社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在第二篇文章中说到,查询分离中存在三大不足,其中一个不足就是:当主数据量越来越大,写操作缓慢,遇到这个问题我们该如何解决呢?
为此,这篇文章我们主要围绕这个问题来讨论,拆分存储如何进行技术选型?分库分表的实现思路是什么?分库分表存在哪些不足?
为了便于理解,我们通过一个业务场景来入手。
有一个电商系统架构优化工作,该系统中包含用户和订单2个主要实体,每个实体涵盖数据量如下表所示:
| 实体 | 数据量 | 增长趋势 |
|---|---|---|
| 用户 | 千万级 | 每日10万 |
| 订单 | 亿级 | 每日百万级,后续可能千万级 |
从上表中发现,目前订单数据量已达上亿,并且每日以百万级速度增长,之后还可能是千万级。
面对如此大的数据量,此时存储订单的数据库竟然还是一个单库单表。对于单库单表而言,一旦数据量实现疯狂增长,无论是IO还是CPU都会扛不住。
为了使系统抗住千万级数据量的压力,各种SQL优化都已经做完,最终确定下来的方式是将订单表拆分,再进行分布存储,这也就是本章我们要讨论的内容——分库分表。
说到分库分表解决方案,我们首先需要做的就是搞定拆分存储的技术选型问题。
关于拆分存储常用的技术解决方案,市面上目前主要分为4种:MySQL的分区技术、NoSql、NewSQL、基于MySQL的分库分表。
MySQL的分区主要在文件存储层做文章,它可以将一张表的不同存放在不同存储文件中,这对使用者来说比较透明。
在以往的实战项目中,我们不使用它的原因主要有三点。
1、MySQL的实例只有一个,它仅仅分摊了存储,无法分摊请求负载。
2、正式因为MySQL的分区对用户透明,所以用户在实际操作时往往不太注意,使得跨分区操作严重影响系统性能。
