社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬取的目标网址:
http://www.zdqx.com/qingchun/index.html
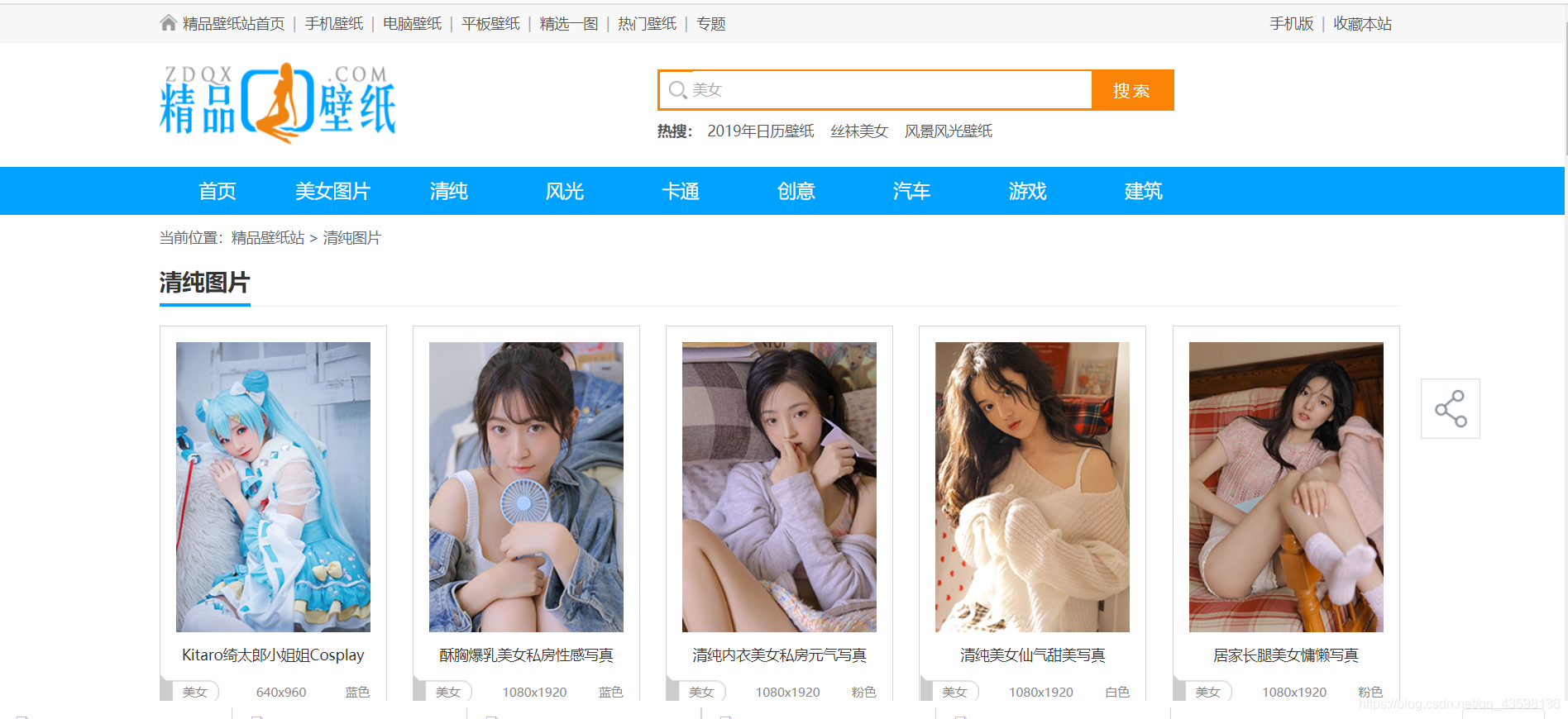
话不多说,直接上代码:
import requests
import re,os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'referer': 'http://www.zdqx.com/pcbz/70270.html',
'cookie': 'Hm_lvt_303a32038183efa6d8efec90c0031b87=1581472898; Hm_lpvt_303a32038183efa6d8efec90c0031b87=1581472912'
}
def get_urls(url,num_page):
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
result = re.findall('<div class="listbox">(.*?)</div>', response.text, re.S)
urlsTitleList = re.findall('<a href="(.*?)" target="_blank" title="(.*?)">', str(result), re.S)
pageNumList = re.findall('<em class="page_num">共(.*?)张</em>',str(result), re.S)
for urlAndTitle,num in zip(urlsTitleList,pageNumList):
url = 'http:'+urlAndTitle[0]
title = urlAndTitle[1]
num = int(num)
for page in range(1,num+1):
if page == 1:
newUrl = url
else:
newUrl = url.replace('.html','_%s.html'%page)
resp = requests.get(newUrl,headers=headers)
resp.encoding = resp.apparent_encoding
div_main = re.findall('<div class="main_center_img" style=" min-height: 745px;">(.*?)</div>',resp.text,re.S)
url_alt = re.findall('<img src="(.*?)"', str(div_main), re.S) # 长度为3
_url = 'http:'+url_alt[1]
imgTitle = title+str(page)
savedata(_url,imgTitle,num_page)
def savedata(url,title,num_page):
path = '小姐姐图片/第{}页'.format(num_page)
if not os.path.exists(path):
os.makedirs(path) #多级目录
response = requests.get(url,headers=headers)
response.encoding = response.apparent_encoding
with open(path + '/' + title + '.jpg',mode="wb") as f:
f.write(response.content)
print(title+' 保存成功!')
