社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
2016年,DeepMind的围棋机器人AlphaGo在与李世石的第二局对决中第37手落子的瞬间,整个围棋界都震惊了。评棋人Michael Redmond,一位有着近千场顶级比赛经验的职业棋手,在直播中目瞪口呆,他甚至把这颗棋子从棋盘上拿下来观察周边的情况,仿佛要确认AlphaGo是否下错了棋。第二天,Redmond告诉美国围棋E杂志:“我到现在还不明白这步棋背后的道理。”李世石这位统治了世界棋坛十年的大师,花了 12 分钟来研究这一棋局,之后才做出回应。图 13-1展示了这手传说中的落子。
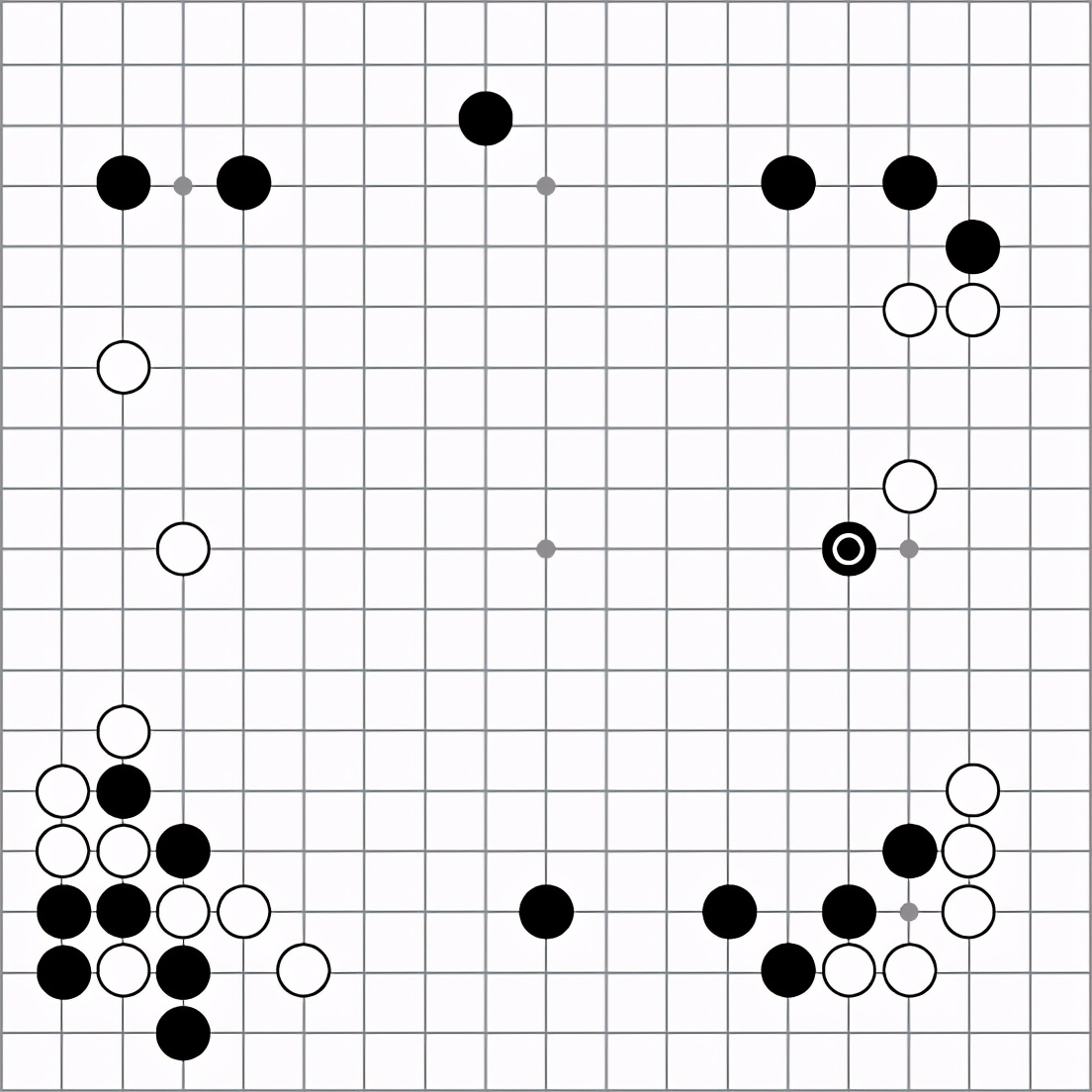
图13-1 AlphaGo在对阵李世石的第二局中做出的传奇落子动作。这手落子震惊了许多职业棋手
这手落子完全违背了传统的围棋理论。对角落子,或者叫尖冲,会引诱白子沿着边界继续长出,并做出一道实墙。人们通常认为这是一个五五开的交换:白方获得边界的空点,而黑方则获得对棋盘中央区域的影响力。但是白棋落在离边界4格的地方,一旦让黑方做出实墙,黑方会得到过多的地盘。(我们需要对正在阅读的围棋高手表示歉意,这里的描述做了过多的简化。)第5行的尖冲看起来有些业余——至少在“AlphaGo教授”最终五局四胜战胜这位传奇棋手之前看来确实如此。在这一步尖冲之后,AlphaGo还做出了许多出人意料的落子动作。一年之后,上到顶级职业棋手,下至业余俱乐部棋手,所有人都在尝试模仿AlphaGo所采用的动作。
本章我们将学习组成AlphaGo的所有结构,并了解它的工作机制。AlphaGo是基于职业棋谱的监督深度学习(即我们在第5章至第8章中所学的)与基于自我对弈数据的深度强化学习(即第9章至第12章所介绍的)的一种巧妙结合,然后再创造性地用这两种深度学习网络来改进树搜索。读者可能会感觉惊奇,原来我们已经对AlphaGo的所有组件都有所了解了。更精确地说,我们将要详细介绍AlphaGo系统的如下流程工作。
图13-2归纳了我们刚刚列出的整个流程。在本章中,我们会深入讨论图中的各个部分,并在各节中提供更多的细节。
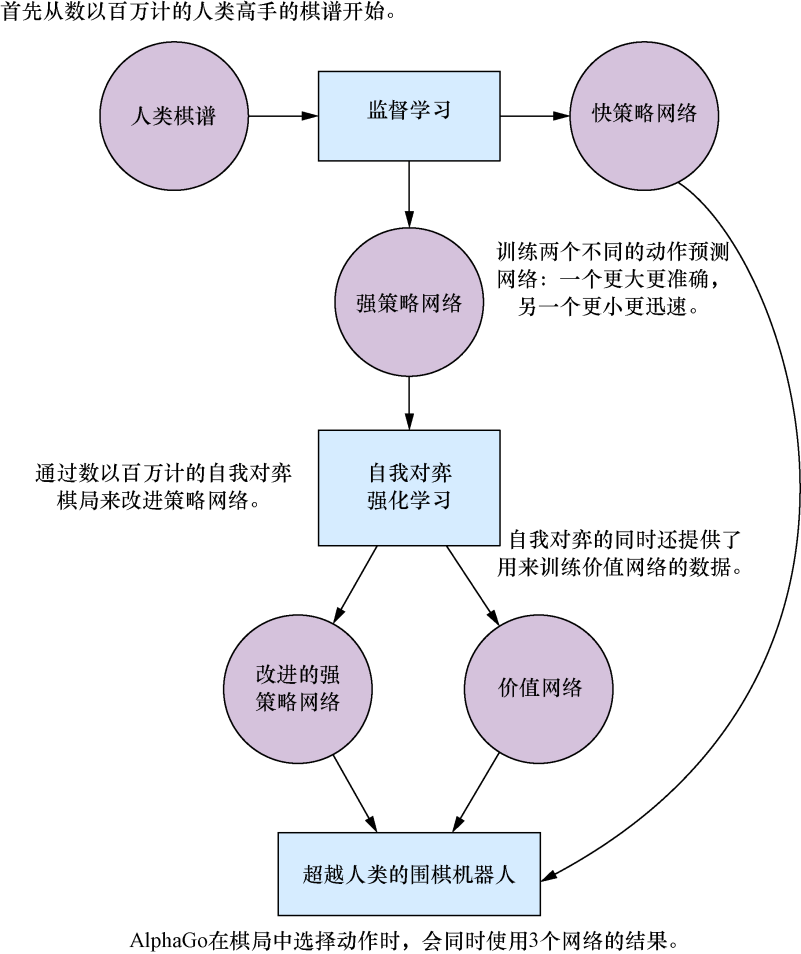
图13-2 如何训练AlphaGo AI背后的3个神经网络。
首先,从人类棋谱集合开始,训练两个神经网络来预测下一步动作:一个网络更小更迅速,而另一个更大更准确。接着,我们可以继续通过自我对弈来改进较大网络的性能。自我对弈同时也为训练一个价值网络提供了数据。最后,AlphaGo会在一个树搜索算法中同时采用这3个网络,得到极强的对弈表现
在前面的介绍中我们已经了解到,AlphaGo使用了3个神经网络:2个策略网络和1个价值网络。虽然看起来有点多,但在本节中我们将会看到,这几个网络以及它们的输入特征在概念上是很接近的。而关于AlphaGo所用的深度学习技术,最令人惊奇的地方反而是我们对它们的熟悉程度,本书在第5章至第12章已经对它们做了大量的介绍。在深入介绍这几个神经网络的构建和训练的细节之前,让我们先讨论一下它们在AlphaGo系统中所扮演的角色。
现在我们已经基本了解了这3个深度神经网络在AlphaGo中的作用,下一步接着展示如何在Python的Keras库构建它们。在深入讨论代码之前,我们先概述这几个网络的架构,如下所示。如果读者需要温习卷积网络的术语,请再次阅读第7章。
