社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
UNIX进程
进程标识符
要想对进程控制,必须得获取进程的标识。每个进程都有一个非负整数表示的唯一进程ID,虽然是唯一的,但是进程ID可以重用。当一个进程终止后,其进程ID就可以再次使用了。
系统中有一些专用的进程。
ID为0的进程通常是调度进程(常常被称为交换进程swapper)。该进程是内核的一部分,它不执行任何磁盘上的程序。
进程ID1通常是init进程。此进程负责在自举内核后启动一个UNIX系统。init通常读与系统有关的初始化文件,并将系统引导到一个状态。init进程绝不会终止,它是一个普通的用户进程,但是它以超级用户特权运行。
#include <unistd.h>
pid_t getpid(void) ; //获取调用进程的进程ID
pid_t getppid(void) ; //获取调用进程的父进程ID
uid_t getuid(void) ; //获取调用进程的实际用户ID
gid_t getgid(void) ; //获取调用进程的实际组ID
进程创建
#include <unistd.h>
pid_t fork(void) ;
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程。
新创建的子进程几乎但不完全与父进程相同。
子进程得到与父进程用户级虚拟地址空间相同的(但是独立的)一份拷贝,包括文本、数据和bss段、堆以及用户栈。子进程还获得与父进程任何打开文件描述符相同的拷贝,这就意味着当父进程调用fork时,子进程可以读写父进程中打开的任何文件。
父进程和新创建的子进程之间最大的区别在于它们有不同的PID。
fork函数被调用一次,但返回两次。两次返回的唯一区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程ID。
例:
#include<unistd.h>
#include<stdio.h>
#include<errno.h>
#include<stdlib.h>
int main()
{
pid_t pid ;
int x = 1 ;
pid = fork() ;
if (pid == 0) /*Child*/
{
printf("child : x=%dn", ++x) ;
exit(0) ;
}
/*Parent*/
printf("parent :x=%dn", --x) ;
exit(0) ;
}
//执行结果:
//parent: x=0
//child: x=2注意:
并发执行。父进程和子进程是并发运行的独立进程。内核能以任何方式交替执行它们的逻辑控制流中的指令。(故此程序的执行结果在不同的系统上可能相反)
相同的但是独立的地址空间。因为父进程和子进程是独立的进程,它们都有自己的私有地址空间。父进程和子进程对x所做的任何改变都是独立的,不会反映在另一个进程的存储器中。
共享文件。当运行这个示例程序时,我们注意到父进程和子进程都把它们的输出显示在屏幕上。原因是子进程继承了父进程所有的打开文件。当父进程调用fork时,stdout文件是被打开的,并指向屏幕。子进程继承了这个文件,因此它的输出也是指向屏幕的。
由于在fork之后经常跟随着exec,所以现在的很多实现并不执行一个父进程数据段、栈和堆的完全复制。而是使用了写时复制(Copy-On-Write, COW)技术。这些区域由父、子进程共享,而且内核将它们的访问权限改变为只读的。如果父、子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储器系统中的一”页”。
fork有下面两种用法:
1、一个父进程希望复制自己,使父子进程同时执行不同的代码段。(开始时只有一个进程,后来fork出了两个)
2、一个进程要执行一个不同的程序。在这种情况下,子进程从fork返回后立即调用exec(创建了一个全新进程)子进程在fork和exec之间可以更改自己的属性。例如I/O重定向,用户ID、信号安排等。
//fork函数示例
//fork就是分支的起点
//之前是一个进程,遇到fork之后便一分为二,成两个进程。
#include<unistd.h>
#include<stdio.h>
#include<errno.h>
#include<stdlib.h>
int glob = 6 ;
char buf[] = "awrite to stdoutn" ;
int
main(int argc, char**argv)
{
int var ;
pid_t pid ;
var = 123;
if (write(STDOUT_FILENO,buf, sizeof(buf)-1) != sizeof(buf)-1)
perror("write error") ;
printf("beforeforkn") ;
if ((pid = fork()) < 0)
perror("fork error") ;
