社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
先直接粘Code
4_2.c
#include <Windows.h>
#include <common.h>
#include "strassen.h"
void print_mutrix(const int *A, int r, int c)
{
int i, j;
printf("-----------------------------------n");
for (i=0; i < r; ++i) {
for (j=0; j < c; ++j) {
printf("%dt", A[i*c + j]);
}
printf("n");
}
printf("-----------------------------------n");
}
//SQUARE-MATRIX-MULTIPLY(A,B)
void square_matrix_multiply(
__in int sm_size,
__in const int *sm_A,
__in const int *sm_B,
__out int *sm_C )
{
int i, j, k;
int p;
for (i = 0; i < sm_size; ++i) {
for (j = 0; j < sm_size; ++j) {
//p = &sm_C[i*sm_size + j];
p = 0;
for (k = 0; k < sm_size; ++k) {
p += (sm_A[i*sm_size + k]) *
(sm_B[k*sm_size + j]);
}
sm_C[i*sm_size + j] += p;
}
}
}
// You must zero all bytes in sm_C before calling the recursive function.
//
//To avoid copying data, we define ROW_STEP:
// Arow1 Arow2
// [----------------------][----------------------]
// .............
//
// A11row1 A12row1 A11row2 A12row2
// [----------][----------][----------][----------]
// |<--------row_step---->|
// .............
#define SM_SUB_AD11(ad, row_step, hs)
(ad)
#define SM_SUB_AD12(ad, row_step, hs)
((ad) + (hs))
#define SM_SUB_AD21(ad, row_step, hs)
((ad) + (row_step)*(hs))
#define SM_SUB_AD22(ad, row_step, hs)
((ad) + (row_step)*(hs) + (hs))
//SQUARE-MATRIX-MULTIPLY-RECURSIVE(A,B)
void square_matrix_multiply_recursive(
__in int sm_size,
__in int row_step,
__in const int *sm_A,
__in const int *sm_B,
__out int *sm_C )
{
int hs = sm_size/2;
if (sm_size == 1) {
*sm_C += (*sm_A) * (*sm_B);
} else {
//C11 = F(A11, B11) + F(A12, B21)
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD11(sm_A, row_step, hs),
SM_SUB_AD11(sm_B, row_step, hs),
SM_SUB_AD11(sm_C, row_step, hs));
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD12(sm_A, row_step, hs),
SM_SUB_AD21(sm_B, row_step, hs),
SM_SUB_AD11(sm_C, row_step, hs));
//C12 = F(A11, B12) + (F(A12, B22)
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD11(sm_A, row_step, hs),
SM_SUB_AD12(sm_B, row_step, hs),
SM_SUB_AD12(sm_C, row_step, hs));
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD12(sm_A, row_step, hs),
SM_SUB_AD22(sm_B, row_step, hs),
SM_SUB_AD12(sm_C, row_step, hs));
//C21 = F(A21, B11) + F(A22, B21)
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD21(sm_A, row_step, hs),
SM_SUB_AD11(sm_B, row_step, hs),
SM_SUB_AD21(sm_C, row_step, hs));
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD22(sm_A, row_step, hs),
SM_SUB_AD21(sm_B, row_step, hs),
SM_SUB_AD21(sm_C, row_step, hs));
//C22 = F(A21, B12) + F(A22, B22)
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD21(sm_A, row_step, hs),
SM_SUB_AD12(sm_B, row_step, hs),
SM_SUB_AD22(sm_C, row_step, hs));
square_matrix_multiply_recursive(
hs, row_step,
SM_SUB_AD22(sm_A, row_step, hs),
SM_SUB_AD22(sm_B, row_step, hs),
SM_SUB_AD22(sm_C, row_step, hs));
}
}
//sm_A = sm_A + sm_B
static void square_matrix_add(
__inout int *sm_A,
__in int *sm_B,
__in int row,
__in int row_step,
__in int col)
{
int i,j;
for (i = 0; i < row; ++i) {
for (j = 0; j < col; ++j) {
sm_A[i*row_step + j] += sm_B[i*row_step + j];
}
}
}
//sm_A = sm_A + sm_B
void square_matrix_sub(
__inout int *sm_A,
__in int *sm_B,
__in int row,
__in int row_step,
__in int col)
{
int i,j;
