
一、前言
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
- 很多 shell 脚本处理不了或者处理不方便的事情 python 可以干
- python代码简单,配置简单,各种开源库多
- 效率高,性价比高
二、下载安装
2.1 解压缩
1)xz
xz 是一个使用 LZMA 压缩算法的无损数据压缩文件格式(压缩率很高)
xz -d 文件.xz # 解压缩
xz -z 文件 # 强制压缩
2)tar
tar zcvf 文件.tar.gz # 打包文件夹或文件 tar zxvf 文件.tar.gz # 解压
文件后缀如果没有.gz 则代表没有使用 gzip 压缩,只需去掉 tar 命令的参数 z
2.2 安装
进入 Python 源码目录:
./Configure
脚本 Configure 用来生成 makefile,它本身是由 autoconf 软件生成的
make && make install
编译和安装
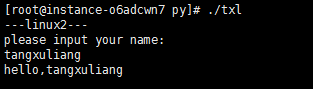
2.3 第一个 Python 程序
1 #! /usr/bin/python 2 import sys 3 print('---'+sys.platform+'---') 4 print('please input your name: ') 5 get_str = sys.stdin.readline() 6 print('hello,'+get_str)
第一行:代表该文件由 python 解释执行
第二行:代表引入系统相关的信息模块 sys
第三行:代表输出运行的操作系统环境
第五行:代表从标准输入读一行
执行结果:
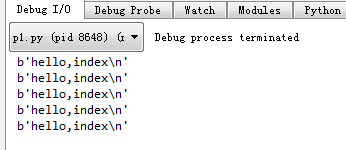
三、Python 模拟访问网站
» p1.py
import urllib.request def jumpto(): response = urllib.request.urlopen('http://180.76.232.93/index.html') html = response.read() print(html) # 请求5次 for i in range(5): jumpto()
执行结果:
四、Shell 分析
4.1 查看连接数
netstat 查看 80 端口的连接数(TIME_WAIT 状态):
# netstat -apt | grep "TIME_WAIT" | grep ":http" | wc -l netstat -ant | grep "TIME_WAIT" | grep ":80" | wc -l
执行结果:

4.2 分析 apache 日志
1)查看日志
apache 日志文件默认位置为:/etc/httpd/logs
cat /etc/httpd/logs/access_log
执行结果类似:

2)查看总记录数
wc -l /etc/httpd/logs/access_log
执行结果类似:

3)统计去重后倒排序的 ip 访问次数
cat access_log | awk '{print $1}' | sort | uniq -c | sort -nr
执行结果类似:

五、Python 分析
python 读取 access_log 日志并倒排序统计访问次数最多的 ip。
» p2.py
# coding=utf-8 ip_list={} file=open('access_log',mode='r') try: # lines=file.readlines() # print(len(lines)) # 读取一行数据 line=file.readline() while line: # 按空格分割一行数据 line_sp=line.split(' ') if len(line_sp)>3: # 该ip已经存在则将其出现次数+1 if line_sp[0] in ip_list: ip_list[line_sp[0]] = ip_list[line_sp[0]] + 1 # 该ip首次出现则初始化其出现次数为1 else: ip_list[line_sp[0]] = 1 # 继续读取一行数据 line=file.readline() # 按照ip出现的次数排序 ip_list_sort=sorted(ip_list.items(),key=lambda v:v[1],reverse=True) # 最终输出 print(ip_list_sort) except Exception as e: print(e) finally: file.close()
执行结果类似:

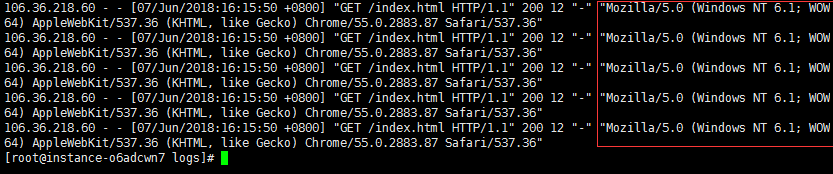
六、Python 伪装 User-Agent 访问网站
查看 access_log 日志可以很容易发现之前通过 python 的访问为非浏览器正常访问,因为日志中 User-Agent 记录了 Python-urllib 程序访问:

» p3.py(伪造头信息):
import urllib.request def jumpto(): request = urllib.request.Request('http://180.76.232.93/index.html') user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'; request.add_header("User-Agent",user_agent) response = urllib.request.urlopen(request) print(response.read()) for i in range(5): jumpto()
