社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
起因是最近发现一个很有趣的问题,当我的docker容器迁移到另一台服务器去,因为GPU版本不一致导致项目启动是会报错为:
CUDA error: CUDA_ERROR_NO_DEVICE
no CUDA-capable device is detected
而我使用的框架也同样提示 Decoder not initialized 由此,想写篇博文记录一下相关的问题。
nvidia-docker的安装与启动可以看我上一篇文章中有介绍:
docker学习笔记(9):nvidia-docker安装、部署与使用
这里想分析一下nvidia-docker的原理,原理图可以看如下图: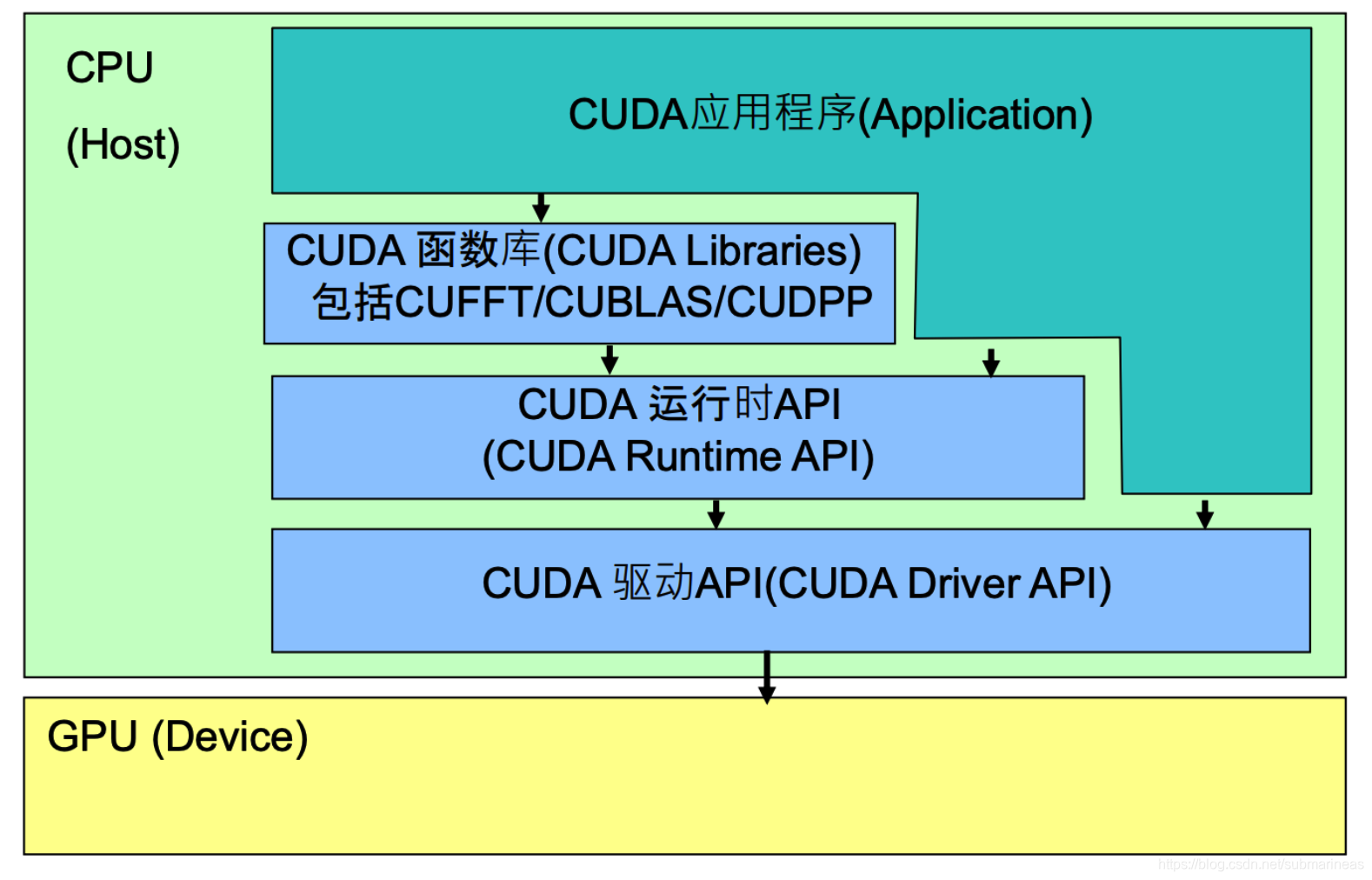
CUDA Driver API:GPU设备的抽象层,通过提供一系列接口来操作GPU设备,性能最好,但编程难度高,一般不会使用该方式开发应用程序。
CUDA Runtime API:对CUDA Driver API进行了一定的封装,调用该类API可简化编程过程,降低开发难度;
CUDA Libraries:是对CUDA Runtime API更高一层的封装,通常是一些成熟的高效函数库,开发者也可以自己封装一些函数库便于使用;
应用程序可调用CUDA Libraries或者CUDA Runtime API来实现功能,当调用CUDA Libraries时,CUDA Libraries会调用相应的CUDA Runtime API,CUDA Runtime API再调用CUDA Driver API,CUDA Driver API再操作GPU设备。
要在容器内操作GPU设备,需要将GPU设备挂载到容器里,Docker可通过–device挂载需要操作的设备,或者直接使用特权模式(不推荐)。NVIDIA Docker是通过注入一个 prestart 的hook 到容器中,在容器自定义命令启动前就将GPU设备挂载到容器中。至于要挂载哪些GPU,可通过NVIDIA_VISIBLE_DEVICES环境变量控制。
不管中间api实现得多复杂,最后还是需要去调用宿主机的CUDA driver,但是这样就会产生很多问题了,如果是两台服务器的驱动不一致,或者并不清楚到底对不对(比如说云环境。。),拿到一台新服务器没有进行版本检查,而导致了问题,可能可以尝试如下方式。
这里会出现的情况有很多,比如说我们首先检查pytorch或者tensorflow的GPU是不是对的,可以运行如下代码。
pytorch的为:
# 直接看当前torch有没有调用cuda
import torch
flag = torch.cuda.is_available()
print(flag)
"""
True
"""
TensorFlow为:
import tensorflow as tf
with tf.device('/cpu:0'):
a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
with tf.device('/gpu:1'):
c = a+b
#注意:allow_soft_placement=True表明:计算设备可自行选择,如果没有这个参数,会报错。