3、当然,MySQL还有一些其他限制,比如不支持query cache、位操作表达式等。感兴趣的朋友可以看看这个文章:https://dev.mysql.com/doc/refman/5.7/en/partitioning-limitations.html。
比较典型的NoSQL数据库就是MongoDB啦。MongoDB的分片功能从并发性和数据量这两个角度已经能满足一版大数据量的需求,但是需要注意这三大要点。
1、约束考量:MongoDB不是关系型数据库而是文档型数据库,它的每一行记录都是一个结构灵活可变的JSON,比如存储非常重要的订单数据时,我们就不能使用MongoDB,因为订单数据必须使用强约束的关系型数据库进行存储。
2、业务功能考量:多年来,事务、锁、SQL、表达式等千奇百怪的操作都在MySQL身上一一验证过,MySQL可以说是久经考验,因此在功能上MySQL能满足我们所有的业务需求,MongoDB却不能,且大部分的NoSQL也存在类似的问题。
3、稳定性考量:我们对MySQL的运维已经很熟悉了,它的稳定性没有问题,然而MongoDB的稳定性我们没法保证,毕竟不熟悉,因此在之前的拆分存储技术选型中,我们没使用过NoSQL。
NewSQL技术还比较新,我们曾今想在一些不重要的数据中使用NewSQL(比如TiDB),但从稳定性和功能扩展性两方面来考量后,最终没有使用,具体原因与MongoDB类似。
什么是分库分表?分表是将一份大的表数据拆分存放至多个结构一样的拆分表;分库就是将一个大的数据库拆分成多个结构一样的小库。
前面介绍的三种拆分存储技术,在我们以往的项目中都没有使用过,而是选择了基于MySQL的分库分表,主要是有一个重要考量:分库分表对于第三方依赖较少,业务逻辑灵活可控,它本身并不需要非常复杂的底层处理,也不需要重新做数据库,只是根据不同的逻辑使用不同的SQL语句和数据源而已。
如果使用分库分表方式,存在三个技术通用需求需要实现。