可以看到,在AlphaGo中策略网络和价值网络采用的正是第6章所介绍的深度卷积神经网络。这两个网络非常相似,我们甚至可以直接用一个Python函数来定义它们。在此之前,我们先看看Keras的一种特殊用法,它可以显著地缩短网络的定义。第7章中讲过,我们可以使用Keras的ZeroPadding2D实用工具层来对齐输入图像。这样做完全没问题,但如果把它的功能移入Conv2D层中,就能在模型定义时节省许多笔墨。在价值网络和策略网络中,可以对齐每个卷积层的输入,使它们的输出过滤器的尺寸与输入相同(19×19)。例如,按照我们以往的做法,第1层有19×19输入,第2层核心尺寸为5,输出是19×19过滤器,需要将第1层对齐成23×23的图像。而现在我们可以直接让卷积层维持输入尺寸,只需在定义卷积层时提供参数padding='same',它就能够自己处理对齐操作了。有了这种快捷定义,接下来我们就可以方便地定义AlphaGo的策略网络与价值网络所共有的11个层,如代码清单13-1所示。读者可以在GitHub代码库中的dlgo.networks模块中的alphago.py文件中找到这个定义。
代码清单13-1 为AlphaGo的策略网络和价值网络初始化神经网络
from keras.models import Sequential
from keras.layers.core import Dense, Flatten
from keras.layers.convolutional import Conv2D
def alphago_model(input_shape, is_policy_net=False, ⇽--- 这个布尔值选项用来在初始化时指定是策略网络还是价值网络
num_filters=192, ⇽--- 除最后一个卷积层之外,所有层的过滤器数量都相同
first_kernel_size=5,
other_kernel_size=3): ⇽--- 第1层的核心尺寸为5,其他层都是3
model = Sequential()
model.add(
Conv2D(num_filters, first_kernel_size, input_shape=input_shape,
padding='same',
data_format='channels_first', activation='relu'))
for i in range(2, 12): ⇽--- AlphaGo的策略网络和价值网络的前12层完全一致
model.add(
Conv2D(num_filters, other_kernel_size, padding='same',
data_format='channels_first', activation='relu'))注意,我们还没有指定第1层的输入形状。这是因为这个形状在策略网络和价值网络中略有不同。我们可以在13.1.2节介绍AlphaGo的棋盘编码器的代码中看到这个区别。继续model的定义,我们还差一个最终卷积层就能完成强策略网络的定义,如代码清单13-2所示。
代码清单13-2 在Keras中创建AlphaGo的强策略网络
if is_policy_net:
model.add(
Conv2D(filters=1, kernel_size=1, padding='same',