#因为不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,将会报错。
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))
#sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(tf.global_variables_initializer())
print(sess.run(c))
而如果pytorch是False,可以打印出它的预编译版本以及当前版本比对,因为包或者驱动都是向下兼容,如果有Flase,那只能说明cuda没有安装好或者版本不对。
# 打印torch预编译版本与当前版本比对是否一致,或者向下兼容
>>> torch.version.cuda
'10.2'
>>> print(torch.__version__)
1.6.0
但往往有些情况打印了True,然而初始化就是启动不起来,一炮项目就会报如下错误:
program/VideoProcessingFramework/PyNvCodec/TC/src/NvDecoder.cpp:199
NvDecoder.cpp 这个文件的有报错,网上前篇一律都是重装驱动,不过全是宿主机的情况,如果是docker里出现这个,那么可以考虑一下是否显卡驱动是否一致还是多了些东西,因为即使是440.xx与450.xx,个人测试都还是有些差别的,至少服务不跑起来没什么问题,只要一跑根本没有分析结果,这就是很神奇的一件事,cuda对应的表如下:
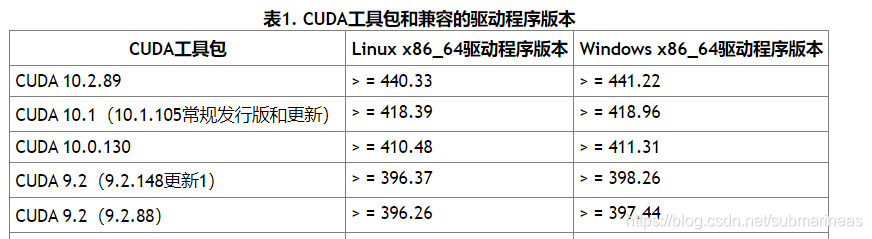
如果出现了上述问题,根据表里的范围,如果驱动的差别不大,比如说440.83到450.xx,那么可以考虑直接将宿主机的驱动程序覆盖容器内的,先找出宿主机上对于显卡驱动特别重要的两个动态库:
(open-mlab) root@Edge-R740:/usr/lib/x86_64-linux-gnu# ls | grep libcuda
libcudart.so.10.1
libcudart.so.10.2
libcuda.so
libcuda.so.1
libcuda.so.450.80.02
(open-mlab) root@Edge-R740:/usr/lib/x86_64-linux-gnu# ls | grep libnvcuvid
libnvcuvid.so
libnvcuvid.so.1
libnvcuvid.so.450.80.02
然后首先删除掉宿主机的这些文件,再一个个docker cp进去:
docker cp libnvcuvid.so.1 nvidia:/usr/lib/x86_64-linux-gnu/
docker cp libcuda.so.1 nvidia:/usr/lib/x86_64-linux-gnu/
然后就能正常载入了。
如果版本差距太大,而pytorch一样可以打印结果为True,那可能是容器内部有装过多个cuda版本,走的runtimes的逻辑,同样会导致和宿主机匹配不上,那么就需要考虑针对当前宿主机版本部署新的镜像进行适配了。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