for (i = 0; i < row; ++i) {
for (j = 0; j < col; ++j) {
sm_A[i*row_step + j] -= sm_B[i*row_step + j];
}
}
}
#define SQUARE_MATRIX_SIZE 512
void func_4_2(void)
{
/*
const int A[4*4] = { 1, 3, 7, 5,
8, 9, 4, 2,
2, 7, 6, 2,
1, 0, 9, 8};
const int B[4*4] = { 6, 8, 4, 2,
10, 0, 8,10,
1, 9, 5, 4,
4, 0,11, 0};
int C[4*4] = {0};
*/
int *A = NULL;
int *B = NULL;
int *C = NULL;
int i = 0;
LARGE_INTEGER t1, t2, freq;
double t_seconds = 0;
QueryPerformanceFrequency(&freq);
A = (int *)malloc(sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
B = (int *)malloc(sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
C = (int *)malloc(sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
if (A == NULL ||
B == NULL ||
C == NULL) {
TRACE("allocate memory fail(size:%d)n",
sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
goto l_exit;
}
//random
for (i = 0; i < SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE; ++i) {
A[i] = rand()%10;
}
for (i = 0; i < SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE; ++i) {
B[i] = rand()%10;
}
//print_mutrix(A, SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE);
//print_mutrix(B, SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE);
printf("SQUARE-MATRIX-MULTIPLY(A,B)n");
memset(C, 0, sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
QueryPerformanceCounter(&t1);
square_matrix_multiply(SQUARE_MATRIX_SIZE, A, B, C);
QueryPerformanceCounter(&t2);
t_seconds = ((double)(t2.QuadPart - t1.QuadPart))/((double)freq.QuadPart);
printf("Cost %f secondsn", t_seconds);
//print_mutrix(C, SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE);
printf("SQUARE-MATRIX-MULTIPLY-RECURSIVE(A,B)n");
memset(C, 0, sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
QueryPerformanceCounter(&t1);
square_matrix_multiply_recursive(
SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE,
A, B, C);
QueryPerformanceCounter(&t2);
t_seconds = ((double)(t2.QuadPart - t1.QuadPart))/((double)freq.QuadPart);
printf("Cost %f secondsn", t_seconds);
//print_mutrix(C, SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE);
printf("SQUARE-MATRIX-MULTIPLY-STRASSEN(A,B)n");
memset(C, 0, sizeof(int) * SQUARE_MATRIX_SIZE * SQUARE_MATRIX_SIZE);
QueryPerformanceCounter(&t1);
{
sm_t sm_A, sm_B, sm_C;
sm_mem_t mem;
sm_A.add_start = A;
sm_A.cols = SQUARE_MATRIX_SIZE;
sm_A.rows = SQUARE_MATRIX_SIZE;
sm_A.row_step = SQUARE_MATRIX_SIZE;
sm_B.add_start = B;
sm_B.cols = SQUARE_MATRIX_SIZE;
sm_B.rows = SQUARE_MATRIX_SIZE;
sm_B.row_step = SQUARE_MATRIX_SIZE;
sm_C.add_start = C;
sm_C.cols = SQUARE_MATRIX_SIZE;
sm_C.rows = SQUARE_MATRIX_SIZE;
sm_C.row_step = SQUARE_MATRIX_SIZE;
if (square_matrix_alloc_mem(SQUARE_MATRIX_SIZE, &mem)) {
TRACE("Out of memoryn");
} else {
square_matrix_strassen_recursive(
&mem,
&sm_A,
&sm_B,
&sm_C);
square_matrix_free_mem(&mem);
}
}
QueryPerformanceCounter(&t2);
t_seconds = ((double)(t2.QuadPart - t1.QuadPart))/((double)freq.QuadPart);
printf("Cost %f secondsn", t_seconds);
//print_mutrix(C, SQUARE_MATRIX_SIZE, SQUARE_MATRIX_SIZE);
l_exit:
if (A != NULL) {
free(A);
}
if (B != NULL) {
free(B);
}
if (C != NULL) {
free(C);
}
}strassen.h
#ifndef __IA_STRASSEN_H__
#define __IA_STRASSEN_H__
//To avoid copying data, we define ROW_STEP:
// Arow1 Arow2
// [----------------------][----------------------]
// .............