data_format='channels_first', activation='softmax'))
model.add(Flatten())
return model可以看到,最后需要添加一个Flatten层来展平前面的预测输出,并确保与第5章至第8章中定义的模型的一致性。
如果想要返回的是AlphaGo的价值网络,可以再添加两个Conv2D层、一个Flatten层和两个Dense层,然后将它们连接起来,如代码清单13-3所示。
代码清单13-3 在Keras中构建AlphaGo的价值网络
else:
model.add(
Conv2D(num_filters, other_kernel_size, padding='same',
data_format='channels_first', activation='relu'))
model.add(
Conv2D(filters=1, kernel_size=1, padding='same',
data_format='channels_first', activation='relu'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='tanh'))
return model这里我们不具体讨论快策略网络的架构。快策略网络的输入特征定义与网络架构有更多技术细节,但并不能帮助我们加深对AlphaGo系统的理解。所以如果读者想要进行自己的试验,完全可以直接采用我们在dlog.networks模块中已经定义好的网络,例如small、medium或large。快策略网络的主要目的是构建一个比强策略网络更小的网络,能够进行快速评估。接下来我们会深入了解训练过程的细节。
现在我们已经了解了AlphaGo使用的所有网络,下面讨论一下AlphaGo如何对棋盘数据进行编码。在第6章和第7章中我们已经实现了不少棋盘编码器,包括oneplane、sevenplane和simple,这些编码器都存放在dlgo.encoders模块中。AlphaGo所使用的特征平面会比它们更复杂一些,但也是这些已知编码器的自然延续。
AlphaGo策略网络所用的棋盘编码器有48个特征平面,而它的价值网络还需要再添加一个平面。这48个平面包含11种概念,其中一部分是我们已经见过的,其他则是新的,我们会逐一详细讨论。总的来说,与以往的编码器相比,AlphaGo更多地利用了围棋专有的定式。最典型的例子就是在特征集合中引入了征子和引征概念(参见图13-3)。
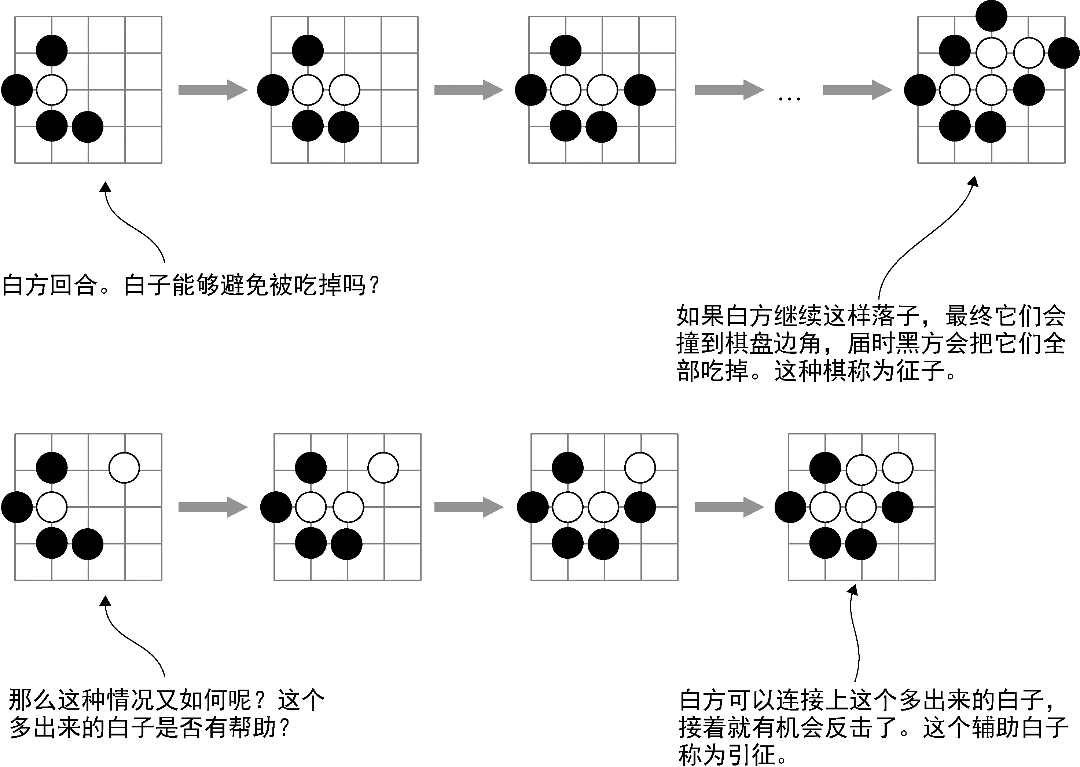
图13-3 AlphaGo将很多围棋策略概念直接编码到特征平面中,包括征子概念。在第一个例子中,白子只剩一口气了,这意味着黑方可以在下一回合吃掉它。白方可以长出来增加一口气,但是黑方也可以接着落子将白子的气减少为一口。这样一直持续下去,直到碰到棋盘边线,白子还是会被全部吃掉。而在另一种情况下,如果在征子的路线上已经有一颗白子,白方就有可能逃离被吃子的命运。AlphaGo中有一个特征平面专门用来表示征子是否能成功
