社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
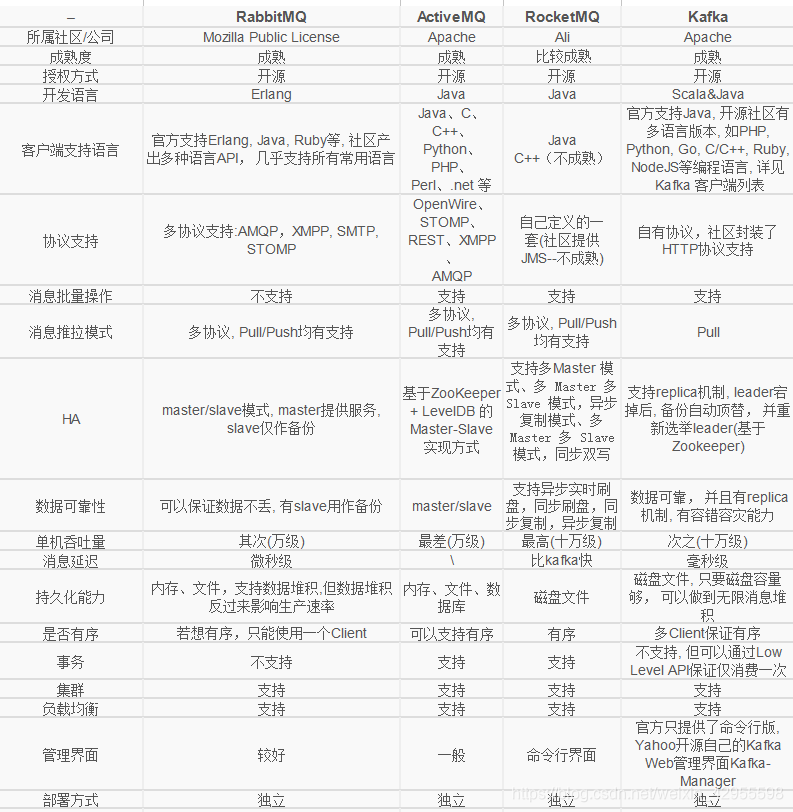
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
特性总结:
主要特性:
可靠性: 提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制;
灵活的路由: 消息在到达队列前是通过交换机进行路由的。RabbitMQ为典型的路由逻辑提供了多种内置交换机类型。如果你有更复杂的路由需求,可以将这些交换机组合起来使用,你甚至可以实现自己的交换机类型,并且当做RabbitMQ的插件来使用;
消息集群:在相同局域网中的多个RabbitMQ服务器可以聚合在一起,作为一个独立的逻辑代理来使用;
**队列高可用:**队列可以在集群中的机器上进行镜像,以确保在硬件问题下还保证消息安全;
多种协议的支持:支持多种消息队列协议;
服务器端用Erlang语言编写,支持只要是你能想到的所有编程语言;
管理界面: RabbitMQ有一个易用的用户界面,使得用户可以监控和管理消息Broker的许多方面;
跟踪机制:如果消息异常,RabbitMQ提供消息跟踪机制,使用者可以找出发生了什么;
插件机制:提供了许多插件,来从多方面进行扩展,也可以编写自己的插件;
优点:
1 由于erlang语言的特性,mq 性能较好,高并发;
2 健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
3 有消息确认机制和持久化机制,可靠性高;
4 高度可定制的路由;
5 管理界面较丰富,在互联网公司也有较大规模的应用;
6 社区活跃度高;
缺点:
尽管结合erlang语言本身的并发优势,性能较好,但是**不利于做二次开发和维护**;
实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队。此特性使得RabbitMQ易于使用和部署,但是使得其运行速度较慢,**因为中央节点增加了延迟,消息封装后也比较大;**
需要学习比较复杂的接口和协议,**学习和维护成本较高**;
ActiveMQ
ActiveMQ是由Apache出品,ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能。
主要特性:
服从 JMS 规范:JMS 规范提供了良好的标准和保证,包括:同步或异步的消息分发,一次和仅一次的消息分发,消息接收和订阅等等。遵从 JMS 规范的好处在于,不论使用什么 JMS 实现提供者,这些基础特性都是可用的;
连接性:ActiveMQ 提供了广泛的连接选项,支持的协议有:HTTP/S,IP 多播,SSL,STOMP,TCP,UDP,XMPP等等。对众多协议的支持让 ActiveMQ 拥有了很好的灵活性。
支持的协议种类多:OpenWire、STOMP、REST、XMPP、AMQP ;
持久化插件和安全插件:ActiveMQ 提供了多种持久化选择。而且,ActiveMQ 的安全性也可以完全依据用户需求进行自定义鉴权和授权;
支持的客户端语言种类多:除了 Java 之外,还有:C/C++,.NET,Perl,PHP,Python,Ruby;
代理集群:多个 ActiveMQ 代理可以组成一个集群来提供服务;
异常简单的管理:ActiveMQ 是以开发者思维被设计的。所以,它并不需要专门的管理员,因为它提供了简单又使用的管理特性。有很多中方法可以监控 ActiveMQ 不同层面的数据,包括使用在 JConsole 或者 ActiveMQ 的Web Console 中使用 JMX,通过处理 JMX 的告警消息,通过使用命令行脚本,甚至可以通过监控各种类型的日志。
优点:
跨平台(JAVA编写与平台无关有,ActiveMQ几乎可以运行在任何的JVM上)
可以用JDBC:可以将数据持久化到数据库。虽然使用JDBC会降低ActiveMQ的性能,但是数据库一直都是开发人员最熟悉的存储介质。将消息存到数据库,看得见摸得着。而且公司有专门的DBA去对数据库进行调优,主从分离;
支持JMS :支持JMS的统一接口;
支持自动重连;
有安全机制:支持基于shiro,jaas等多种安全配置机制,可以对Queue/Topic进行认证和授权。
监控完善:拥有完善的监控,包括Web Console,JMX,Shell命令行,Jolokia的REST API;
界面友善:提供的Web Console可以满足大部分情况,还有很多第三方的组件可以使用,如hawtio;
redis
redis中可以使用自带的publish和subscribe命令完成“消息推送”和“消息拉取”功能,实现消息队列。但这种方式有一个缺陷就是,消费者必须一致在线,否则会出现消费遗漏。
redis中的list(本质上是个双向链表)、zset(有序set)都可以用做“消息队列”的容器,稍加处理就可以实现一个高可用的“消息队列”。使用redis实现的“轻量化”“消息队列”有三大优势:
1、现在redis已经广泛运用于各大系统中,无需再次引入其他第三方框架和api。
2、并且redis是基于内存存储的,生产者和消费者的存取速度都非常快。
3、使用redis集群的的容量,可以通过添加实例进行扩展。
Kafka集群由若干个Broker组成,Topic由若干个Partition组成,每个Partition里面的消息通过Offset来获取。
Broker
当前服务器上的Kafka进程,俗称拉皮条。 只管数据存储,不管是谁生产,不管是谁消费。
一个集群由多个Broker组成,每个Broker都有一个唯一BrokerId,一个Broker可以容纳多个Topic。 每个Cluster当中会选举出一个Broker来担任Controller,负责跟其他Broker进行协调Topic创建、删除,处理Partition的Leader选举,协调Partition迁移等工作。
Topic
这是一个逻辑上的概念,Topic是发布的消息的类别。
物理上不同Topic的消息分开存储,一个Topic的消息虽然保存在一个或多个Broker上,但对于用户来说,只需要确定消息的主题Topic即可,生产或消费数据时不需要关心数据存放在何处。
Partition
Partition是物理上的概念,为了实现可扩展性,一个Topic可以被分为多个Partition,从而分布到多个Broker上。
Partition中的每条消息都会被分配一个自增Id(Offset)。
Kafka只保证按一个Partition中的顺序将消息发送给消费者,但是不保证单个Topic中的多个Partition之间的顺序。
Offset
消息在Topic的Partition中的位置,同一个Partition中的消息随着消息的写入,其对应的Offset也自增,其内部实现原理如下图:
Producer
消息生产者,即将消息发布到指定的Topic中,同时Producer也能决定此消息被路由到哪个Partition,比如基于Random(随机)、Round-Robin(轮询)方式或者Hash(哈希)方式等一些算法。
Consumer
消息消费者,即想指定的Topic获取消息,根据指定Topic的分区索引及其对应分区上的Offset来获取消息。
Consumer Group
每个Consumer都属于一个Consumer group;反过来,每个Consumer Group中可以包含多个Consumer。
如果所有的Consumer都具有相同的Consumer Group,那么消息将会在Consumer之间进行负载均衡。
也就是说一个Partition中的消息只会被相同Consumer Group中某个Consumer消费,每个Consumer Group消息消费是相互独立的。
如果所有的Consumer都具有不同的Consumer Group,则消息将会被广播给所有的Consumer。
Producer、Consumer和Consumer Group之间的关系如下图所示:
Replica
副本。Topic的Partition含有N个Replica,N为副本因子。
每个Partition都可以配置至少1个Replica(当仅1个Replication时即仅该Partition本身)
其中一个Replica为Leader,其他都为Follower,Leader处理Partition的所有读写请求,与此同时,Follower会定期地去同步Leader上的数据。
ISR(In-Sync Replica)
Replicas的一个子集,表示目前Alive且与Leader能够“Catch-up”的Replicas集合。
由于读写都是首先落到Leader上,所以一般来说通过同步机制从Leader上拉取数据的Replica都会和Leader有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该Replica踢出ISR。
每个Partition都有它自己独立的ISR。
Controller
Kafka集群中的其中一个服务器,用来进行Leader Election以及各种Failover。
Zookeeper
存放Kafka集群相关元数据的组件 在Zookeeper集群中会保存Topic的状态信息,例如分区的个数、分区的组成、分区的分布情况等。
保存Broker的状态信息。
保存消费者的消费信息。注:从kafka-0.8.2.1版本及以后,kafka的消费者组和offset信息就不存zookeeper了,而是存到broker服务器上
通过这些信息,Kafka很好地将消息生产、消息存储、消息消费的过程结合起来。
主要来源 : https://juejin.im/post/5ba73edde51d450e425ed11c
https://kafka.apache.org/intro
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
