社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
linux kernel:用于管理和分配计算机资源的核心软件。
kernel负责执行以下任务:
现代处理器架构一般允许CPU以至少两种不同的模式运行:用户模式(user mode)和内核模式(kernel mode,有时也称为supervisor mode)。硬件指令允许从一种模式切换成另一种模式。相应地,虚拟内存的区域可以被标记为用户空间(user space)或者内核空间(kernel space)。当运行在user mode时,CPU只能访问属于user space的内存;尝试访问kernel space的内存会产生一个硬件异常。当运行在kernel mode时,CPU可以同时访问user space和kernel space的内存。某些操作只能kernel mode下执行。例如:执行halt指令来关闭系统,访问内存管理器(memory-management)硬件,以及初始化设备I/O操作。将操作系统设置成kernel space,可以确保用户进程不能访问kernel的指令和数据结构。
Shell是一种用于特殊目的的程序,用于读取用户输入的命令行,根据这些命令执行合适的程序。这样的程序有时候被称为命令解释程序(command interpreter)。
login shell这个词用来表示一个进程,该进程在用户第一次登录时会运行特定shell。
在有些操作系统中,command interpreter是kernel不可分割的一部分,在Unix系统中,shell是用户进程。存在很多不同的shells,相同计算机上的不同用户可以同时使用不同的shells。
Shell的作用不仅仅用于交互,还用于shell scripts(shell脚本)。shell scripts是一种包含shell命令的文本文件,是一种编程语言,有:变量、循环、条件语且、I/O命令和函数等。
系统中的每个user都具有唯一性,users可能属于groups。
每个系统中的用户都具有唯一的登录名(login name, username)以及相应的数值型的user ID(UID)。每个用户都在系统的password文件(/etc/passwd)中定义,文件中的一行代表一个用户。每行还包含以下额外信息:
出于管理的目的–尤其是,为了控制文件的访问和其他的系统资源–将users分到groups中是很有用的。每个group都在系统的group文件(/etc/group)中定义,文件中的一行代表一个group,每行还包含以下信息:
有一个用户被称为超级用户(superuser),具有特殊的权限。superuser账号的user ID是0,通常登录名称是root。在一般的UNIX系统中,superuser可以跳过所有的权限检查。因此它可以访问系统中的任意文件,跳过文件的权限检查,可以向系统中的任何用户进程发送信号(signals)。系统管理员使用superuser账户来执行系统中的各种管理任务。
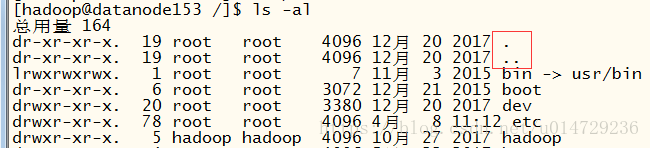
kernel维护一个层级目录结构,将系统中的所有文件组织到一起。根目录(root directory)的名称是/。所有目录和文件都是根目录的子目录(文件)。
在文件系统中,每个文件都有一个type,表示它是哪种类型的文件。这些文件类型中有一种类型是普通数据文件,称为regular(or plain)files。而其他的文件类型包括设备(device)、管道(pipes)、套接字(scoket)、目录(directories)和符号链接(symbolic links)。
术语 文件(file) 经常用于表示任何类型的文件,而不仅仅是一个regular file。
目录(directory)是一种特别的文件,它的内容以表的形式存在,包含文件的文件名和引用。文件名加上引用的结合被称为链接(link,又叫hard link),且文件可以拥有多个链接(link)和名称,可以在相同目录或者不同的目录中。
目录中包含的链接可以指向文件或者其他的目录。每个目录包含至少两个条目:
除了根目录,其他的目录都具有父级目录。对于根目录,**…**指向根目录自己。
符号链接(Symbolic links)又叫软链接(soft link),是一类特殊的文件,这个文件包含了另一个文件的路径名(绝对路径或者相对路径)。路径可以是任意文件或目录,可以链接不同文件系统的文件。(链接文件可以链接不存在的文件,这就产生一般称之为”断链”的现象),链接文件甚至可以循环链接自己(类似于编程中的递归)。在对符号文件进行读或写操作的时候,系统会自动把该操作转换为对源文件的操作,但删除链接文件时,系统仅仅删除链接文件,而不删除源文件本身。符号链接的操作是透明的:对符号链接文件进行读写的程序会表现得直接对目标文件进行操作。某些需要特别处理符号链接的程序(如备份程序)可能会识别并直接对其进行操作。一个符号链接文件仅包含有一个文本字符串,其被操作系统解释为一条指向另一个文件或者目录的路径。它是一个独立文件,其存在并不依赖于目标文件。如果删除一个符号链接,它指向的目标文件不受影响。如果目标文件被移动、重命名或者删除,任何指向它的符号链接仍然存在,但是它们将会指向一个不复存在的文件。这种情况被有时被称为被遗弃。
