社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
转载:
https://segmentfault.com/a/1190000019947618
https://www.cnblogs.com/X-knight/p/9157814.html
共识算法看了又忘,一直觉得理解的不够到位,特此记录,出错处望指正,不胜感激。
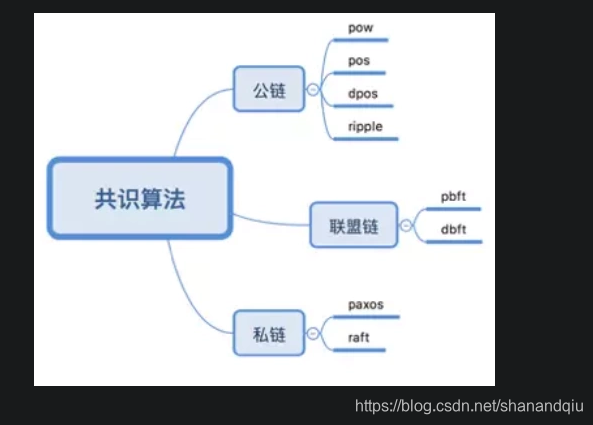
先说结论 不同共识算法的特点:
PoW 拼命搬砖
PoS 股份制 谁股份多谁牛x
DPoS 人大代表制度
Paxos,Raft,PBFT 队列操练,通过相互间的消息与口令达成步调的一致,其余人以排头为基准进行自我调整。
Ripple 初始状态有一个特殊的节点列表,就像一个俱乐部,要接纳一个新成员,必须由51%的俱乐部会员投票通过。
分布式系统的核心问题:一致性问题 共识问题
引起不一致的因素:
节点间网络通信的不可靠,消息延迟,消息乱序,内容错误.
节点处理时间无法保证: 结果可能错误,或者节点宕机.
FLP不可能原理:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。(节点失效不可避免,所以不能共识)
CAP原理:分布式计算系统不可能同时确保以下三个特性:强一致性(Consistency)、可用性(Availability)和分区容忍性(Partition),设计中往往需要弱化对某个特性的保证。
强一致性:所有节点在同一时刻能够看到相同的数据
可用性:在有限时间内,任何非失败节点都能应答请求;
分区容忍性:网络可能发生分区,即节点之间的通信不可保障。
(你说网络被划分2半,一半网络给A10元 另一半网络给B10元 ,要么系统不可用,因为交易不会被处理,如果可用,就不能达到一致性,因为一半网络完成交易1 另一半网络完成交易2)
所以分布式系统可以一定程度接受弱一致性或弱可用性或者弱分区容错性。
针对如上不稳定的情况,把故障分为:非拜占庭错误(出现消息不响应,但是消息不会被篡改)和拜占庭错误(存在伪造消息的情况).
共识算法:
BFT类 针对拜占庭错误有: PBFT 确定性算法,POW 工作量证明的概率算法等.
CFT类 针对非拜占庭错误有: PAXOS 算法.Raft算法(容错较好,处理快,保证不超过一半节点故障)
在比特币系统中,大约每10分钟进行一轮算力竞赛,竞赛的胜利者,就获得一次记账的权力,并向其他节点同步新增账本信息。然而,在一个去中心化的系统中,谁有权判定竞争的结果呢?比特币系统是通过一个称为“工作量证明”(Proof of Work,PoW)的机制完成的。
举个例子,给定字符串“blockchain”,我们给出的工作量要求是,可以在这个字符串后面连接一个称为nonce的整数值串,对连接后的字符串进行SHA256哈希运算,如果得到的哈希结果(以十六进制的形式表示)是以若干个0开头的,则验证通过。为了达到这个工作量证明的目标,我们需要不停地递增nonce值,对得到的新字符串进行SHA256哈希运算。按照这个规则,需要经过2688次计算才能找到前3位均为0的哈希值,而要找到前6位均为0的哈希值,则需进行620969次计算。
blockchain1 → 4bfb943cba9fb9926df93f33c17d64b378d56714e8a29c6ba8bdc9690cea8e27
blockchain2 → 01181212a283e760929f6b1628d903127c65e6fb5a9ad7fe94b790e699269221 ……
blockchain515 → 0074448bea8027bebd6333d3aa12fd11641e051911c5bab661a9b849b83958a7……
blockchain2688 → 0009b257eb8cf9eba179ab2be74d446fa1c59f0adfa8814260f52ae0016dd50f……
blockchain48851: 00000b3d96b4db1a976d3a69829aabef8bafa35ab5871e084211a16d3a4f385c……