1、SQL组合:因为我们关联的表名是动态的,所以我们需要根据逻辑组装动态的SQL。
2、数据库路由:因为数据库名也是动态的,所以我们需要根据不同的逻辑使用不同的数据库。
3、执行结果合并:有些需求需要通过多个分库执行,再合并归集使用。
而市面上能解决以上问题的中间件分为2类:Proxy模式、Client模式。
(1)Proxy模式:直接拿ShardingSphere官方文档里的图进行说明,我们重点看看中间Sharding-Proxy层,如下图所示:
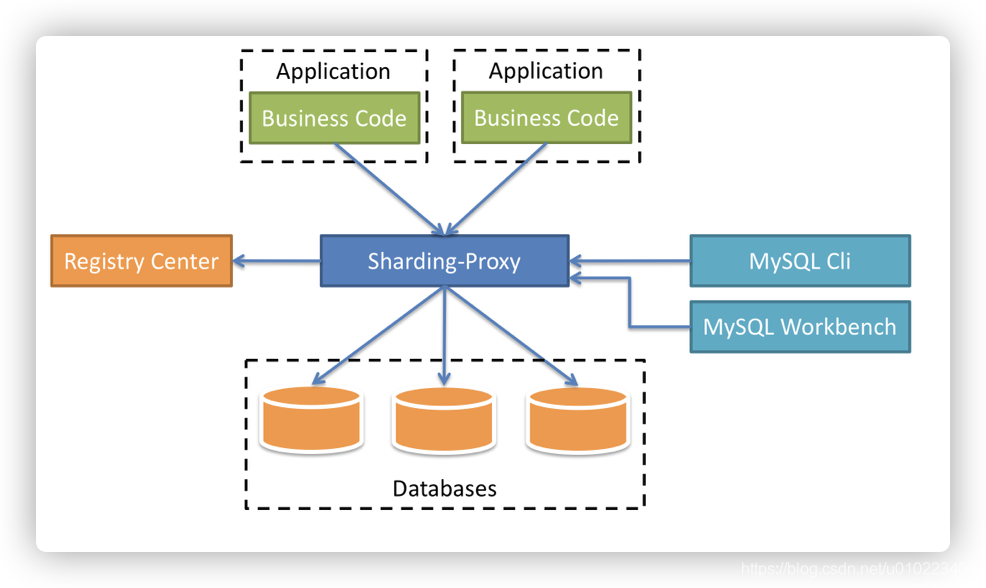
以上这种设计模式,把SQL组合、数据库路由、执行结果合并等功能全部存放在一个代理服务中,而与分库分表相关的处理逻辑全部存放在另外的服务中,这种设计模式的优点是对业务代码无侵入,业务只需要关注自身的业务逻辑即可。
(2)Client模式:还是借用shardingSphere官方文档的图来说明,如下图所示:
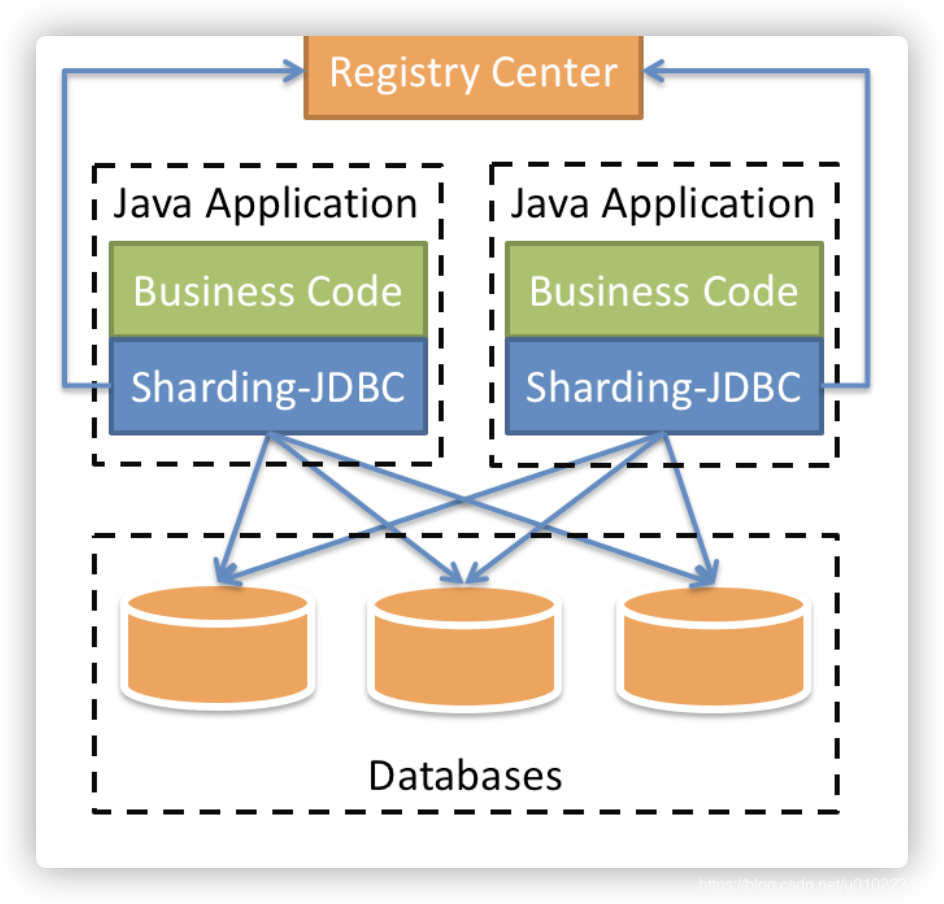
以上这种设计模式,把分库分表相关逻辑存放在客户端,一版客户端的应用会引用一个jar,然后再jar中处理SQL组合、数据库路由、执行结果合并等相关功能。
市面上,关于这两种模式的中间件有如下选择:
| 中间件技术 | 模式 | 厂家 | 语言 |
|---|---|---|---|
| MyCat | Proxy | Java | |
| KingShard | Proxy | Go | |
| Atlas | Proxy | 360 | C |
| zebra | Client | 美团 | Java |
| cobar | Proxy | 阿里 | Java |
| Sharding-JDBC | Client | Apache ShardingSphere | Java |
| TSharding | Client | 蘑菇街 | Java |