UNIX系统中I/O模型很有特色的点是I/O的普遍性(universality)。这意味着可以对所有的文件类型使用相同的system calls(open()、read()、write()、close()等)来执行I/O操作。因此,程序调用这些system calls可以对任何的文件类型起作用。
kernel本质上只提供了一种文件类型:有序字节流(a sequential stream of bytes)。
许多应用和库将 newline 字符作为文本中一行的结束和另一行的开始。UNIX系统没有 end-of-file 字符;read之后没有数据返回就说明一个文件结束。
I/O system calls使用 文件描述符(file descriptor) 来打开文件。文件描述符是一个(很小的)非负整数。经常通过调用open()来获取文件描述符,open()需要传入一个pathname作为参数,指定对文件采用哪种I/O操作。
通常,一个进程启动时会继承三种open file descriptors: descriptor 0 表示 标准输入(standard input) ,进程从该文件中获取输入数据;descriptor 1 表示 标准输出(standard output),进程将数据写入到该文件中;descriptor 2是 标准错误(standard error),进程将错误消息、异常通知或者反常情况写入到该文件中。在交互式shell或者程序中,这三类描述符通常连接到终端。在stdio库中,这些描述符对应文件流的stdin、stdout和stderr。
为了执行文件I/O,C语言程序一般采用标准C语言库中包含的I/O函数。这些函数的集合在stdio库中,包括fopen()、fclose()、scanf()、printf()、fgets()、fputs()等等。stdio中的函数建立在I/O system calls (open()、close()、read()、write()等等)之上。
程序一般以两种形式存在:第一种程序是 源代码(source code) 。这是一种人类可读懂的文本,包含一系列用程序语言写的语句,例如C。想要执行,源代码必须转换成第二种形式:二进制机器语言指令(binary machine-language instructions),这是一种计算机可以理解的程序。通过编译和链接,可以将源代码转化成二进制机器指令。
filter 经常运用在程序中,通过stdin读取输入数据,对这些数据数据进行一系列转化,将转化过的数据写入到stdout。filters的例子包括:cat、grep、tr、sort、wc、sed和awk
在C语言中,程序可以读取 命令行参数(command-line arguments),命令行参数是指在程序启动时通过命令行来提供的参数。为了读取命令行参数,程序的main函数以如下形式声明:
int main(int args, char *argv[])
argc这个变量表示命令行参数的个数,每个参数以字符串形式呈现,可以通过数组argv获取。第一个字符串argv[0]表示程序本身的名称。
进程(process) 是一个正在执行的程序的实例。当程序被执行时,kernel将程序的代码加载到虚拟内存中,为程序变量分配空间,建立内核记账簿(kernel bookkeeping)数据结构,用于记录关于这个进程的各种信息(例如进程ID、终止状态(termination status)、用户IDs和组IDs(group IDs))。
从kernel的角度看,kernel为进程分配各种计算机资源。因为资源是有限的,如内存,所以kernel刚开始的时候会分配给进程一些资源,随着时间推移会根据系统总体资源和该进程资源的使用情况而调整该进程的资源。当进程结束时,所有的这些资源都会被回收,供其他进程使用。另外一些资源,如CPU和网络带宽是可再生的(renewable),但是必须由所有进程公平共享。
进程逻辑上可分成以下部分,被称为 segments:
进程可以通过使用 fork() 系统调用创建另一个新的线程。调用fork()的进程被称为父进程(parent process) ,新创建的那个进程被称为子进程(child process)。Kernel通过对父进程的复制来创建子进程。子进程继承父进程的数据、栈和堆段(heap segment)的拷贝,这样子进程就可以独立地修改这份拷贝(内存中的程序文本(program text)是只读的,所以父进程和子进程可以共享程序文本)。