blockchain6200969: 000000db7fa334aef754b51792cff6c880cd286c5f490d5cf73f658d9576d424比特币的共识算法不适合于私有链和联盟链。其原因首先是它是一个最终一致性共识算法,不是一个强一致性共识算法。第二个原因是其共识效率低。提供共识效率又会牺牲共识协议的安全性。
PoS类似于财产储存在银行,这种模式会根据你持有数字货币的量和时间,分配给你相应的利息。
简单来说,就是一个根据你持有货币的量和时间,给你发利息的一个制度,在股权证明PoS模式下,有一个名词叫币龄,每个币每天产生1币龄,比如你持有100个币,总共持有了30天,那么,此时你的币龄就为3000,这个时候,如果你发现了一个PoS区块,你的币龄就会被清空为0。你每被清空365币龄,你将会从区块中获得0.05个币的利息(假定利息可理解为年利率5%),那么在这个案例中,利息 = 3000 * 5% / 365 = 0.41个币,这下就很有意思了,持币有利息。
比特股的DPoS机制,中文名叫做股份授权证明机制(又称受托人机制),它的原理是让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。从某种角度来看,DPOS有点像是议会制度或人民代表大会制度。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。DPOS的出现最主要还是因为矿机的产生,大量的算力在不了解也不关心比特币的人身上,类似演唱会的黄牛,大量囤票而丝毫不关心演唱会的内容。
对于pbft算法,共识过程就是:老大向我发送命令时,当我认为老大的命令是有问题时,我会拒绝执行。就算我认为老大的命令是对的,我还会问下团队的其它成员老大的命令是否是对的,只有大多数人(2f+1)都认为老大的命令是对的时候,我才会去执行命令。那什么时候重选老大呢?老大挂了当然要重选,如果大多数人都认为老大不称职或者有问题时,我们也会重新选择老大。
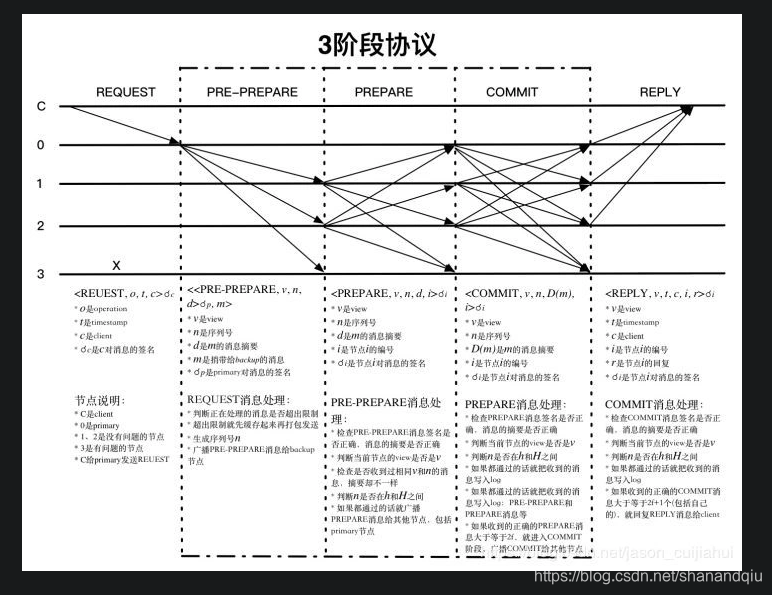
高低水位的作用是防止节点间异步水平过大
Commit阶段
Ripple的共识达成发生在验证节点之间,每个验证节点都预先配置了一份可信任节点名单,称为UNL(Unique Node List)。在名单上的节点可对交易达成进行投票。每隔几秒,Ripple网络将进行如下共识过程:
1)每个验证节点会不断收到从网络发送过来的交易,通过与本地账本数据验证后,不合法的交易直接丢弃,合法的交易将汇总成交易候选集(candidate set)。交易候选集里面还包括之前共识过程无法确认而遗留下来的交易。
2)每个验证节点把自己的交易候选集作为提案发送给其他验证节点。
3)验证节点在收到其他节点发来的提案后,如果不是来自UNL上的节点,则忽略该提案;如果是来自UNL上的节点,就会对比提案中的交易和本地的交易候选集,如果有相同的交易,该交易就获得一票。在一定时间内,当交易获得超过50%的票数时,则该交易进入下一轮。没有超过50%的交易,将留待下一次共识过程去确认。
4)验证节点把超过50%票数的交易作为提案发给其他节点,同时提高所需票数的阈值到60%,重复步骤3)、步骤4),直到阈值达到80%。
5)验证节点把经过80%UNL节点确认的交易正式写入本地的账本数据中,称为最后关闭账本(Last Closed Ledger),即账本最后(最新)的状态。
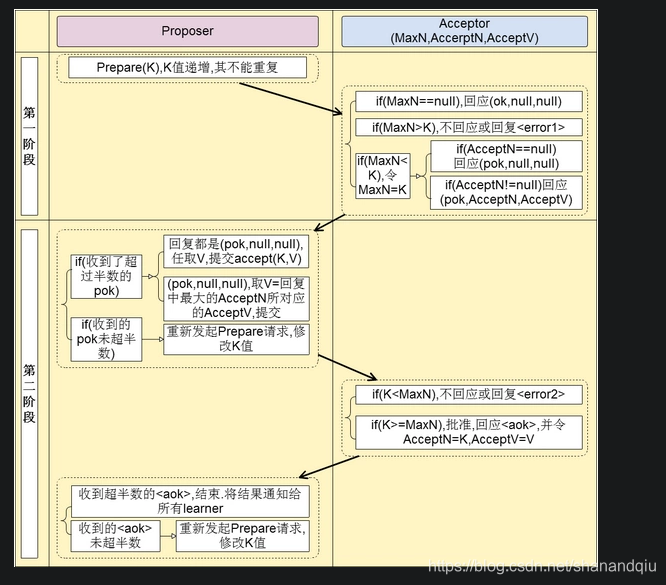
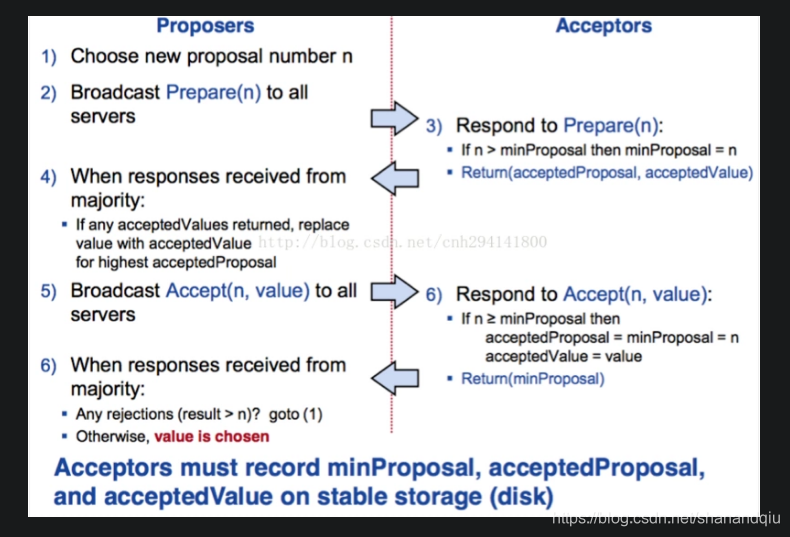
2PC 准备阶段解决大家对哪个提案进行投票的问题 提交阶段解决再确认最终值的问题
Phase 1. Prepare
(a) A proposer selects a proposal number n and sends a prepare request with number n to a majority of acceptors.