执行成功后,查看 access_log 日志访问记录会发现 User-Agent 信息已经被伪造修改:
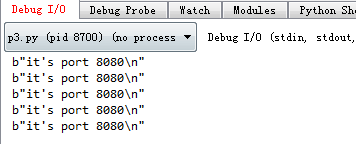
七、iptables nat 端口转发
指定某个 ip 访问网站 80 端口时,自动转发到该网站 8080 端口:
iptables -t nat -R PREROUTING 1 -p tcp -s 106.36.218.60 --dport 80 -j DNAT --to-destination :8080
执行成功后,当 106.36.218.60 这个 ip 访问网站将无法显示原本 80 端口的内容:
八、Python 伪造 Cookie 登录
测试网站有2个页面:
127.0.0.1/py/index.php:访问时检查 Cookie,否则跳转到 login.php:
if(isset($_COOKIE['userinfo']) && $_COOKIE['userinfo']=='txl')127.0.0.1/py/login.php:登录表单,登录成功时保存 cookie
假设 cookie 保存为明文格式,如下:

8.1 保存网站 cookie
» p4.py
import urllib.request import http.cookiejar postdata=urllib.parse.urlencode({ "user_name":"txl", "user_pwd":"123" }).encode('utf-8') # 把 cookie 内容保存在对象(内存中) cookiejar = http.cookiejar.LWPCookieJar(filename='d:/cookie.txt') # 处理 Http cookie handler = urllib.request.HTTPCookieProcessor(cookiejar=cookiejar) # 通过 build_opener 可以自己创建一个 OpenerDirector 实例,构建一个cookie管理,将 handler 类实例化增加到 OpenerDirector 中 opener = urllib.request.build_opener(handler) header = { "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding":"utf-8", "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3", "Connection":"keep-alive", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0" } # 返回了一个 request 的请求实例 request = urllib.request.Request('http://127.0.0.1/py/login.php',postdata,header) # 有了 opener 之后,任何请求就不能直接使用 urllib,而要使用 opener 来 request # response = urllib.request.urlopen(request) response = opener.open(request)
# 将 cookie 文件保存到文件 cookiejar.save() print(response.read().decode('utf-8'))
执行成功后,查看 d:/cookie.txt:

8.2 使用本地 cookie 请求网站
» p4-2.py
import urllib.request import http.cookiejar postdata=urllib.parse.urlencode({ "user_name":"txl", "user_pwd":"123" }).encode('utf-8') cookiejar = http.cookiejar.LWPCookieJar(filename='d:/cookie.txt') # 读取本地 cookie 文件 cookiejar.load() handler = urllib.request.HTTPCookieProcessor(cookiejar=cookiejar) opener = urllib.request.build_opener(handler) header = { "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding":"utf-8", "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3", "Connection":"keep-alive", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0" } request = urllib.request.Request('http://127.0.0.1/py/index.php',postdata,header) response = opener.open(request) print(response.read().decode('utf-8'))
执行后成功访问到需要登录 index.php 页面的内容:
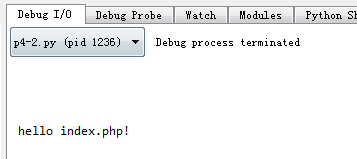
该测试程序由于 cookie 是明文存储的,所以可以发现 cookie 存储的值就是用户名,当我们手工修改 cookie 的值为其他用户名时,再通过 python 程序模拟提交就达到了伪造 cookie 登录的效果。所以登录时用户的 cookie 信息需要加密处理。
九、Python 多线程并发请求网站
线程(有时被称为轻量级进程)跟进程有些相似,不同的是,所有的线程运行在同一个进程中,共享相同的运行环境。
» p5.py
# coding=utf-8 import urllib.request import http.cookiejar import threading postdata=urllib.parse.urlencode({ "user_name":"txl", "user_pwd":"123" }).encode('utf-8') cookiejar = http.cookiejar.LWPCookieJar(filename='d:/cookie.txt') handler = urllib.request.HTTPCookieProcessor(cookiejar=cookiejar) opener = urllib.request.build_opener(handler) header = { "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding":"utf-8", "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3", "Connection":"keep-alive", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0" } # 登录 def login(): request = urllib.request.Request('http://127.0.0.1/py/login.php',postdata,header) response = opener.open(request) cookiejar.save() # print(response.read().decode('utf-8')) # 访问 def getindex(): try: cookiejar.load() request = urllib.request.Request('http://127.0.0.1/py/index.php',postdata,header) response = opener.open(request) print(response.read().decode('utf-8')) except Exception as e: print(e) login() # 同时开500个线程访问 for i in range(500): t = threading.Thread(target=getindex) t.start()
十、iptables 限制每个 ip 并发数
限制每个客户端 IP 的并发连接数,即每个 IP 同时连接到一个服务器个数。
需要使用到加载模块的方式(-m connlimit),该工具在 Linux 2.6.32 内核之前默认不支持。
iptables -I INPUT -p tcp -m connlimit --dport 80 -j DROP --connlimit-above 6
connlimit参数:
- -connlimit-above <n>:限制数 >n 时触发规则
- -connlimit-upto <n>:限制数在 n 范围内触发规则
- -connlimit-mask :限制主机的掩码默认32,即每个 IP
设置成功后,此时再通过 python 多线程并发访问,服务器会拒绝超过最大并发数的请求:
十一、相关工具
» ln 命令
ln 命令用来为文件创件连接,连接类型分为硬连接和符号连接两种,默认的连接类型是硬连接。最常见的参数是 -s(类似 windows 的快捷方式)。
1)基本语法
ln [选项] 源文件 目标文件
2)选项
- -b 或 --backup:删除,覆盖目标文件之前的备份
- -d 或 -F 或 --directory:建立目录的硬连接
- -f 或 --force:强行建立文件或目录的连接,不论文件或目录是否存在
- -i 或 --interactive:覆盖既有文件之前先询问用户
- -n 或 --no-dereference:把符号连接的目的目录视为一般文件
- -s 或 --symbolic:对源文件建立符号连接,而非硬连接
- -S <字尾备份字符串> 或 --suffix=<字尾备份字符串>:用 -b 参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字符串是符号 ~,用户可通过 -S 参数来改变它
- -v 或 --verbose:显示指令执行过程
- -V <备份方式> 或 --version-control=<备份方式>:用 -b 参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用 -S 参数变更,当使用 -V 参数<备份方式>指定不同备份方式时,也会产生不同字尾的备份字符串
- --help:在线帮助
- --version:显示版本信息
3)实例
把 /etc/httpd/logs/access_log 文件创建快捷方式到 ~/httpd_log