我们之前所有的围棋棋盘编码器都采用了一个技巧,即二元特征(binary feature),这个技巧在AlphaGo中也被采用。例如,在捕获气的概念(棋盘上相邻的空白点)时,我们并不只用一个特征平面来表示棋盘上每颗棋子的气数,而是用3个二元表达的平面来表示一颗棋子是有1口气、2口气还是3口气。在AlphaGo中也可以看到相同的做法,但是它采用了8个特征平面来记录二元计数。在气的例子中,这意味着8个平面分别代表每颗棋子是否有1口、2口、3口、4口、5口、6口、7口和至少8口气。
AlphaGo与第6章至第8章中介绍的唯一不同点在于,它将棋子的颜色独立出来,显式地编码到另一个单独的特征平面中。回顾一下第7章的sevenplane编码器,我们的眼平面同时包含黑子平面和白子平面,而AlphaGo只用一个特征集合用来记录气的数量,并且所有的特征都是针对下一回合的执子方。例如,在特征集“吃子数”(用来记录一个动作能吃掉的棋子数目)中,只记录当前执子方能够吃掉的棋子数量,不论它是黑方还是白方。
表13-1总结了AlphaGo所使用的全部特征平面。前48个平面用于策略网络,最后一个只用于价值网络。
表13-1 AlphaGo所使用的特征平面
| 特征名称 | 平面数量 | 说明 |
| 执子颜色 | 3 | 3个特征平面分别代表当前执子方、对手方,以及棋盘上的空点的棋子颜色 |
| 一 | 1 | 一个全部填入值1的特征平面 |
| 零 | 1 | 一个全部填入值0的特征平面 |
| 明智度 | 1 | 一个动作如果合法,且不会填补当前棋手的眼,则会在平面上填入1,否则填入0 |
| 动作回合数 | 8 | 这个集合有8个二元平面,代表一个动作落子离现在有多少个回合 |
| 气数 | 8 | 当前动作所在的棋链的气数,也分为8个二元平面 |
| 动作后气数 | 8 | 如果这个动作执行了之后,还会剩多少口气 |
| 吃子数 | 8 | 这个动作会吃掉多少颗对方棋子 |
| 自劫争数 | 8 | 如果这个动作执行之后,有多少己方的棋子会陷入劫争,可能在下一回合被对方提走 |
| 征子提子 | 1 | 这颗棋子是否会被通过征子吃掉 |
| 引征 | 1 | 这颗棋子是否能够逃出一个可能的征子局面 |
| 当前执子方 | 1 | 如果当前执子方是黑子,整个平面填入1;如果是白子,则填入0 |
这些特征的实现可以在本书的GitHub代码库中的dlgo.encoder模块中找到,文件是alphago.py。虽然每一个特征集的实现都不困难,但和我们将要介绍的AlphaGo其他部分相比,它们并不显得很有趣。实现“征子提子”平面难度较高,而且要对一个动作从执行时到现在的回合数进行编码,需要修改围棋棋盘的定义。因此如果读者对这些实现有兴趣的话,可以参看GitHub上的实现代码。
让我们看看AlphaGoEncoder如何初始化,然后把它应用到深度神经网络的训练中。它需要一个围棋棋盘尺寸参数,以及一个布尔值参数use_player_plane(代表是否包含第49个平面)。代码清单13-4展示了它的签名以及初始化过程。
代码清单13-4 AlphaGo棋盘编码器的签名以及初始化
class AlphaGoEncoder(Encoder):
def __init__(self, board_size, use_player_plane=False):
self.board_width, self.board_height = board_size
self.use_player_plane = use_player_plane