f.close()
def download_page(num_page):
if num_page == 1:
url = 'http://www.zdqx.com/qingchun/index.html'
else:
url = 'http://www.zdqx.com/qingchun/index_' + str(num_page) + '.html'
get_urls(url, num_page)
print('第' + str(num_page) + '页采集完毕!')
def main_run():
want_page = input("您需要爬取第几页?(共1-42页),输入'all'则爬取全部约10000张高清壁纸:n")
if (want_page == 'all'):
for page in range(1, 41):
download_page(page)
try:
num_page = int(want_page)
except:
print("您的输入不合法,只能输入纯数字或字符串'all',请重新输入")
main_run()
if(num_page<1 or num_page>42):
print("您的输入不合法,页码数只能在1-42之间,请重新输入")
main_run()
else:
download_page(num_page)
if __name__ == '__main__':
main_run()
对于多线程还不太熟悉,就没有用到多线程。
虽然爬取全部约10000张高清图太慢了,但是爬取一页的时间还是可以勉强接受的。
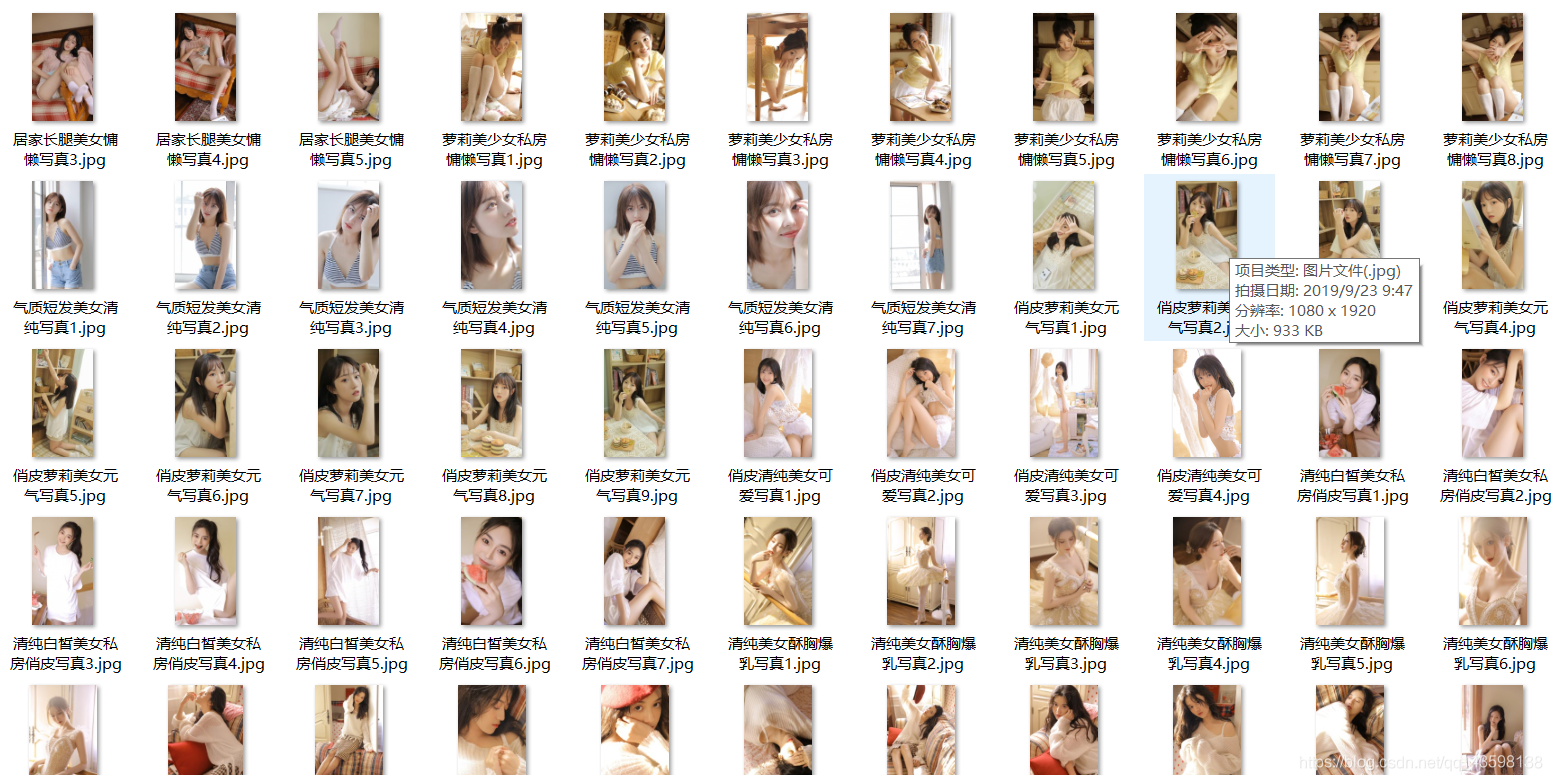
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
