社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群

并且,Kafka集群中的消息默认存在磁盘中,默认存放168h,这只是概括的描述,这其中还涉及到生产者的生产策略,和消费者的消费策略,offset的存放,zookeeper的作用(存放分区,副本数量等等)
Topic 是一个逻辑上的概念,具体的存储还是基于 Partition
每个 Topic 可以划分多个分区(每个 Topic 至少有一个分区),同一 Topic 下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset,它是消息在此分区中的唯一编号,Kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 Kafka 只保证在同一个分区内的消息是有序的。
消息是每次追加到对应的 Partition 的后面: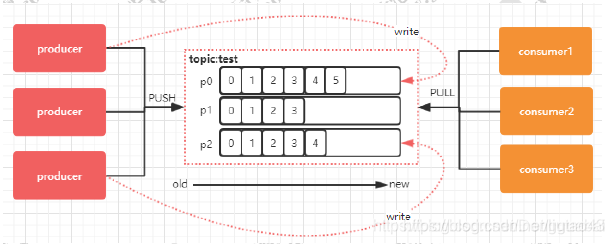
然后分别解压到相关路径,分别解压到集群中
需要准备3个服务器节点;每个节点需提前安装好zookeeper,kafka自带zookeeper,但是最好还是用自己设定的。

export KAFKA_HOME=/root/liutao/kafka
export PATH=$PATH:$KAFKA_HOME/bin
这里之所以创建两个目录,目的是将日志和数据目录分开存放,日志会自动放在logs下面
在$KAFKA_HOME 目录下创建 logs 文件夹,kafka启动关闭等信息的日志
mkdir $KAFKA_HOME/logs
在$KAFKA_HOME 目录下创建data 文件夹,用来存放MQ中的数据
mkdir $KAFKA_HOME/data
修改$KAFKA_HOME/config/server.properties文件来配置kafka
配置文件如下:
# broker.id是kafka broker的编号,集群里每个broker的id需不同,且必须为int整数,三个节点可以是1,2,3,也可以是4,5,6
broker.id=0
# listeners是监听地址,需要提供外网服务的话,要设置本地的IP地址
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# 服务器用来接受请求或者发送响应的线程数
num.network.threads=3
# 服务器用来处理请求的线程数,可能包括磁盘IO
num.io.threads=8
# 发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# 接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区大小
socket.request.max.bytes=104857600
# 这里应该配置的是kafka存放消息数据的位置,但是kafka的详细数据类型是log类型的,很容易和日志弄混淆,我的$KAFKA_HOME是/root/liutao/kafka/
log.dirs=/root/liutao/kafka/data
# num.partitions 为新建Topic的默认Partition数量,partition数量提升,一定程度上可以提升并发性
# 每个主题的日志分区的默认数量。更多的分区允许更大的并行操作,但是它会导致节点产生更多的文件
num.partitions=1
# 每个数据目录用于在启动时恢复日志并在关闭时刷新的线程数,用于在启动时日志恢复,并在关闭时刷新。
# 对于数据目录位于RAID阵列中的安装,建议增大此值。
num.recovery.threads.per.data.dir=1
# 内部__consumer_offsets和__transaction_state两个topic,分组元数据的复制因子,为了保证可用性,在生产上建议设置大于1。
# default.replication.factor为kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务,是在自动创建topic时的默认副本数,可以设置为3
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 数据存活时间
