数据
#store_Excel(list_content)
#生成微博热搜词云
#get_cloud()
#分析数据
analysis_data()
#绘图描绘数据,生成微博热搜关键词频度top20
draw_data()
print("*********************微博热搜榜*********************")
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