看到这里,我们已经知道市面上开源中间件的设计模式,那么我们到底该选择哪种模式呢?简单对比下这2个模式的优缺点,你就知道答案了。
| 模式 | 优点 | 缺点 |
|---|---|---|
| Proxy | 1、多语言。2、资源消耗解耦,不需要消耗客户端的资源。3、升级方便。 | 1、多一层服务调用,debug线上问题调查难一些。2、多一层运维成本。 |
| Client | 1、少一层服务调用,代码灵活可控。2、减少运维成本 | 1、单语言。2、升级不方便。 |
因为看重代码灵活可控这个优势,所以我们选择了Client模式里的Sharding-JDBC来实现分库分表,如下图所示:
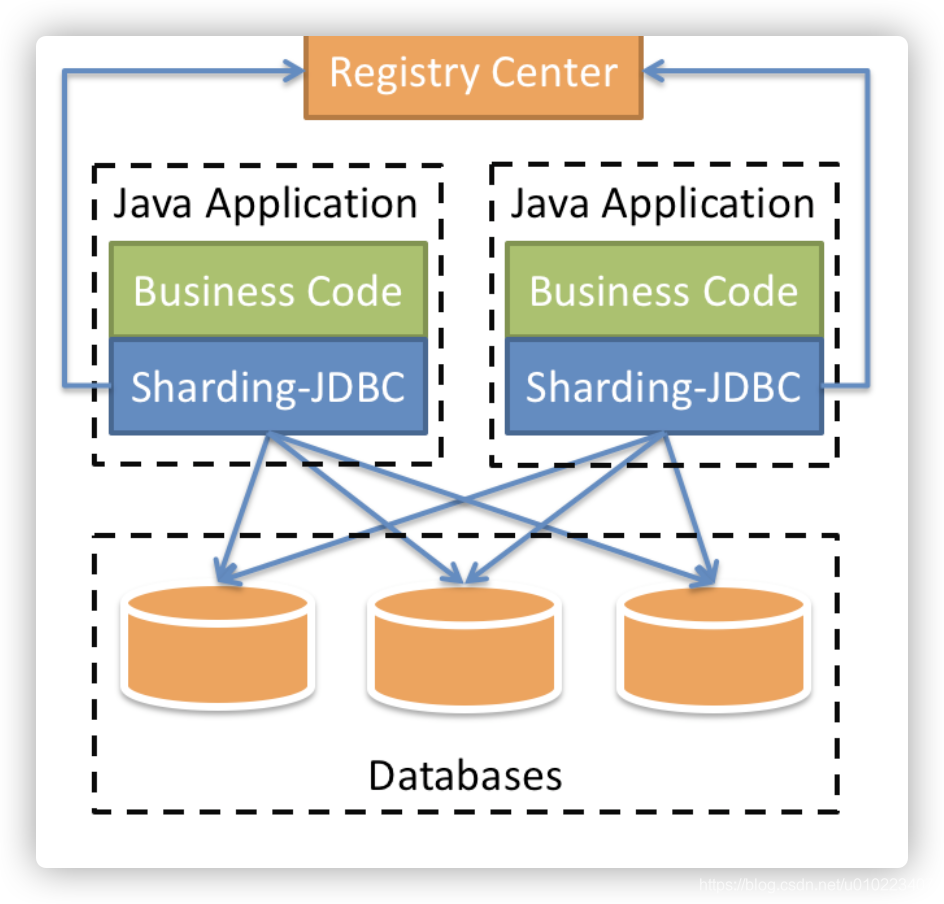
当然,关于拆分存储选择哪种技术,在实际工作中我们需要根据各自的实际情况来定。
技术选型这一大难题解决后,具体如何落地分库分表解决方案成了我们亟待解决的问题。
在落实分库分表解决方案时,我们需要考虑5个要点。
我们先来回顾下业务场景中举例的数据库:
| 实体 | 数据量 | 增长趋势 |
|---|---|---|
| 用户 | 千万级 | 每日10万 |
| 订单 | 亿级 | 每日百万级,后续可能千万级 |
下面我们把上表中的数据拆分成一个订单表,表中主要数据结构如下:
| 表名 | 字段 | 备注 |
|---|---|---|
| t_order | User_id | 客户id |
| Order_id | 订单id | |
| user_city_id | 用户所在城市 | |
| Order_time | 下单时间 | |
| … | 其他字段就不列了 |
从上面表中可知,我们是使用user_id作为分片主键,为什么这样分呢,来聊聊当时的实现思路。
在选择分片字段之前,我们首先了解了下目前存在的一些常见业务需求:
