社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前言:程序员写的网络程序, 都是在应用层。所以应用层对于网络编程是一个很重要的部分,我们应该好好学习这部分的知识。
计算机网络基础知识扫盲:https://blog.csdn.net/hansionz/article/details/85224786
网络编程套接字(socket):https://blog.csdn.net/hansionz/article/details/85226345
Udp和Tcp通用服务器的实现:https://blog.csdn.net/hansionz/article/details/86358191
在扫盲博客中谈到协议是一种 "约定"。所有socket api的接口,在读写数据时, 都是按 "字符串"的方式来发送接收的。但是如果我们要传输一些 "结构化的数据",就必须要自己制定网络协议。
我们可以自己制定协议来实现一个网络版的计算器:
首先,我们应该制定一份共同的约定,既网络协议:
运算数和运算方法结构体表示返回结果和状态值(表示返回结果的正确性)规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体。这个过程叫做"序列化" 和"反序列化"我们可以将Tcp通用服务器做一个简单的修改:
//comm.h
typedef struct Request
{
int x;
int y;
int op;//+-*/%--->12345
}Request_t;
typedef struct Respon
{
int res;
int flag; //0 1 2
}Respon_t;
//tcp_server.hpp
static void service(TcpSocket sock)
{
Request_t requ;
Respon_t resp;
for(;;){
memset(&requ, 0 ,sizeof(requ));
memset(&resp, 0, sizeof(resp));
sock.Recv(requ);
resp.flag = 0;
switch(requ.op){
case 1:
resp.res = requ.x + requ.y;
break;
case 2:
resp.res = requ.x - requ.y;
break;
case 3:
resp.res = requ.x * requ.y;
break;
case 4:
{
if(requ.y == 0){
resp.flag = 1;
}else{
resp.res = requ.x / requ.y;
}
}
break;
case 5:
resp.res = requ.x % requ.y;
break;
default:
resp.flag = 2;
cout << "[左操作数][运算符(12345--->+-*/%)][右操作数]" << endl;
break;
}
sock.Send(resp);
}
sock.Close();
}
//calc_client.cc
#include "tcp_client.hpp"
#include <string.h>
#include <stdio.h>
int main(int argc, char* argv[])
{
if(argc != 3)
{
cout << "Usage: ./dict_client [ip][port]" << endl;
return 1;
}
TcpClient client(argv[1], atoi(argv[2]));
client.Connect();
Request_t req;
Respon_t res;
while(1)
{
memset(&req, 0 ,sizeof(req));
memset(&res, 0, sizeof(res));
cout << "请输入[左操作数][右操作数]:";
cin >> req.x >> req.y;
cout << "请输入操作符[12345--->+-*/%]:";
cin >> req.op;
client.Send(req);
client.Recv(res);
cout << "结果是否正确:" << res.flag << endl;
cout << "运算结果:" << res.res << endl;
}
return 0;
}
从上面的网络计算器可以看出来应用层协议是程序员指定 。 但是已经有很多大佬们定义了一些现成的而且好用的应用层协议, 可以供我们直接参考使用,HTTP(超文本传输协议)就是的一个。
了解URL:URL是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
平常说的网址可以看做是URL:
HTTP URL (URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息)的格式如下:
http://host[":"port][abs_path]
http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或者IP地址;port指定一个端口号,为空则使用缺省端口80;abs_path指定请求资源的URI;如果URL中没有给出pbs_path,那么当它作为请求URI时,必须以“/”的形式给出,通常这个工作浏览器自动帮我们完成。
urlencode和urldecode:
在URL中像如/ ? : 等这样的字符, 已经被URL做特殊意义理解。 因此这些字符不能随意出现。 如果 某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义操作(编码和解码)。
urlencode的规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。比如:空格ASCII码是32,对应16进制是20,那么urlencode编码结果是:%20。
注:urldecode就是urlencode的逆过程,可以使用工具直接编码:urlencode。
Http请求报文:
请求行、消息报头、空行、请求正文(Header)时以冒号分割的键值对,每组属性之间使用n分隔,遇到空行表示报头部分结束方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。(Body),Body允许为空字符串。如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度Http响应报文:
HTTP响应消息。HTTP响应也是由四个部分组成,分别是:状态行、消息报头、空行、响应正文HTTP-Version表示服务器HTTP协议的版本,Status-Code表示服务器发回的响应状态代码,Reason-Phrase表示状态代码的文本描述Header为响应的属性, 冒号分割的键值对。每组属性之间使用n分隔,遇到空行表示Header部分结束Body。 Body允许为空字符串, 如果Body存在,则在Header中会有一个 Content-Length属性来标识Body的长度,如果服务器返回了一个html页面,那么html页面内容就是在 body中| 请求方法 | 方法描述 |
|---|---|
| GET | 请求获取Request-URI所标识的资源 |
| POST | 从客户向服务器发送一些信息 |
| HEAD | 请求获取资源的响应消息报头,请求的是关于文档的信息,而不是这个文档本身 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| TRACE | 请求服务器回送收到的请求信息,主要用于测试或诊断 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关的选项和需求 |