else if (pid == 0) //子进程
{
glob++ ;
var++ ;
}
else //父进程
{
sleep(3) ; //挂起3秒,让子进程先运行
}
//父子进程都有的相同的程序正文
printf("pid = %d, glob= %d, var = %dn", getpid(), glob, var) ;
exit(0);
}【在fork进程时,注意标准I/O的缓冲问题】
write函数不带缓冲的,但标准I/O库是带缓冲的。如果标准输出连到终端设备,则它是行缓冲的(由换行符冲洗),否则它是全缓冲的
若把上面程序的输出重定向到文件:./a.out> test.txt 则"beforeforkn"会输出两次
原因是当将标准输出重定向到一个文件时,标准I/O是全缓冲的。在fork之前调用了printf一次,但当调用fork时,该行数据仍在缓冲区中,然后将父进程数据空间复制到子进程中时,该缓冲区也被复制到子进程中。于是那时父、子进程各自有了带该行内容的标准I/O缓冲区。当每个进程终止时,最终会冲洗其缓冲区中的副本。
文件共享
在重定向父进程的标准输出时,子进程的标准输出也被重定向。fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。父、子进程的每个相同的打开描述符共享一个文件表项。(因为子进程获取了父进程文件指针的副本)
这种共享文件的方式使父、子进程对同一文件使用了一个文件偏移量。如果父、子进程写到同一描述符文件,但又没有任何形式的同步,那么它们的输出就会相互混合。
进程终止
exit函数
进程有下面五种正常终止方式:
1、 执行return语句。(这等效于调用exit)
2、 调用exit函数。(其操作包括调用各终止处理程序,然后关闭所有标准I/O流等。)
3、 调用_exit或_Exit函数。(立即进入内核。此二者为进程提供一种无需运行终止处理程序或信号处理程序而终止的方法。)
4、 进程的最后一个线程在其启动例程中返回。
5、 进程的最后一个线程调用pthread_exit函数。
三种异常终止方式:
1、调用abort。(它产生SIGABRT信号)
2、当进程接收到某些信号时。(比如终止信号)
3、最后一个线程对取消请求作出响应。
当一个进程由于某种原因终止时,内核并不是立即把它从系统中清除。相反,进程被保持在一种已终止的状态中,直到被它的父进程回收。当父进程回收已终止的子进程时,内核将子进程的退出状态传递给父进程,然后抛弃已终止的进程,从此时开始,该进程就不存在了,一个终止了但还未被回收的进程称为僵死进程。
在任意一种情况下,该终止进程的父进程都能用wait或waitpid函数取得其终止状态。
① 若父进程在子进程之前终止,则子进程的父进程都改变为init进程。我们称之为由init进程领养。(在一个进程终止时,内核逐个检查所有活动进程,看它是否还有活的子进程,如果有,则将它子进程的父进程ID更改为1,即init进程的ID)
【init进程的PID为1,并且是在系统初始化时由内核创建的、长时间运行的程序】
② 若子进程在父进程之前终止,则当父进程调用wait或waitpid函数时,可以获得子进程的终止状态信息。(内核为每个终止子进程保存了一定量的信息)
僵死进程:一个已经终止,但是其父进程尚未对其进行善后处理(获取终止子进程的终止状态信息,释放它占用的资源)的进程被称为僵死进程(zombie)。[即:已死,但无人收尸]
由init领养的进程不会变成僵死进程。因为init被编写成无论何时只要有一个子进程终止,init就会调用一个wait函数取得其终止状态。这也就防止了系统中有很多僵死进程。
(这只能做到父进程先死,子进程不会变僵死进程。若子进程先死,则防止僵死进程的责任就交给我们了。---内核在父进程终止时只检查其活着的子进程。)
wait和waitpid函数
【当一个进程正常或异常终止时,内核就向其父进程发送SIGCHLD信号。】
对于这种信号,系统的默认动作是忽略,当然,我们也可以设置为捕捉,并提供一个信号处理函数。
#include <sys/wait.h>
pid_t wait(int *statloc) ; // statloc为返回的终止状态存放处
pid_t waitpid(pid_t pid, int *statloc, int options) ;
父进程调用这两个函数,只要一有子进程终止,则此函数就取得该子进程的终止状态立即返回。否则一直阻塞。(若它没有任何子进程,则立即出错返回)
这两个函数的区别:
① 在一个子进程终止前,wait使其调用者阻塞,而waitpid则有一个选项,可使调用者不阻塞。(options设置为WNOHANG)
② wait只获取在其调用之后的第一个终止子进程,而waitpid则有参数,可控制它所等待的进程。(pid设置为不同的值,有不同的含义。)
防止僵死进程
若在父进程中调用waitpid函数,则它只能获取第一个终止的子进程状态,其他子进程可能变为僵死进程。若在调用waitpid之前就有子进程结束,则更糟。