根据这些常见业务需求,我们判断了下优先级,用户操作也就是第一个需求必须优先满足。
此时,如果我们使用user_id作为订单分片字段,就能保证每次用户查询数据时(第一个需求),在一个分库的一个分表里即可获取数据。
因此,在我们的方案里,最终还是使用user_id作为分片主键,这样在分库分表查询时,首先会把user_id作为参数传过来。
这里需要特殊说明下,选择字段作为分片键时,我们一般要考虑三个因素:数据尽量均匀分布在不同的库或表、跨库查询尽可能少、这个字段值会不会变(这点尤为重要)。
决定使用user_id作为订单分片字段后,我们就要开始考虑分片的策略问题了。
目前,市面上通用的分片策略分为根据范围分片、根据hash值分片,根据hash值及范围混合分片这三种。
| 用户id范围 | 数据库名 | 表名 |
|---|---|---|
| 0-99999 | Order_0 | t_order_00 |
| 100000-199999 | Order_0 | t_order_01 |
| 200000-299999 | Order_0 | t_order_02 |
| … | Order_0 | … |
| 900000-999999 | Order_0 | t_order_09 |
| 1000000-1099999 | Order_1 | t_order_10 |
特殊说明:这里我们只说分表,至于分库则是把分表分组存放在一个库即可,就不另行说明了。
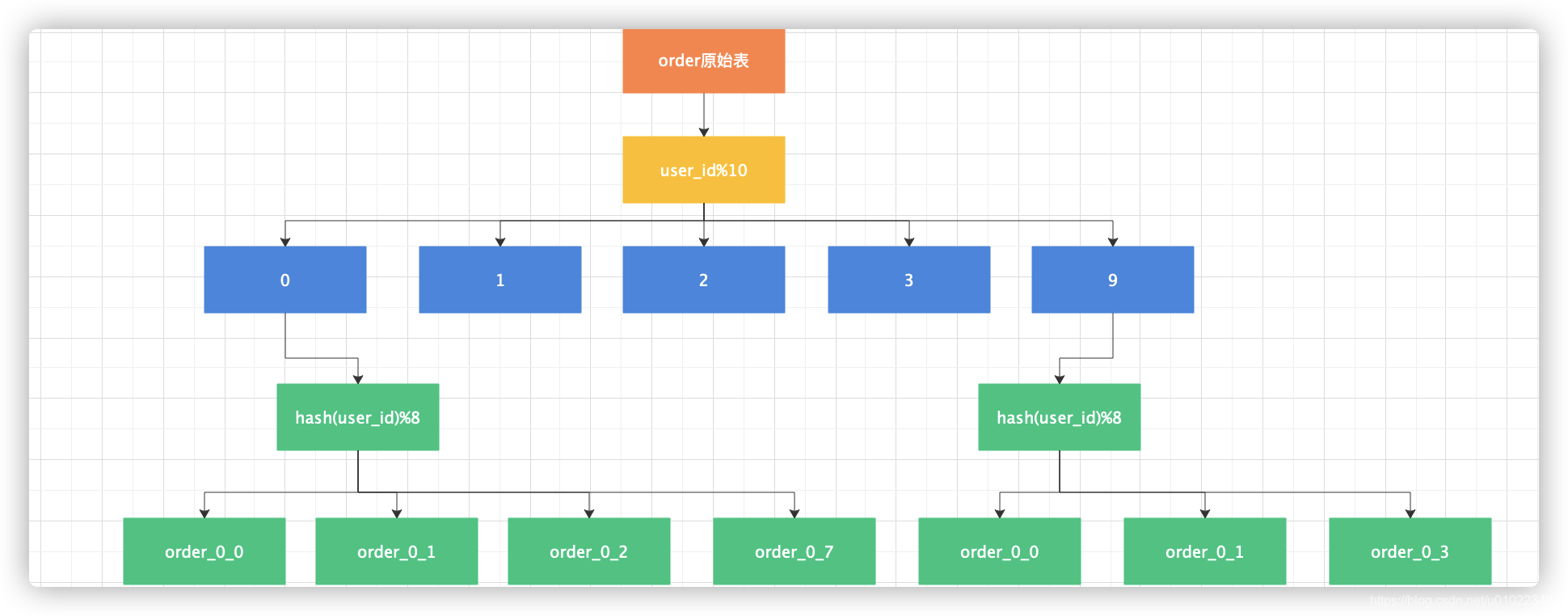
因此,根据hash值分片时我们一般建议拆分成2的N次方表,比如分成8张表,数据迁移时把原来的每张表拆一半出来组成新表,这样数据迁移量就小了。
当初的方案中,我们就是根据用户id的hash值取模32,把数据分成32个数据库,每个数据库再拆分成16张表。