self.num_planes = 48 + use_player_plane网络架构和输入特征都准备好之后,我们开始为AlphaGo训练策略网络。第一步与第7章的流程完全一致:指定一个棋盘编码器和一个代理,加载棋谱数据,并使用这些数据来训练代理。图13-4展示了这个流程。虽然我们使用了更加复杂的特征和网络,但流程还是完全一样的。
图13-4 AlphaGo的策略网络监督训练过程与第6章和第7章中介绍的完全一致。我们对人工棋谱进行复盘,并重新产生一系列游戏状态。每个游戏状态编码为一个张量(这个图展示了一个只有两个平面的张量,而AlphaGo实际使用了48个平面)。训练目标是一个与棋盘尺寸相同的向量,并在实际落子点填入1
要初始化并训练AlphaGo的强策略网络,需要先初始化一个AlphaGoEncoder,然后创建两个围棋数据生成器,分别用于训练和测试,如代码清单13-5所示。这个步骤与第7章一样。这一步的代码可以在GitHub上的
examples/alphago/alphago_policy_sl.py文件中找到。
代码清单13-5 为AlphaGo的策略网络的第一步训练加载数据
from dlgo.data.parallel_processor import GoDataProcessor
from dlgo.encoders.alphago import AlphaGoEncoder
from dlgo.agent.predict import DeepLearningAgent
from dlgo.networks.alphago import alphago_model
from keras.callbacks import ModelCheckpoint
import h5py
rows, cols = 19, 19
num_classes = rows * cols
num_games = 10000
encoder = AlphaGoEncoder()
processor = GoDataProcessor(encoder=encoder.name())
generator = processor.load_go_data('train', num_games, use_generator=True)
test_generator = processor.load_go_data('test', num_games, use_generator=True)接下来,我们可以使用本节之前定义的alphago_model函数来加载AlphaGo的策略网络,并采用分类交叉熵损失函数和随机梯度下降法来对这个 Keras 模型进行编译,如代码清单 13-6所示。我们把这个模型称为alphago_sl_policy,以表示它是一个采用监督学习(sl是supervised learning的简写)的策略网络。
代码清单13-6 用Keras创建一个AlphaGo策略网络
input_shape = (encoder.num_planes, rows, cols)
alphago_sl_policy = alphago_model(input_shape, is_policy_net=True)
alphago_sl_policy.compile('sgd', 'categorical_crossentropy', metrics=['accuracy'])现在第一阶段的训练只剩下最后一步了。和第7章一样,使用训练生成器和测试生成器对这个策略网络调用fit_generator。除网络更大、编码器更复杂之外,其他地方都和第6章至第8章完全一样。
