社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
String: 字符串
redis 127.0.0.1:6379> SET name "runoob"
OK
redis 127.0.0.1:6379> GET name
"runoob"
Hash: 散列
redis> HMSET myhash field1 "Hello" field2 "World"
"OK"
redis> HGET myhash field1
"Hello"
redis> HGET myhash field2
"World"
List: 列表
redis 127.0.0.1:6379> lpush runoob redis
(integer) 1
redis 127.0.0.1:6379> lpush runoob mongodb
(integer) 2
redis 127.0.0.1:6379> lpush runoob rabitmq
(integer) 3
redis 127.0.0.1:6379> lrange runoob 0 10
1) "rabitmq"
2) "mongodb"
3) "redis"
redis 127.0.0.1:6379>
Set: 集合
redis 127.0.0.1:6379> sadd runoob redis
(integer) 1
redis 127.0.0.1:6379> sadd runoob mongodb
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 0
redis 127.0.0.1:6379> smembers runoob
1) "redis"
2) "rabitmq"
3) "mongodb"
Sorted Set: 有序集合
redis 127.0.0.1:6379> zadd runoob 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 mongodb
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 0
redis 127.0.0.1:6379> > ZRANGEBYSCORE runoob 0 1000
1) "mongodb"
2) "rabitmq"
3) "redis"
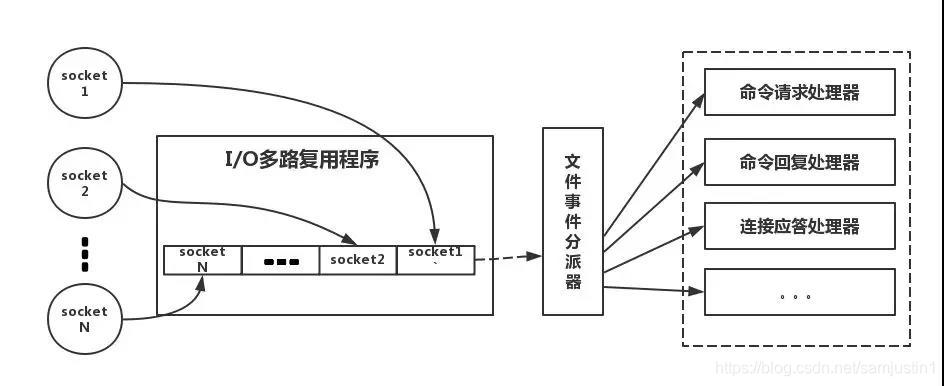
单线程模型
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
单线程模型每秒万级别处理能力的原因
(1)纯内存访问。数据存放在内存中,内存的响应时间大约是100纳秒,这是Redis每秒万亿级别访问的重要基础。
(2)非阻塞I/O,Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
(3)单线程避免了线程切换和竞态产生的消耗。
(4)Redis采用单线程模型,每条命令执行如果占用大量时间,会造成其他线程阻塞,对于Redis这种高性能服务是致命的,所以Redis是面向高速执行的数据库。
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
1.缓存和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
2.缓存雪崩问题
概念
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
解决方案
一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。互斥锁,但是该方案吞吐量明显下降了。3.缓存击穿问题
概念
访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
解决方案
互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤;也将空值写进缓存,但可以设置较短过期时间。4.缓存的并发竞争问题
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
