社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
A. 不可能有这样的操作,即把一个文件系统同时通过 NFS 和 SMB协议共享给多个主机访问。
B. 主机 a 的用户通过NFS 协议创建的文件或者目录,另一个主机 b的用户不能通过 SMB 协议将其删除。
C. 在同一个目录下,主机 a 通过 NFS 协议看到文件 file.txt,主机b 通过 SMB 协议也看到文件 file.txt,那么它们是同一个文件。
D. 主机 a 通过 NFS 协议,以及主机 b 通过 SMB 协议,都可以通过主机端的数据缓存,提升文件访问性能。
参考答案:A,B,C
ConcurrentHashMap 的实现方式是锁桶。 CocurrentHashMap 将hash表分为16个桶(默认值),诸如诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。ConcurrentHashMap是线程安全的:JDK1.7版本: 容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这 样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想,见下图:
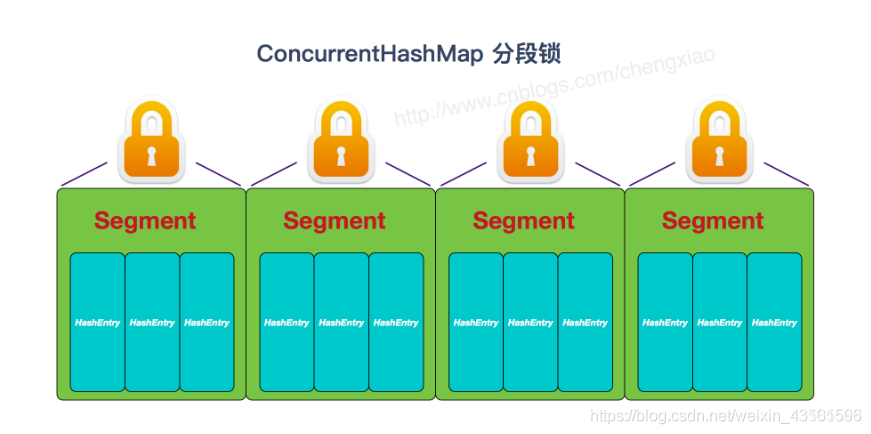
每一个segment都是一个HashEntry<K,V>[] table, table中的每一个元素本质上都是一个HashEntry的单向队列(原理和hashMap一样)。比如table[3]为首节点,table[3]->next为节点1,之后为节点2,依次类推。
JDK1.8版本:做了2点修改,见下图:
取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,并发控制使用Synchronized和CAS来操作
将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构.
原文链接:https://blog.csdn.net/weixin_43185598/article/details/87938882
jdk1.8 的新特性: lambda 表达式,方法引用以及多重Annotation ,API 集成,流式编程,函数接口,Map以及全新日期。
java 虚拟机主要分为以下一个区:
方法区:
对象创建方法,对象的内存分配,对象的访问定位。
new 一个对象
6.数据库用过么?用的啥数据库,mysql用的啥引擎?为啥数据库底层用B+树不用红黑树?
参考答案:恢复到任意时间点以定时的做全量备份,以及备份增量的 binlog 日志为前提。恢复到任意时间点首先将全量备份恢复之后,再此基础上回放增加的 binlog 直至指定的时间点。
string类的用法,string a=Hello string a = new string(hello)创建的流程
参考答案:key 太长会导致一个页当中能够存放的 key 的数目变少,间接导致索引树的页数目变多,索引层次增加,从而影响整体查询变更的效率。
参考答案:
基础数据结构的理解和编码能力
递归使用
说明:
如果按照中序遍历的顺序遍历一棵二叉搜索树,遍历序列的数值是递增排序的。上图中的二叉搜索树的中序遍历序列为{2,3,4,5,6,7,8},因此,只需要用中序遍历算法遍历一棵二叉搜索树,就很容易找出它的第k大结点。
?
public class Demo1 {
class BinaryTreeNode{
int val;
BinaryTreeNode left;
BinaryTreeNode right;
public BinaryTreeNode(int val) {
this.val = val;
}
}
public static void main(String[] args) {
Demo1 demo = new Demo1();
BinaryTreeNode root = demo.new BinaryTreeNode(5);
BinaryTreeNode a = demo.new BinaryTreeNode(3);
BinaryTreeNode b = demo.new BinaryTreeNode(7);
BinaryTreeNode c = demo.new BinaryTreeNode(2);
BinaryTreeNode d = demo.new BinaryTreeNode(4);
BinaryTreeNode e = demo.new BinaryTreeNode(6);
BinaryTreeNode f = demo.new BinaryTreeNode(8);
root.left = a;
root.right = b;
a.left = c;
a.right = d;
b.left = e;
b.right = f;
BinaryTreeNode k = KthNode(root,3);
System.out.println(k.val);
}
static int index=0;
static BinaryTreeNode KthNode(BinaryTreeNode pRoot,int k) {
if(pRoot==null || k<=0)
return null;
return getKthNode(pRoot,k);
}
private static BinaryTreeNode getKthNode(BinaryTreeNode pRoot,int k) {
BinaryTreeNode KthNode = null;
if(pRoot.left != null)//如果该节点有左孩子,就一直递归到左叶子节点
KthNode = getKthNode(pRoot.left,k);
if(KthNode==null) {
index++; //中序遍历的计数
if(k==index)
KthNode = pRoot;
}
if(KthNode==null && pRoot.right!=null)
//如果该节点有右孩子,就递归到右孩子
KthNode = getKthNode(pRoot.right,k);
return KthNode;
}
}
? 示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
说明:
给定的 n 保证是有效的。
要求:
只允许对链表进行一次遍历。
参考答案:
我们可以使用两个指针而不是一个指针。第一个指针从列表的开头向前移动 n+1 步,而第二个指针将从列表的开头出发。现在,这两个指针被 n 个结点分开。我们通过同时移动两个指针向前来保持这个恒定的间隔,直到第一个指针到达最后一个结点。此时第二个指针将指向从最后一个结点数起的第 n 个结点。我们重新链接第二个指针所引用的结点的 next 指针指向该结点的下下个结点。
参考代码:
?