训练结束后,我们可以从model和encoder创建一个DeepLearningAgent,并把它存储起来(如代码清单13-7所示),以备后面讨论的两个训练阶段使用。
代码清单13-7 训练一个策略网络并持久化存储
epochs = 200
batch_size = 128
alphago_sl_policy.fit_generator(
generator=generator.generate(batch_size, num_classes),
epochs=epochs,
steps_per_epoch=generator.get_num_samples() / batch_size,
validation_data=test_generator.generate(batch_size, num_classes),
validation_steps=test_generator.get_num_samples() / batch_size,
callbacks=[ModelCheckpoint('alphago_sl_policy_{epoch}.h5')]
)
alphago_sl_agent = DeepLearningAgent(alphago_sl_policy, encoder)
with h5py.File('alphago_sl_policy.h5', 'w') as sl_agent_out:
alphago_sl_agent.serialize(sl_agent_out)为简洁起见,在本章中我们并不需要像AlphaGo论文所说的那样分别训练强策略网络和快策略网络。我们不另外单独训练一个更小更快的策略网络,而是直接使用alphago_sl_agent作为快策略网络。下一节会介绍如何以这个代理为起点进行强化学习,生成一个更强的策略网络。
本文摘自《深度学习与围棋》

这是一本深入浅出且极富趣味的深度学习入门书。本书选取深度学**年来最重大的突破之一 AlphaGo,将其背后的技术和原理娓娓道来,并配合一套基于 BetaGo 的开源代码,带领读者从零开始一步步实现自己的“AlphaGo”。本书侧重实践,深入浅出,庖丁解牛般地将深度学习和AlphaGo这样深奥的话题变得平易近人、触手可及,内容非常精彩。
全书共分为3个部分:第一部分介绍机器学习和围棋的基础知识,并构建一个最简围棋机器人,作为后面章节内容的基础;第二部分分层次深入介绍AlphaGo背后的机器学习和深度学习技术,包括树搜索、神经网络、深度学习机器人和强化学习,以及强化学习的几个高级技巧,包括策略梯度、价值评估方法、演员-评价方法 3 类技术;第三部分将前面两部分准备好的知识集成到一起,并最终引导读者实现自己的AlphaGo,以及改进版AlphaGo Zero。读完本书之后,读者会对深度学习这个学科以及AlphaGo的技术细节有非常全面的了解,为进一步深入钻研AI理论、拓展AI应用打下良好基础。
本书不要求读者对AI或围棋有任何了解,只需要了解基本的Python语法以及基础的线性代数和微积分知识。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
