社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
使用Python爬虫就是以下三个步骤,一个步骤对应一篇文章。
本文章就介绍Python爬虫的第一步:请求网页。
requests是一个Python HTTP客户端库,使用Python爬虫时少不了它,也是本章的重头戏。
首先,需要在cmd窗口输入以下命令,安装用于进行网络请求的requests模块。
pip install requests
这里只对requests的基本使用做介绍,更多的知识请点击requests官方文档。
requests模块有多种请求方式,这里只对最常用两个请求做介绍,分别是GET和POST请求
| 方法 | 描述 |
|---|---|
| requests.get() | 请求指定的页面信息,并返回实体主体 |
| requests.post() | 向指定资源提交数据进行处理请求(例如提交表单) |
下面开始的第一步,是需要先将requests模块导入。
import requests
成功示例:
resp = requests.get('https://www.baidu.com')
print(resp.status_code) # 200 如果状态码返回值是200 则表示访问成功
失败示例:
resp = requests.get('https://www.douban.com/') #豆瓣首页
print(resp.status_code) # 418 这里状态码返回为418,很明显是请求不成功该网址的,下面再说如何处理
示例:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
}
data = {
'name': 'xxx', # 账号
'password': 'xxx' # 密码
}
# 携带headers与data进行请求
resp = requests.post('https://accounts.douban.com/j/mobile/login/basic', data=data, headers=headers)
print(resp.status_code) # 200 请求成功
print(resp.text) # text为获得响应体文本信息 {"status":"success","message":"success","description":"处理成功"...}}
再来看看添加了请求头(伪装身份)后的请求结果:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
} # 这里用的是谷歌浏览器的请求头
r = requests.get('https://www.douban.com/', headers=headers) # 豆瓣首页
print(r.status_code) # 200 携带headers请求后,访问成功
请求头里还可以添加cookie,referer等参数,这里就不再做介绍,后面的文章中会说道如何使用他们。
主要三种方法:
r = requests.get('http://www.xxx.com')
| 方法 | 描述 | 用处 |
|---|---|---|
| r.text | 返回响应体文本信息 | 文本内容 |
| r.content | 返回二进制响应内容 | 图片、音乐、视频等’ |
| r.json() | 返回json内容,将返回内容中的数据以键值对的方式提取出来 | json格式的网页 |
主要分为5大类:
| 状态码 | 描述 |
|---|---|
| 1** | 指示信息–表示请求已接收,继续处理 |
| 2** | 成功–表示请求已被成功接收、理解、接受 |
| 3** | 重定向–信息不完整需要进一步补充 |
| 4** | 客户端错误–请求有语法错误或请求无法实现 |
| 5** | 服务器端错误–服务器未能实现合法的请求 |
查看响应头:
resp = requests.get('https://www.baidu.com')
print(resp.headers)
# {'Accept-Ranges': 'bytes', 'Cache-Control': 'no-cache'...} 返回的数据为dict
查看响应头的 Cache-Control:
resp = requests.get('https://www.baidu.com')
print(resp.headers['Cache-Control']) # no-cache
查看响应头的其它参数通过上。
以下内容引用自requests官方文档。
网页如下图: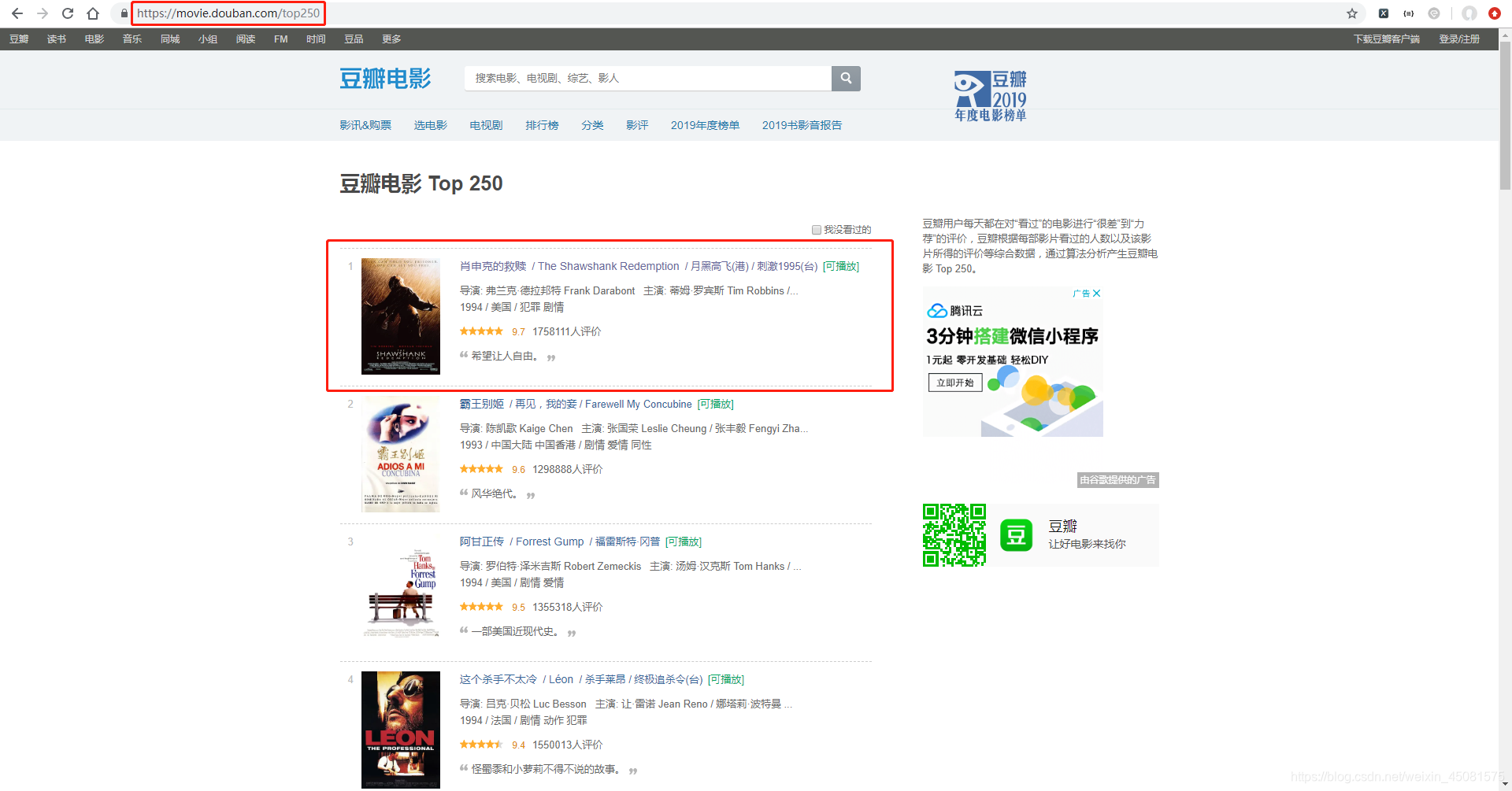
请求代码:
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
print(resp.text)
返回值如下:
<!DOCTYPE html>
<html lang="zh-cmn-Hans" class="">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">
<meta name="referrer" content="always">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<title>
豆瓣电影 Top 250
</title>
<body>
<ol class="grid_view">
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>1758111人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
'以下省略'......
</body>
</html>
首先,本文章写的狗屁不通,还请各位笔下留情,建议移步requests官方文档。

最后来总结一下本章的内容:

下一篇文章,名为 《Python爬虫从入门到放弃 05 | Python爬虫打响第一炮之解析网页》。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