//
// A11row1 A12row1 A11row2 A12row2
// [----------][----------][----------][----------]
// |<--------row_step---->|
// .............
typedef
struct _sm_t {
int *add_start;
int rows;
int cols;
int row_step;
}sm_t;
typedef
struct _sm_mem_t {
char *addr_start;
size_t len;
size_t usedlen;
}sm_mem_t;
//-1 fail
//0 success
int square_matrix_alloc_mem(
__in size_t size,
__inout sm_mem_t *mem);
void square_matrix_free_mem(
__in sm_mem_t *mem);
//return
// -1 -- fail
// 0 -- success
int square_matrix_strassen_recursive(
__in sm_mem_t *mem,
__in sm_t *sm_A,
__in sm_t *sm_B,
__inout sm_t *sm_C);
#endif#include <common.h>
#include <math.h>
#include <Windows.h>
#include "strassen.h"
#define SM_SUB11(sm) sm[0]
#define SM_SUB12(sm) sm[1]
#define SM_SUB21(sm) sm[2]
#define SM_SUB22(sm) sm[3]
//2. 构造加减法运算
//sm_C = sm_A + sm_B
//no check here
static void square_matrix_add(
__in sm_t *sm_A,
__in sm_t *sm_B,
__inout sm_t *sm_C)
{
int i,j;
for (i = 0; i < sm_A->rows; ++i) {
for (j = 0; j < sm_A->cols; ++j) {
sm_C->add_start[i*sm_C->row_step + j] =
sm_A->add_start[i*sm_A->row_step + j] +
sm_B->add_start[i*sm_B->row_step + j];
}
}
}
//sm_C = sm_A - sm_B
//no check here
static void square_matrix_sub(
__in sm_t *sm_A,
__in sm_t *sm_B,
__inout sm_t *sm_C)
{
int i,j;
for (i = 0; i < sm_A->rows; ++i) {
for (j = 0; j < sm_A->cols; ++j) {
sm_C->add_start[i*sm_C->row_step + j] =
sm_A->add_start[i*sm_A->row_step + j] -
sm_B->add_start[i*sm_B->row_step + j];
}
}
}
//-1 fail
//0 success
int square_matrix_alloc_mem(
__in size_t size,
__inout sm_mem_t *mem)
{
size_t mem_size = 0;
int i = 0;
int seven = 1;
while(size > 1) {
size = size/2;
mem_size += size*size * seven;
seven *= 7;
i++;
}
mem_size = sizeof(int) * 17 * mem_size;
mem_size += 0x3ff;
mem_size -= mem_size%0x400;
TRACE("square matrix size %d memory size 0x%08Xn", size, mem_size);
if (mem_size == 0) {
return 0;
}
//mem->addr_start = (char *) malloc(mem_size);
mem->addr_start = (char *) VirtualAlloc(
NULL,
mem_size,
MEM_COMMIT,
PAGE_READWRITE);
if (mem->addr_start == NULL) {
TRACE("Last error %dn", GetLastError());
return -1;
}
//memset(mem->addr_start, 0, mem_size);
mem->len = mem_size;
mem->usedlen = 0;
return 0;
}
void square_matrix_free_mem(
__in sm_mem_t *mem)
{