| PUT | 请求服务器存储一个资源,并用Request-URI作为其标识 |
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源。GET方法也可以向服务器传递参数,在wd后边的为传递的参数,常为搜索关键字等。
POST方法:要求被请求服务器接受附在请求后面的数据,常用于提交表单。
HEAD方法:HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
注:请求方法中所有方法全为大写,常用的方法只有GET和POST。
状态代码有三位数字组成,第一个数字定义了响应的类别,它有五种可能取值:
继续处理接收并处理进一步的操作语法错误或请求无法实现服务器未能实现合法的请求常见的状态码:
WWW-Authenticate报头域一起使用HTTP消息报头包括普通报头、请求报头、响应报头、实体报头。
每一个报头域都是由名字+“:”+空格+值 组成,消息报头域的名字是大小写无关的
普通报头:
请求报头: 请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
常见的请求报头:
Internet主机和端口号,它通常从HTTP URL中提取出来的。发送请求时,该报头域是必需的。允许多个域名同处一个IP地址,即虚拟主机。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。不过,这个报头域不是必需的,如果我们自己编写一个浏览器,不使用User-Agent请求报头域,那么服务器端就无法得知我们的信息了。响应报头: 响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。
重定向接受者到一个新的位置。Location响应报头域常用在更换域名的时候。User-Agent请求报头域是相对应的。实体报头: 请求和响应消息都可以传送一个实体。一个实体由实体报头域和实体正文组成,但并不是说实体报头域和实体正文要在一起发送,可以只发送实体报头域。实体报头定义了关于实体正文和请求所标识的资源的元信息。
(session)的功能。关于Cookie:https://www.cnblogs.com/bq-med/p/8603664.html
在HTTP1.0官方协议中并没有对keepalive的明确支持,所有的HTTP请求是如下流程:
如果要在HTTP1.0中支持keep alive,你必须明确的在header中加入Connection:keep-alive。
client 发起一个包含Connection:keep-alive的请求server收到请求后,如果server支持keepalive,回复一个包含Connection:keep-alive的响应,不关闭连接,否则回复一个包含Connection:close的响应,关闭连接。因为keepalive在很多情况下能够重用连接,减少资源消耗,缩短响应时间。所以在HTTP1.1中缺省就是支持keepalive的,如果响应方不支持keepalive,需要明确的标识Connection:close,Connection:keep-alive就没什么意义了。
GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头<request-line>中), 以?分割URL和传输数据,多个参数用&连接。例如:login.action?name=hyddd& password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体<request-body>中。 因此,GET的数据会在地址栏中显示出来,而POST提交,地址栏不会改变。
GET:特定浏览器和服务器对URL长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
POST的安全性要比GET的安全性高。通过GET提交数据,用户名和密码将明文出现在URL上,因为登录页面有可能被浏览器缓存, 其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了。
http协议是基于tcp协议实现的,所以http服务器的接口都是tcp那套,http协议是无状态的,服务器处理完一个请求应该关闭当前连接。
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
using namespace std;
class HttpServer
{
public:
HttpServer(string ip, uint16_t port)
:_sock(-1)
,_ip(ip)
,_port(port)
{}
void Start()
{
_sock = socket(AF_INET, SOCK_STREAM, 0);
if(_sock < 0){
perror("ues socket");
return;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(_ip.c_str());
addr.sin_port = htons(_port);
//绑定
int ret = bind(_sock, (sockaddr*)&addr, sizeof(addr));
if(ret < 0){
perror("ues bind");
return;
}
//监听
ret = listen(_sock, 5);
if(ret < 0){
perror("use listen");
return;
}
while(1)
{
struct sockaddr_in client_addr;
socklen_t len =sizeof(client_addr);
int newsock = accept(_sock, (struct sockaddr*)&client_addr, &len);
if(newsock < 0){
perror("use accept");
return;
}
cout <<"a client connect!"<<endl;
char req[1024];//用来接收请求报文
int rs = recv(newsock, req, sizeof(req) - 1, 0);
if(rs < 0){
perror("use recv");
return;
}
req[rs]=0;
cout << "Req:" << req << endl;
const char* hello = "<h1>hello world</h1>";
char res[1024];
//状态行 正文长度 空行 响应正文
sprintf(res, "HTTP/1.0 200 OKnContent-Length:%lunn%s",strlen(hello),hello);
send(newsock, res, sizeof(res), 0);
close(newsock);
}
}
private:
int _sock;
string _ip;
u_int16_t _port;
};
int main(int argc, char* argv[])
{
if(argc != 3){
cout << "Usage:./http_server[ip][port]" << endl;
return 1;
}
HttpServer* hs = new HttpServer(argv[1], atoi(argv[2]));
hs->Start();
delete hs;
return 0;
}
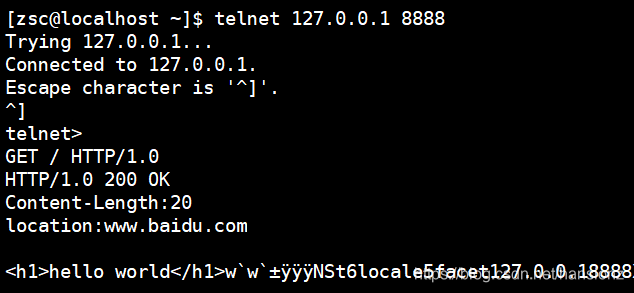
在本地运行起来服务器,绑定8888端口,使用telnet命令测试:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!