若在SIGCHLD的信号处理函数中调用waitpid,则效果好一些,但也可能会产生僵死进程。因为若在信号处理函数执行期间,又有多个子进程结束,发出SIGCHLD信号,UNIX系统只投递一次信号。这样会有子进程的终止状态得不到获取。
有效方式1:父进程调用sigaction函数绑定信号SIGCHLD的信号处理函数时,把其选项字段设置为SA_NOCLDWAIT,则可防止僵死子进程。(子进程终止后,内核自动把其终止状态信息丢弃)父进程可随时结束,不必等到所有子进程终止。 详情见UNIX信号博文
有效方式2:调用fork两次以避免僵死进程。
//调用fork两次,以避免僵死进程。
#include<unistd.h>
#include<stdio.h>
#include<errno.h>
#include<stdlib.h>
int
main(void)
{
pid_t pid ;
if ((pid = fork()) < 0)
perror("fork error") ;
else if (pid == 0) //子进程的作用就是创建孙进程,然后把它托付给init进程
{
if((pid = fork()) < 0)
perror("fork error") ;
elseif (pid == 0) //以下就是实际做事的 孙进程1代码段
{
sleep(2) ; //要让子进程先运行完 终止
//打印出其父进程ID
printf("grandchild 1, parent pid = %dn", getppid()) ;
exit(0) ;
}
if((pid = fork()) < 0)
perror("fork error") ;
elseif (pid == 0) //以下就是实际做事的 孙进程2代码段
{
sleep(2) ;
//打印出其父进程ID
printf("grandchild 2, parent pid = %dn", getppid()) ;
exit(0) ;
}
//终止自己,这样init就领养了各孙进程
exit(0) ;
}
//以下是父进程代码段
//父进程需要等待子进程(防止子进程变zombie)但这种等待时间极短(子进程很快便终止了)
if (waitpid(pid, NULL, 0) !=pid)
perror("waitpid error") ;
exit(0) ;
} 一般的父进程要写个循环轮询wait是否出错返回(即轮询所有的子进程是否都已终止),这样父进程必须在所有子进程终止之后才能终止。
而此法:
父进程只需等待一个子进程结束(它会很快终止),而实际工作的进程由子进程fork,然后子进程终止这些孙进程就被init接管了,init可避免它们变为僵死进程。
但需要注意的是:各孙进程在运行前要sleep一下,以便让子进程先终止。(若孙进程先终止,则变zombie)
加载并运行程序
exec函数族
当进程调用一种exec函数时,该进程执行的程序完全替换为新程序。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用一个全新的程序替换了当前进程的正文、数据、堆和栈段。
#include <unistd.h>
int execl (const char*pathname, const char* arg0,………/*(char*)0*/) ;
int execv (const char* pathname,char* const argv[]) ;
函数execl和execv的区别与参数表的传递有关(l表示list,v表示vector)
execl要求将新程序的每个命令行参数都说明为一个单独的参数,这种参数表以空格指针结尾。
execv则先构造一个指向各参数的指针数组,然后将该数组地址作为这个函数的参数。
[注意]
与system函数不同,exec函数族是用一个全新程序替换了当前进程的正文,故当前进程调用excl函数之后的语句不会被执行。
#include <unistd.h>
int execve (const char*pathname, char* const argv[], const char* envp[]) ;
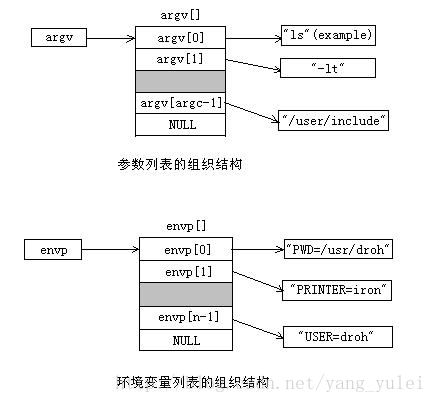
execve函数加载并运行可执行目标文件pathname,且带参数列表argv和环境变量列表envp。
参数列表argv指向一个以null结尾的指针数组,其中每个指针都指向一个参数串。按照惯例,argv[0]是可执行目标文件的名字。
环境变量列表envp指向一个以null结尾的指针数组,其中每个指针指向一个环境变量串,其中每个串都是形如”NAME=VALUE”的名字-值对。
★execve调用加载器加载pathname的程序,当加载器运行时,它创建Linux进程经典虚拟存储器映像(通过创建设置页表)。在可执行文件中段头部表的指导下,加载器将可执行文件的相关内容拷贝到代码和数据段(即填代码段和数据段对应的页表项)。接下来。加载器跳转到程序的入口点,也就是符号_start的地址。在_start地址处的启动代码(startup code)是在目标文件中定义的,对所有C程序都一样。