if (mem->addr_start != NULL) {
VirtualFree(mem->addr_start, 0, MEM_RELEASE);
}
}
//return
// -1 -- fail
// 0 -- success
int square_matrix_strassen_recursive(
__in sm_mem_t *mem,
__in sm_t *sm_A,
__in sm_t *sm_B,
__inout sm_t *sm_C)
{
int ret = 0;
int sm_size = sm_A->rows;
int hs = sm_size/2;
sm_t Asub[4];
sm_t Bsub[4];
sm_t Csub[4];
sm_t S[10];
sm_t P[7];
int i = 0;
if (sm_size == 1) {
*(sm_C->add_start) +=
(*(sm_A->add_start)) * (*(sm_B->add_start));
return 0;
}
//check memory
if (17 * (hs * hs) * sizeof(int) > (mem->len - mem->usedlen)) {
ret = -1;
goto l_exit;
}
//malloc memory for S[]
memset(S, sizeof(S), 0);
for (i = 0; i < sizeof(S)/sizeof(sm_t); ++i) {
//S[i].add_start = (int *)malloc(sizeof(int) * hs * hs);
S[i].add_start = (int *)(mem->addr_start + mem->usedlen);
mem->usedlen += sizeof(int) * hs * hs;
if (S[i].add_start == NULL) {
ret = -1;
goto l_exit;
}
//TODO: useless
memset(S[i].add_start, 0, sizeof(int) * hs * hs);
S[i].row_step = hs;
S[i].rows = hs;
S[i].cols = hs;
}
//malloc memory for P[]
memset(P, sizeof(P), 0);
for (i = 0; i < sizeof(P)/sizeof(sm_t); ++i) {
//P[i].add_start = (int *)malloc(sizeof(int) * hs * hs);
P[i].add_start = (int *)(mem->addr_start + mem->usedlen);
mem->usedlen += sizeof(int) * hs * hs;
if (P[i].add_start == NULL) {
ret = -1;
goto l_exit;
}
memset(P[i].add_start, 0, sizeof(int) * hs * hs);
P[i].row_step = hs;
P[i].rows = hs;
P[i].cols = hs;
}
for (i = 0; i < 4; ++i) {
Asub[i].row_step = sm_A->row_step;
Asub[i].rows = hs;
Asub[i].cols = hs;
Asub[i].add_start = sm_A->add_start +
(i/2) * sm_A->row_step * hs + (i%2) * hs;
Bsub[i].row_step = sm_B->row_step;
Bsub[i].rows = hs;
Bsub[i].cols = hs;
Bsub[i].add_start = sm_B->add_start +
(i/2) * sm_B->row_step * hs + (i%2) * hs;
Csub[i].row_step = sm_C->row_step;
Csub[i].rows = hs;
Csub[i].cols = hs;
Csub[i].add_start = sm_C->add_start +
(i/2) * sm_C->row_step * hs + (i%2) * hs;
}
//Get S[]
//S1=B12 - B22
square_matrix_sub(&SM_SUB12(Bsub), &SM_SUB22(Bsub), &S[0]);
//S2=A11 + A12
square_matrix_add(&SM_SUB11(Asub), &SM_SUB12(Asub), &S[1]);
//S3=A21 + A22
square_matrix_add(&SM_SUB21(Asub), &SM_SUB22(Asub), &S[2]);
//S4=B21 - B11
square_matrix_sub(&SM_SUB21(Bsub), &SM_SUB11(Bsub), &S[3]);
//S5=A11 + A22