public ListNode removeNthFromEnd(ListNode head, int n)
{
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode first = dummy;
ListNode second = dummy;
// Advances first pointer so that the gap between first
and second is n nodes apart
for (int i = 1; i <= n + 1; i++) {
first = first.next;
}
// Move first to the end, maintaining the gap
while (first != null) {
first = first.next;
second = second.next;
}
second.next = second.next.next;
return dummy.next;
}
?
复杂度分析:
时间复杂度:O(L),该算法对含有 L 个结点的列表进行了一次遍历。因此时间复杂度为 O(L)。
空间复杂度:O(1),我们只用了常量级的额外空间。
参考答案:
public int[] twoSum(int[] nums, int target) {
if(nums==null || nums.length<2)
return new int[]{0,0};
HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
for(int i=0; i<nums.length; i++){
if(map.containsKey(nums[i])){
return new int[]{map.get(nums[i]), i};
}else{
map.put(target-nums[i], i);
}
}
return new int[]{0,0};
}
分析:空间复杂度和时间复杂度均为 O(n)
A. epoll 和 select 都是 I/O 多路复用的技术,都可以实现同时监听多个 I/O 事件的状态。
B. epoll 相比 select 效率更高,主要是基于其操作系统支持的I/O事件通知机制,而 select 是基于轮询机制。
C. epoll 支持水平触发和边沿触发两种模式。
D. select 能并行支持 I/O 比较小,且无法修改。
参考答案:A,B,C
【延伸】那在高并发的访问下,epoll使用那一种触发方式要高效些?当使用边缘触发的时候要注意些什么东西?
public static void main(String[] args) throws Exception {
BlockingQueue<Integer> queue = new
SynchronousQueue<>();
System. out .print(queue.offer(1) + " ");
System. out .print(queue.offer(2) + " ");
System. out .print(queue.offer(3) + " ");
System. out .print(queue.take() + " ");
System. out .println(queue.size());
}
}
?
A. true true true 1 3
B. true true true (阻塞)
C. false false false null 0
D. false false false (阻塞)
参考答案:D
参考答案:下面是其中一种写法,也可以有不同的写法,比如递归等。供参考。
public class MyLinkedList {
public int data;
public MyLinkedList next;
public MyLinkedList(int data) {
this.data=data;
this.next=null;
}
public MyLinkedList() {
this.data=-1;
this.next=null;
}
参考答案:
基础算法的灵活应用能力(二分法学过数据结构的同学都知道,但不一定往这个方向考虑;如果学过数值计算的同学,应该还要能想到牛顿迭代法并解释清楚)
退出条件设计
二分法
查找,如:
a) high=>1.5
b) low=>1.4
c) mid => (high+low)/2=1.45
d) 1.45*1.45>2 ? high=>1.45 : low => 1.45
public class Main {
public static void main(String[] args) {
//手写二分估值
System.out.println(myCalculate(1.4,1.4,1.5));
//调用函数输出
//System.out.println("----------sqrt= "+Math.sqrt(2.0));
}
//根号2约等于 1.414
private static double myCalculate(double ans,double low,double high) {
double mid = 0;
// 二分法,结束条件:差值小于等于1e-10即可
while(high-low>1e-10){
mid = (high+low)/2.0;
// System.out.println("-----------mid= "+mid+" mid*mid= "+mid*mid);
//二分,逐步向中间值收拢
if(mid*mid <= 2.0){
low=mid;
}
else{
high=mid;
}
}
return mid;
}
}
牛顿迭代法
1.牛顿迭代法的公式为:
xn+1 = xn-f(xn)/f’(xn)
对于本题,需要求解的问题为:f(x)=x2-2 的零点
EPSILON = 0.1 ** 10
def newton(x):
if abs(x ** 2 - 2) > EPSILON:
return newton(x - (x ** 2 - 2) / (2 * x))
else:
return x
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