我们简单算了下,假设每天订单1000万,每个库日增1000万/16=31.25万,每个表日新增1000万/32/16=1.95万。而如果每天千万订单量,3年后每个表的数据量就是2000万左右,也还在可控范围内。
因此,如果业务增长特别快,且运维还扛得住,为避免以后出现扩容问题,我们建议库分的越少越好。
分片策略定完以后,我们就要考虑业务代码如何修改了。因修改业务代码部分与业务强关联,所以我们的方案并不具备参考性。
这里分享些个人观点。近年来,分库分表操作愈发简单,不过我们需要注意几个要点:
一般来说,业务代码的修改不会很复杂,最麻烦的是历史数据的迁移。
历史数据的迁移非常耗时,有时迁移几天几夜都很正常。在互联网行业中,别说几天几夜了,就连停机几分钟业务都无法接受,这就要求我们给出一个无缝迁移的解决方案。
还记得在聊查询分离时,讨论过的解决方案吗?我们来回顾下,如下图所示:感兴趣的朋友可以看看之前的文章:数据库表数据量大读写缓慢如何优化(2)【查询分离】
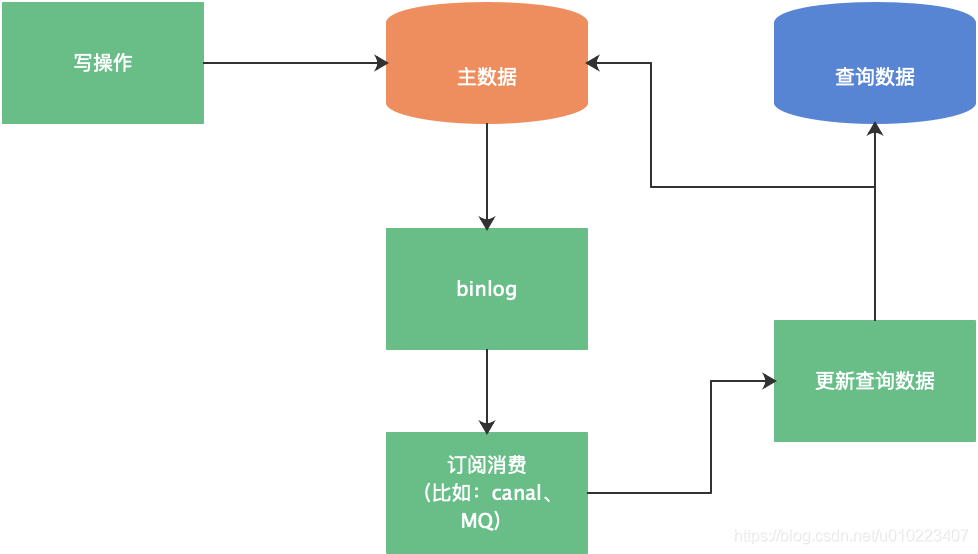
历史数据迁移时,我们就是采用类似的方案进行历史数据迁移,如下图所示:
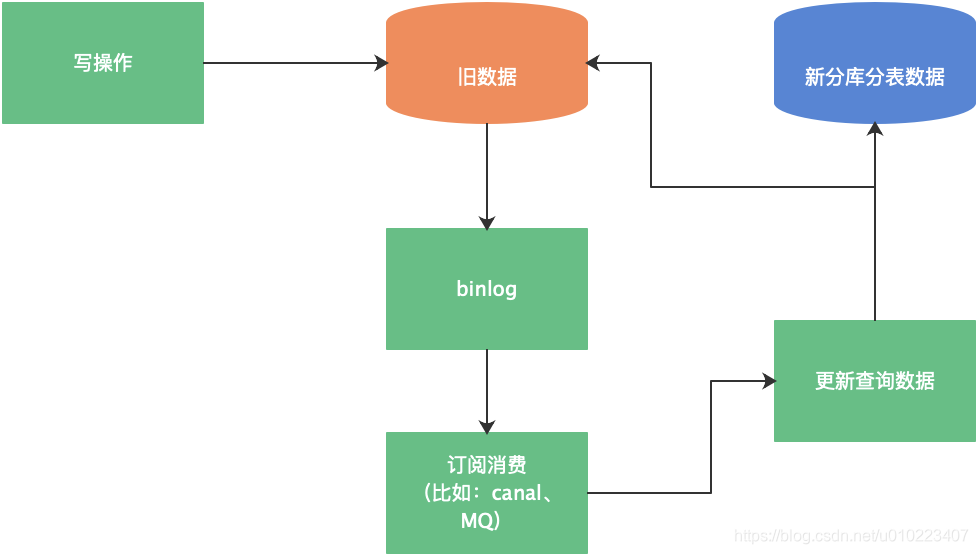
此数据迁移方案的基本思路:存量数据直接迁移,增量数据监听binglog,然后通过canal通知迁移程序搬运数据,新的数据库拥有全量数据,且校验通过后逐步切换流量。
数据迁移解决方案详细的步骤如下:
随着业务的发展,如果原来的分片设计已经无法满足日益增长的数据需求,我们就需要考虑扩容了,扩容方案主要依赖以下两点:
分库分表的解决方案聊完了,以上就是业界常用的一些做法,不过此方案仍存在不足之处。
感兴趣的小伙伴欢迎关注公众号“服务端技术精选”,还有更多好玩的等你哟
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