(b) If an acceptor receives a prepare request with number n greater than that of any prepare request to which it has already responded, **then it responds to the request with a promise not to accept any more proposals numbered less than n and with the highest-numbered pro- posal (if any) that it has accepted.**
1).获取一个proposal number, n;
2).提议者向所有节点广播prepare(n)请求;
3).接收者(Acceptors比较善变,如果还没最终认可一个值,它就会不断认同提案号最大的那个方案)比较n和minProposal,如果n>minProposal,表示有更新的提议minProposal=n;如果此时该接受者并没有认可一个最终值,那么认可这个提案,返回OK。如果此时已经有一个accptedValue, 将返回(acceptedProposal,acceptedValue);
4).提议者接收到过半数请求后,如果发现有acceptedValue返回,表示有认可的提议,保存最高acceptedProposal编号的acceptedValue到本地
Phase 2. Accept
(a) If the proposer receives a response to its prepare requests (numbered n) from a majority of acceptors, then it sends an accept request to each of those acceptors for a proposal numbered n with a value v, **where v is the value of the highest-numbered proposal among the responses, or is any value if the responses reported no proposals.**
(b) If an acceptor receives an accept request for a proposal numbered n, it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
5)广播accept(n,value)到所有节点;
6).接收者比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;
否则,拒绝并且返回minProposal
7).提议者接收到过半数请求后,如果发现有返回值>n,表示有更新的提议,跳转1(重新发起提议);否则value达成一致。

Raft 在实际应用场景中的一致性更多的是体现在不同节点之间的数据一致性,客户端发送请求到任何一个节点都能收到一致的返回,当一个节点出故障后,其他节点仍然能以已有的数据正常进行。在选主之后的复制日志就是为了达到这个目的。
Raft 是能够实现分布式系统强一致性的算法,每个系统节点有三种状态 Follower,Candidate,Leader。实现 Raft 算法两个最重要的事是:选主和复制日志
etcd
Raft动画演示: http://thesecretlivesofdata.c...
参考
1 FLP不可能原理/CAP原理/ACID原则 https://blog.csdn.net/bloodsu...
2 图解分布式一致性协议Paxos https://www.cnblogs.com/hugb/...
3 共识算法:Raft https://www.jianshu.com/p/8e4...
4 [区块链] 共识算法之争(PBFT,Raft,PoW,PoS,DPoS,Ripple) https://www.cnblogs.com/X-kni...
5 共识算法-PBFT https://blog.csdn.net/jason_c...
6 PBFT http://ug93tad.github.io/pbft/
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