0x080480c0 <_start>
call __libc_init_first
call _init //初始化例程
call atexit
call main
call _exit //在应用程序返回后,启动代码调用_exit程序,它将控制返回给操作系统
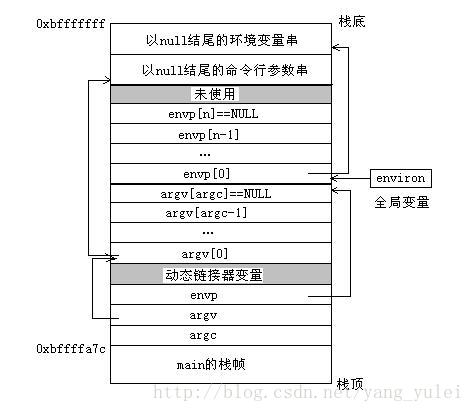
当main开始在一个32位Linux进程中执行时,用户栈有如图所示的组织结构:
Unix提供了几个函数来操作环境数组:
#include <stdlib.h>
char* getenv(constchar *name) ;
getenv函数在环境数组中搜索字符串”name=value”。如果找到了,它就返回一个指向value的指针,否则它就返回NULL。
设置和删除环境字符串的函数:
#include <stdlib.h>
int setenv(const char* name, const char* newvalue, int overwrite) ;
void unsetenv(constchar* name) ;
system函数
在程序中执行一个命令字符串很方便。
ISO C定义了system函数,但其对操作系统的依赖很强。
#include <stdlib.h>
int system(constchar * cmdstring) ;
(其效果相当于在控制台输入命令,这样,可以让我们在程序中用到shell命令)
system函数在实现中调用了fork、exec和waitpid。
使用system而不是直接使用fork和exec的优点是:system进行了所需的各种出错处理以及各种信号处理。(故:忘掉exec函数吧,虽然它有更强大的功能,但一般用system函数足矣。)
我们可以利用system函数起一个与当前进程关联不大的进程(这个进程有独立的exe文件)
与execl函数不同,system函数起了一个子进程,故当前进程调用system函数之后的语句会被正常执行。
[注意]
如果一个进程正以特殊的权限(设置用户或设置组ID)运行,它又想生成另一个进程执行另一个程序,则它应当直接使用fork和exec,而且在fork之后、exec之前要改回到普通权限。设置用户ID或设置组ID程序绝不应调用system函数。
进程时间
时间值(UNIX系统一直使用两种不同的时间值)
① 日历时间
该值是自1970年1月1日以来国际标准时间(UTC)所经过的秒数累计值。这些时间值可以用于记录文件的最近一次的修改时间等。(其计时粒度较大,以秒为单位)
② 进程时间
也被称为CPU时间,用以度量进程使用的中央处理器资源。进程时间以时钟滴答计算。(取每秒钟为50、60或100个滴答。)可用sysconf函数得到每秒钟滴答数。
UNIX使用三个进程时间值:
墙上时钟时间:它是进程运行的时间总量,其值与系统中同时运行的进程数有关。(进程可能被切换,挂起)
用户CPU时间:它是执行用户指令所用的时间。
系统CPU时间:它是该进程中执行内核程序所经历的时间。例如read或write。
用户CPU时间和系统CPU时间之和被称为CPU时间。(它们都是占用CPU的时间,不包括进程被挂起等待的时间。而墙上时钟时间进程生命期的所有时间)
任一进程都可调用times函数以获得它自己及已终止子进程的上述值。
#include <sys/times.h>
clock_t times(struct tms * buf) ;
//返回流逝的墙上时钟时间(单位:时钟滴答数)此值是相对于过去的某一时刻测量的,所以不能用其绝对值,要用两个时间点的差值。
times函数还把用户CPU时间和系统CPU时间填在了buf指向的结构中。
sysconf(_SC_CLK_TCK)返回每秒时钟滴答数。
进程同步
可用信号实现
可用管道实现
小结
进程控制原语
fork 可创建新进程。
exec 可以执行新程序。
exit 处理终止
wait 等待终止。
用fork可以创建新进程,用exec可以执行新程序。exit函数和两个wait函数处理终止和等待终止。这些是我们需要的最基本的进程控制原语。
附:操作进程的工具
Linux系统提供了大量的监控和操作进程的有用工具:
STRACE: 打印一个正在运行的程序和它的子进程调用的每个系统调用的轨迹。(用-static编译你的程序,能得到一个更干净的、不带有大量与共享库相关的输出的轨迹)
PS: 列出当前系统中的进程(包括僵死进程)
TOP: 打印出关于当前进程资源使用的信息。
PMAP: 显示进程的存储器映射。
/proc: 一个虚拟文件系统,以ASII文本格式输出大量内核数据结构的内容,用户程序可以读取这些内容。比如,输入”cat /proc/loadavg”,观察在Linux系统上当前的平均负载。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!