ln -s /etc/httpd/logs/access_log ~/httpd_log
» wc 命令
wc 命令用来计算文件的 Byte 数、字符数或是列数,若不指定文件名称,或是所给予的文件名为 - ,则 wc 指令会从标准输入设备读取数据。
1)基本语法
wc [选项] 文件
2)选项
- -c:统计字节数
- -l:统计行数
- -m:统计字符数。这个标志不能与 -c 标志一起使用
- -w:统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串
- -L:打印最长行的长度
- -help:显示帮助信息
- --version:显示版本信息
» awk 命令
awk 是一个强大的文本分析工具,相对于 grep 的查找,sed 的编辑,awk 在其对数据分析并生成报告时,显得尤为强大。简单来说 awk 就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
它被定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
1)基本语法
awk [选项] '{pattern + action}' {filenames}
awk [选项] -f awk-scriptfile filenames
2)选项
- -F fs or --field-separator fs
指定输入文件折分隔符,fs 是一个字符串或者是一个正则表达式,如 -F : - -v var=value or --asign var=value
赋值一个用户定义变量 - -f scripfile or --file scriptfile
从脚本文件中读取awk命令 - -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用 - -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略 - -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息 - -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明 - -W lint or --lint
打印不能向传统unix平台移植的结构的警告 - -W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告 - -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效 - -W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]] - -W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用 - -W version or --version
打印bug报告信息的版本
3)实例
access_log 文件每行按空格或 TAB 分割,输出文本中的1、7项:
cat access_log | awk '{print $1,$7}'
4)参考
《Linux:awk命令详解》:https://zhangge.net/1939.html
» sort 命令
sort 命令将文本文件内容以行为单位来排序,并将排序结果标准输出。sort 命令既可以从特定的文件,也可以从 stdin 中获取输入。
1)基本语法
sort [选项] filename
2)选项
- -b:忽略每行前面开始出的空格字符
- -c:检查文件是否已经按照顺序排序
- -d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符
- -f:排序时,将小写字母视为大写字母
- -i:排序时,除了040至176之间的 ASCII 字符外,忽略其他的字符
- -m:将几个排序号的文件进行合并
- -M:将前面3个字母依照月份的缩写进行排序
- -n:依照数值的大小排序
- -o <输出文件>:将排序后的结果存入制定的文件
- -r:以相反的顺序(倒序)来排序
- -t <分隔字符>:指定排序时所用的栏位分隔字符
- + <起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位
- -u:在输出行中去除重复行
- -k <列>:以指定列的值排序
» uniq 命令
uniq 命令去除排序后文件中的重复行,因此 uniq 经常和 sort 结合使用(所有的重复行必须是相邻的)。
1)基本语法
uniq [选项] 输入文件 [输出文件]
- 输入文件:指定要去除的重复行文件。如果不指定此项,则从标准读取数据
- 输出文件:指定要去除重复行后的内容要写入的输出文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)
2)选项
- -c 或 --count:在每列旁边显示该行重复出现的次数
- -d 或 --repeated:仅显示重复出现的行列
- -f <栏位> 或 --skip-fields=<栏位>:忽略比较指定的栏位
- -s <字符位置> 或 --skip-chars=<字符位置>:忽略比较指定的字符
- -u 或 --unique:仅显示出一次的行列
- -w <字符位置> 或 --check-chars=<字符位置>:指定要比较的字符
» uname 命令