log.retention.hours=168
# 每一个日志段大小的最大值。当到达这个大小时,会生成一个新的片段。
log.segment.bytes=1073741824
# 检查日志段的时间间隔,看是否可以根据保留策略删除它们
log.retention.check.interval.ms=300000
# 设置Zookeeper集群地址,我是在同一个服务器上搭建了kafka和Zookeeper,所以填的本地地址
zookeeper.connect=h71:2181,h72:2181,h73:2181
# 连接到Zookeeper的超时时间
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0
broker.id在三台机器分别设置为0,1,2
kafka-server-start.sh -daemon /root/liutao/kafka/config/server.properties
kafka-server-stop.sh stop
kafka启动和关闭脚本:
#/bin/bash
case $1 in
start)
for h7_node in h71 h72 h73 ;do
ssh -Tq root@$h7_node << 'EOF'
echo "====`hostname`==="
kafka-server-start.sh -daemon /root/liutao/kafka/config/server.properties
EOF
done
;;
stop)
for h7_node in h71 h72 h73 ;do
ssh -Tq root@$h7_node << 'EOF'
echo "====`hostname`==="
kafka-server-stop.sh stop
EOF
done
;;
esac
启动成功: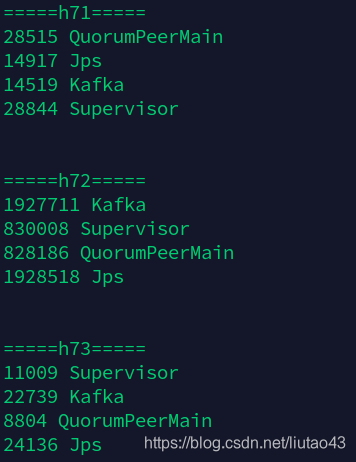
–zookeeper h71:218选项中可以使用任意的zookeeper集群中某台机器的地址
kafka-topics.sh --list --zookeeper h71:2181 # 查看topic
连接zookeeper是因为要向zookeeper集群写入相关数据,分区数量,副本数量等等
指定分区和副本数为2,也可不指定,在kafka配置文件中设置值。
指定topic的名称
kafka-topics.sh --create --zookeeper h71:2181 --topic first --partitions 2 --replication-factor 2
使用脚本查看data目录中的内容:
#/bin/bash
for h7_node in h71 h72 h73;do
ssh -Tq root@$h7_node << 'EOF'
echo "===`hostname`==="
ls $KAFKA_HOME/data
echo -e "n"
EOF
done
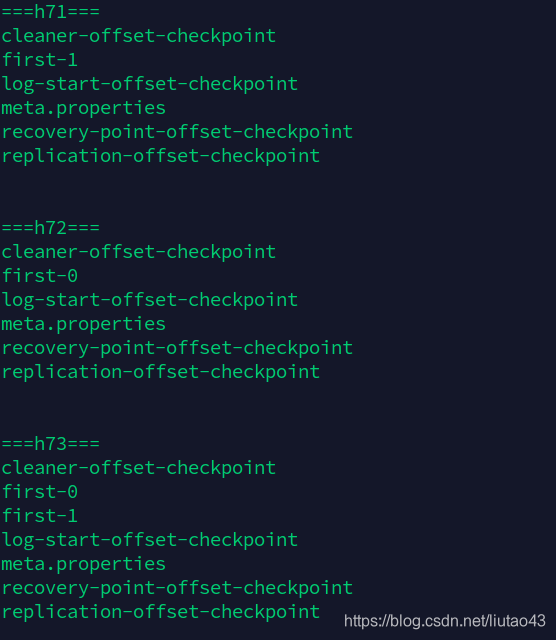
在三台机器下的$KAFKAHOME/data相应目录下的就出现了两个first-0和first-1,0和1分别代表分区,并且副本数量是Leader+Follower数量总和
kafka-topics.sh --zookeeper h71:2181 --describe --topic first

第一行代表分区数量,副本数量
第二行代表:Partition0的Leader在broke.id为1的机器上,其中备份在broke.id为1和2的机器上。
第三行同上
kafka-topics.sh --zookeeper h71:2181 --delete --topic first
利用KAFKA自带的生产者脚本进行测试
kafka-console-producer.sh --broker-list h71:9092 --topic first
利用KAFKA自带的消费者脚本进行测试
kafka-console-consumer.sh --bootstrap-server h71:9092 --topic first
生产者输入
消费者输出
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