square_matrix_add(&SM_SUB11(Asub), &SM_SUB22(Asub), &S[4]);
//S6=B11 + B22
square_matrix_add(&SM_SUB11(Bsub), &SM_SUB22(Bsub), &S[5]);
//S7=A12 - A22
square_matrix_sub(&SM_SUB12(Asub), &SM_SUB22(Asub), &S[6]);
//S8=B21 + B22
square_matrix_add(&SM_SUB21(Bsub), &SM_SUB22(Bsub), &S[7]);
//S9=A11 - A21
square_matrix_sub(&SM_SUB11(Asub), &SM_SUB21(Asub), &S[8]);
//S10=B11 + B12
square_matrix_add(&SM_SUB11(Bsub), &SM_SUB12(Bsub), &S[9]);
//Get P
//P1= A11 * S1
if (ret = square_matrix_strassen_recursive(
mem,
&SM_SUB11(Asub),
&S[0],
&P[0])) {
goto l_exit;
}
//P2 = S2 * B22
if (ret = square_matrix_strassen_recursive(
mem,
&S[1],
&SM_SUB22(Bsub),
&P[1])) {
goto l_exit;
}
//P3 = S3 * B11
if (ret = square_matrix_strassen_recursive(
mem,
&S[2],
&SM_SUB11(Bsub),
&P[2])) {
goto l_exit;
}
//P4 = A22 * S4
if (ret = square_matrix_strassen_recursive(
mem,
&SM_SUB22(Asub),
&S[3],
&P[3])) {
goto l_exit;
}
//P5 = S5 * S6
if (ret = square_matrix_strassen_recursive(
mem,
&S[4],
&S[5],
&P[4])) {
goto l_exit;
}
//P6 = S7 * S8
if (ret = square_matrix_strassen_recursive(
mem,
&S[6],
&S[7],
&P[5])) {
goto l_exit;
}
//P7 = S9 * S10
if (ret = square_matrix_strassen_recursive(
mem,
&S[8],
&S[9],
&P[6])) {
goto l_exit;
}
//Get the result
//C11 = P5 + P4 - P2 + P6
square_matrix_add(&P[4], &P[3], &SM_SUB11(Csub));
square_matrix_sub(&SM_SUB11(Csub), &P[1], &SM_SUB11(Csub));
square_matrix_add(&SM_SUB11(Csub), &P[5], &SM_SUB11(Csub));
//C12 = P1 + P2
square_matrix_add(&P[0], &P[1], &SM_SUB12(Csub));
//C21 = P3 + P4
square_matrix_add(&P[2], &P[3], &SM_SUB21(Csub));
//C22 = P5 + P1 - P3 - P7
square_matrix_add(&P[4], &P[0], &SM_SUB22(Csub));
square_matrix_sub(&SM_SUB22(Csub), &P[2], &SM_SUB22(Csub));
square_matrix_sub(&SM_SUB22(Csub), &P[6], &SM_SUB22(Csub));
l_exit:
/*
//free memory
for ( i = 0; i < sizeof(S)/sizeof(sm_t); ++i) {
if (S[i].add_start)
free(S[i].add_start);
}
for ( i = 0; i < sizeof(P)/sizeof(sm_t); ++i) {
if (P[i].add_start)
free(P[i].add_start);
}*/
if (ret) {
TRACE("strassen failn");
}
return ret;
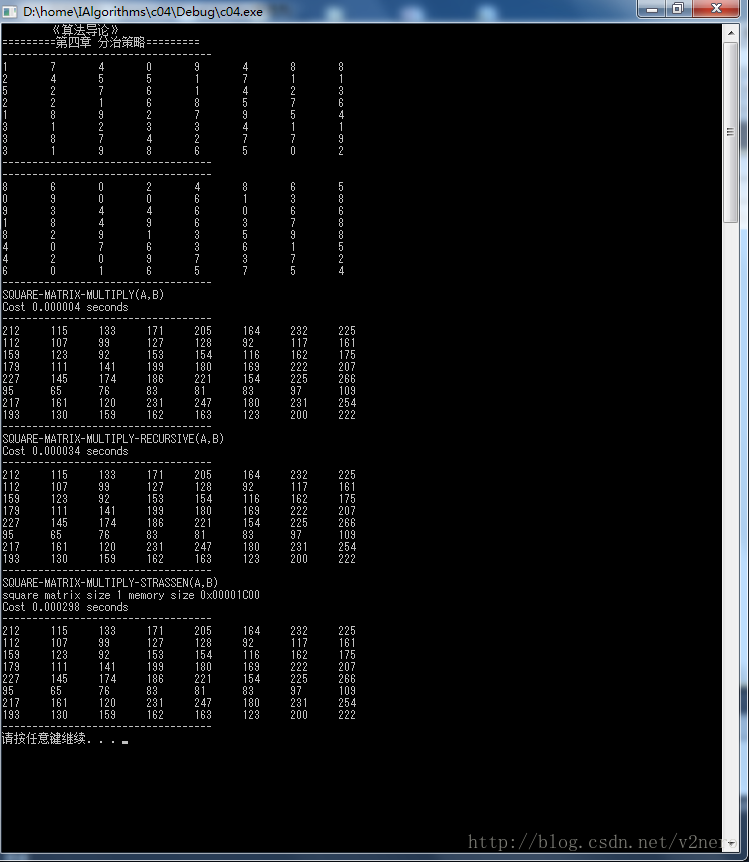
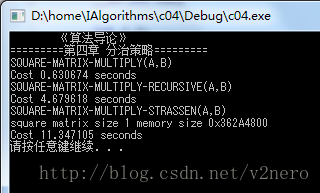
}感觉从矩阵维数从2*2 到 1024 * 1024都是朴素法最好,可能是自己水平有限,没做优化,下图是512*512的时间消耗, 1024*1024 strassen算法暴内存了
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!