uname 命令用于打印当前系统相关信息(内核版本号、硬件架构、主机名称和操作系统类型等)。
1)基本语法
uname [选项]
2)选项
- -a 或 --all:显示全部的信息
- -m 或 --machine:显示电脑类型
- -n 或 -nodename:显示在网络上的主机名称
- -r 或 --release:显示操作系统的发行编号
- -s 或 --sysname:显示操作系统名称
- -v:显示操作系统的版本
- -p 或 --processor:输出处理器类型或 unknown
- -i 或 --hardware-platform:输出硬件平台或 unknown
- -o 或 --operating-system:输出操作系统名称
- --help:显示帮助
- --version:显示版本信息
» man 命令
man 命令是 Linux 下的帮助指令,可以查看 Linux 中的指令帮助、配置文件帮助和编程帮助等信息。
1)基本语法
man [选项] 关键字
2)选项
- -a:在所有的 man 帮助手册中搜索
- -f:等价于 whatis 指令,显示给定关键字的简短描述信息
- -P:指定内容时使用分页程序
- -M:指定 man 手册搜索的路径
» top 命令
top 命令经常用来监控 Linux 的系统状况,比如 cpu、内存的使用情况。
1)基本语法
top [选项]
2)选项
- -b:以批处理模式操作
- -c:显示完整的治命令
- -d <秒>:屏幕刷新间隔时间
- -I:忽略失效过程
- -s:保密模式
- -S:累积模式
- -i <时间>:设置间隔时间
- -u <用户名>:指定用户名
- -p <进程号>:指定进程
- -n <次数>:循环显示的次数
3)进入视图
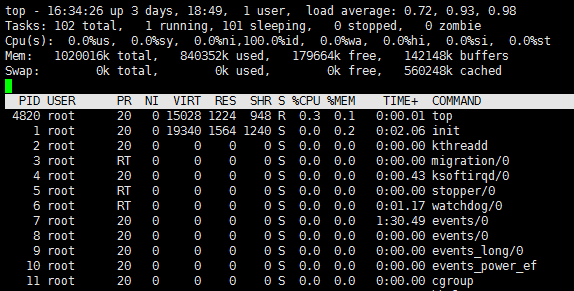
① 第一行:
- 16:34:26:当前系统时间
- 3 days, 18:49:系统已经运行了3天18小时49分钟(在这期间没有重启过)
- 1 users:当前有1个用户登录系统
- load average: 0.72, 0.93, 0.98:三个数字分别是1分钟、5分钟、15分钟的负载情况
load average 数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑 CPU 的数量,结果高于5的时候就表明系统在超负荷运转了。
② 第二行:
Tasks:任务(进程)。系统现在共有102个进程,其中处于运行中的有1个(running),101个在休眠(sleep),stoped 状态的有0个,zombie状态(僵尸)的有0个。
③ 第三行:CPU 状态
- 0.0% us:用户空间占用 CPU 的百分比。
- 0.0% sy:内核空间占用 CPU 的百分比。
- 0.0% ni:改变过优先级的进程占用 CPU 的百分比
- 100.0% id:空闲 CPU 百分比
- 0.0% wa:IO 等待占用 CPU 的百分比
- 0.0% hi:硬中断(Hardware IRQ)占用 CPU 的百分比
- 0.0% si:软中断(Software Interrupts)占用 CPU 的百分比
④ 第四行:内存状态
- 1020016k total:物理内存总量(1GB)
- 840352k used:使用中的内存总量(840M)
- 179664k free:空闲内存总量(179M)
- 142148k buffers:缓存的内存量(142M)
⑤ 第五行:swap 交换分区
- 0k total:交换区总量(0K)
- 0k used:使用的交换区总量(0K)
- 0k free:空闲交换区总量(0K)
- 560248k cached:缓冲的交换区总量(560M)
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到 free 中去,因此在 linux 上 free 内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的 free + 第四行的 buffers + 第五行的 cached,按这个公式此台服务器的可用内存:179M+142M+560M = 881M。
对于内存监控,在 top 里我们要时刻监控第五行 swap 交换分区的 used,如果这个数值在不断的变化,说明内核在不断进行内存和 swap 的数据交换,这是真正的内存不够用了。
⑥ 第七行以下:各进程(任务)的状态监控
- PID:进程 id
- USER:进程所有者
- PR:进程优先级
- NI:nice 值。负值表示高优先级,正值表示低优先级
- VIRT:进程使用的虚拟内存总量,单位 kb。VIRT=SWAP+RES
- RES:进程使用的、未被换出的物理内存大小,单位 kb。RES=CODE+DATA
- SHR:共享内存大小,单位 kb
- S:进程状态。D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程
- %CPU:上次更新到现在的 CPU 时间占用百分比
- %MEM:进程使用的物理内存百分比
- TIME+:进程使用的 CPU 时间总计,单位1/100秒
- COMMAND:进程名称(命令名/命令行)
4)快捷键
- 按内存使用排序:shift + m
- 按 CPU 使用排序:shift + p
5)参考
《linux top命令查看内存及多核CPU的使用讲述》:https://www.cnblogs.com/dragonsuc/p/5512797.html