子进程要么继续执行相同代码的指令集,要么就调用 execve() 这个系统调用来加载和执行一个完全新的程序。execve()的调用会销毁现存的文本、数据、堆和栈段,根据新的程序的代码使用新的segments。
有几个C语言库函数是建立在execve()上的,每个函数提供了稍许不同的类似功能的接口。所有的这些函数的名字都以 exec 开头, 至于到底有哪些不同,我们暂不关心。我们使用符号 exec() 来统一的表示这些函数。请注意,实际上没有任何一个函数的名字是exec()。
通常,我们将会使用动词 exec 来表示execve()以及exec()的执行操作。
每个进程都有一个唯一的整数型的进程标识符(process identifier, PID)。每个进程还都有一个父进程标识符(parent process identifier, PPID),用于表示是哪个进程请求kernel创建了这个进程。
进程的终止(termination) 有两种方式:自己请求终止,使用 _exit() 系统调用(或者跟exit()相关的库函数)。或者接收到一个signal来kill掉这个进程。任何方法都会使进程产生一个 终止状态(termination status),这是一个很小的非负整数值,父进程可以通过使用wait()系统调用检查这个值。在调用_exit()的情况中,进程可以显示地指定这个终止状态的值。如果进程是被signal杀掉的,那么终止状态的值被设为杀掉这个进程的signal的类型。
按照惯例,终止状态的值是0时,进程是正常结束的;非0值表明遇到了某个错误而终止。
每个进程都有若干相关的user IDs(UIDs)和group IDs(GIDs)。包括:
在传统的UNIX系统中,特权进程(privileged process) 是指effective user ID是0(superuser)的那些进程。这些进程由kernel授权,绕过权限约束。相反地,非特权进程(unprivileged or nonprivileged process) 是由其他用户运行的。这些进程的effective user ID是非0的,会受到kernel的权限约束。
当进程由另一个特权进程创建时,这个进程是特权进程。另一种成为特权进程的方式是通过 set-user-ID机制,允许进程获取的effective user ID与正在执行的程序文件的user ID相同。
从Kernel 2.2开始,传统的superuser的特权被分成了一组不同的单元,被称为capabilities(能力)。每个特权操作都属于特定的capability,进程只有在拥相应的capability的条件下才能执行操作。传统的superuser的进程(effective user ID是0的进程)相当于拥有所有的capabilities。
给一个进程授予一个capabilies的子集,就能使它执行一些superuser才能执行的操作,但是可以防止它执行其他的一些操作。
在启动系统的时候,kernel会创建一个特别的进程,被称为 init。init进程来源于程序文件 /sbin/init。它是“所有进程的父进程”。系统中的所有进程不是被init创建(使用fork()),就是被init的后代进程创建。init进程的process ID是1,拥有superuser特权。init进程不能被killed(superuser都不能杀死它),只有当系统关闭时,init进程才会被终止。init进程的主要任务是创建系统运行所必须的进程并进行监控。
守护进程(daemon process) 是一类具有特殊目的的进程,跟其他进程一样,由系统创建和管理,但是有以下特殊性质:
每个进程都有一个环境列表(enviroment list),它是存储在进程用户空间内存(user-space memory)中的一组环境变量(environment variables)。每个环境变量都包含名称和相应的值。当新的进程是通过fork()创建时,它的环境继承自父进程的环境的拷贝。因此,环境提供了一种父进程与子进程通信的机制。在大部分shell中,使用export命令来创建环境变量(C shell中使用setenv命令),正如下面的例子:
export MYVAR='Hello world'
C程序使用外部变量(char **environ)来访问环境。有很多库函数允许检索和修改环境中的值。
每个进程都会消耗资源,例如打开文件、内存和CPU时间。使用**setrlimit()系统调用,进程可以创建各种资源消耗的上线。每个资源限制(resource limit)**都有两个相关值:
mmap()这个系统调用在调用进程的虚拟地址空间时会创建一个新的 内存映射(memory mapping)。Mapping分成两类:
一个进程映射的内存可能被其他进程的映射共享。发生这种情况有两种可能:
当两个或多个进程共享相同的分页时,每个进程都能看到其他进程对该分页的修改内容。这主要取决于映射在创建是被设置为私有(private)还是共享(shared)的。如果映射是私有的,那么对映射内容的修改,其他进程是不可见的,并且不会被传递到底层文件;如果映射是共享的,那么对映射内容的修改对于其他进程是可见的,且会传递到底层文件。
内存映射有很多作用,包括根据可执行文件的片段对进程文本片段进行初始化、新(zero-filled)内存的分配、文件I/O(momory-mapped I/O)和进程间通信(通过一种共享映射)。
对象库(object library) 是一个包含着编译过的对象代码(object code)的文件,在这个对象代码中有一组(经常是逻辑相关的)函数,这些函数可能会被应用程序调用。将一组函数的代码放在单个对象库中有利于减轻程序的创建和维护工作。现代UNIX系统提供了两类对象库: 静态库(static libraries) 和共享库(shared libraries)。
静态库(有时也称archives)是早期UNIX系统中唯一的一种库类型。静态库本质上是一组编译过的对象模块。想要使用静态库中的函数,需要在链接命令中指定这个库来构建程序。在解析了main程序和静态库模块中个各种函数引用后,链接器(linker)从库中提取需要对象模块的拷贝,将结果放入到可执行文件中。我们称这样的程序是静态且链接过的(statically linked)。
实际上每个静态且链接过的程序包含库中所需对象模块的拷贝。这产生了很多缺点:首先是在不同的可执行文件中会重复的对象代码,浪费了磁盘空间。同时也浪费内存,因为程序运行时,这些函数的拷贝都会驻扎在内存中。其次,如果一个库函数需要修改,修改之后要重新编译并添加到静态库中,并且如果应用想要使用更新过的库函数,就需要重新进行链接。
共享库的出现就是为了解决静态库存在的问题。
如果一个程序链接到了一个共享库,不需要将库中的对象模块拷贝到执行文件中。链接器只需往可执行文件中写一条记录,用于表示在运行时需要用到这个库。在运行时,当可执行文件加载到内存后,一个被称为动态连接器(dynamic linker) 的程序会找到可执行文件所需的共享库,加载到内存中,并执行运行时链接来解决可执行文件对共享库的 函数调用。在运行时,只需要将共享库代码的一份拷贝放到内存中,所有运行的程序都会使用同一份拷贝。
事实上,磁盘中只有一份共享库的编译版本,大大减轻了程序使用最新版本函数的工作。并且当修改了共享库中的函数,并重新构建后,当前程序会在下次执行时自动使用共享库中修改过的函数,而不需要像静态库那样重新链接。
一个运行着的Linux系统包含很多进程,很多都是独立运行的。然而有些进程之间需要通过协作来达到它们的目的,这些进程需要具有与其他进程通信的方法,并且对它们的行为进行同步(synchronization) 。
进程之间通信的一种方式是以磁盘文件的方式读写信息。但是对于很多应用来说,这样效率太低且不够灵活。因此,像其他现代UNIX系统一样,Linux提供了一组丰富的机制,用于进程间通信(interprocess communication,IPC) ,这些机制包括:
尽管我们在上一节把signals(信号) 作为IPC的一种方法。但是本文中signal会被广泛提到,所以值得详细介绍。
signals经常被描述成“软件中断(software interrupts)”。一个signal的到达会告知进程一些事件或异常条件已经产生。signal的类型有多种,每个类型都表示一个不同的事件或者条件。每个signal类型都由不同的整数值进行标识。使用形为SIGxxxx的符号名称进行定义。
Signals的发送者可以是Kernel、其他进程或者进程自己。举例来说,当以下条件发生时,kernel就可能发送一个signal给进程:
在shell中,kill命令可以发送signal给进程。程序中的 kill() 系统调用提供了相同的功能。
当进程接收到singal后,会根据具体的signal,采取以下其中一种行为:
在现代UNIX系统中,进程可以多线程执行。进程中的多个线程共享相同的虚拟内存,及很多其他属性。每个线程执行相同的程序代码,共享相同的数据区域和堆。但是每个线程拥有自己的栈(stack),栈中包含了本地变量和函数调用链接信息(function call linkage information)。
线程之间可以通过它们 共享的本地变量 来通信。线程API中还提供了条件变量(condition variables) 和 互斥器(mutexes),用于++同个进程++中的线程间的通信和行为同步。++不同进程++的线程间的通信可以使用IPC和2.10节中提到的同步机制。
使用线程的主要优势是互相协作的线程间可以很容易地共享数据(通过全局变量),以及有些算法变换(transpose)在多线程间比多进程间更加自然。此外,多线程的应用可以利用多处理器硬件进行并行化的处理。
由shell启动的程序都会启动一个新的进程。例如,通过shell创建三个进程来执行下面的命令管道(pipeline of commands),下面pipeline的意思是,列出当前工作目录的文件列表,并以文件大小排序:
ls -l | sort -k5n | less
所有主要的shells(除了Bourne shell),都提供了一种称为job control的交互式功能,它允许用户同时执行和维护多个命令或者pipelines。在job-control shells中,pipeline中的所有进程会被放到一个新的进程组(process group)或job中。一个process group中的每个进程都有相同的进程组标识符(process group identifier),它是一个整型值,并且与组中的某个进程的process ID是相同的,这个进程被称为进程组leader (process group leader)。
Kernel允许各种行为(如singal的传递)在process group中的所有成员中执行。Job-control shells的这个特征允许用户对pipeline中的进程进行暂停或恢复。
session 是进程组(process group)的集合。同个session中的所有进程都拥有相同的session标识符(session identifier)。session leader 是创建了这个session的进程,并且该进程的Process ID成为session ID。
Session主要在job-contrl shell中被用到。某个job-control shell创建的所有进程组都属于相同的session,这个shell也就是session leader。
打开控制终端(controlling terminal) 的结果就是session leader成为该终端的控制进程(controlling process)。如果终端断开连接,controlling process会接收到一个SIGHUP信号(SIGHUP signal)。
在任何时候,session中都有一个被称为 前台进程组(foreground process group 或 foreground job) 的进程组。它可以从终端读取输入或者将输出发给终端。如果用户在控制终端输入中断(interrupt)字符(通常是CTRL+C)或者暂停(suspend)字符(通常是CTRL+Z),那么终端驱动器(terminal driver)会发送kill或suspend (也就是停止) 信号给前台进程组。一个session可以有任意数量的后台进程组(background process groups 或 background jobs)。后台进程组通过 & 字符创建。
nohup java -jar datag-0.2.0.jar &
Job-control提供了列出所有job(进程组)、发送信号给jobs、从前台和后台移动jobs的命令。
伪终端(presudoterminal)是一对连通的虚拟设备,被称为master和slave。伪终端提供了一个IPC通道,使用户能在这两个设备之间双向传输数据。
伪终端的关键点是slave设备提供了一个类似终端(terminal)的接口,可以将面向终端的程序与slave设备进行连接,然后使用另一个程序连接到master设备来驱动这个面向终端的程序。
进程对两种类型的时间感兴趣:
time 这个命令显示了pipeline中进程执行所花的real time、系统CPU时间和用户CPU时间。
客户端-服务端应用(client-server application) 由两组进程组成:
一般来说,客户端应用与用户进行交互,而服务端应用提供一些可访问的共享资源。通常情况下,有很多客户端进程的实例会与一个或者较少的服务端进程实例进行通信。客户端和服务端可以在相同的计算机上,也可以通过网络连接处在不同的计算机上。客户端和服务端使用IPC的方式进行通信。
服务端可能实现了各种各样的服务,例如:
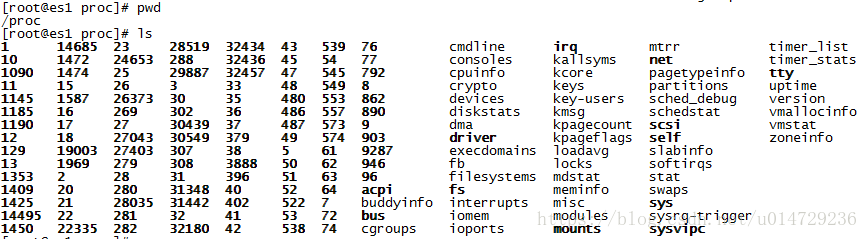
像其他的UNIX系统一样,Linux提供了 /proc 文件系统。它包含挂载(mounted)在/proc目录下的一组目录和文件。
/proc文件系统是一个虚拟的文件系统,它将kernel中的数据结构以类似文件系统中文件和目录的形式展现出来。这使得可以查看和修改各种系统属性。此外,一些目录的名称的是/proc/PID,这里PID是进程ID,我们可以通过这些目录了解系统中每个进程运行的信息。
/proc目录中的文件的内容,一般都是以(human-readable)可读的文本呈现的,并且可以被shell脚本解析。程序可以对所需文件进行打开、读取或者写入。大部分情况下,进程必须有相应权限才能对/proc目录下的文件进行修改。
在本节中,我们对Linux系统编程相关的概念进行了简单介绍。对这些概念的理解有助于读者为接下来的Linux系统编程打下基础。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!