社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
用爬虫爬取某个网站的数据时,如果用一个IP频繁的向该网站请求大量数据,那么你的ip就可能会被该网站拉入黑名单,导致你不能访问该网站,这个时候就需要用到IP动态代理,即让爬虫爬取一定数据后更换IP来继续爬取。这个时候就需要代理IP池,当然,人民币玩家可以直接购买专业的IP代理服务,但是像我这种不想花钱的玩家,就只能通过爬取免费的代理网站上能用的IP来勉强维持生活。
现在我就讲下我是怎么获取大量IP,并检验获取的IP的活性:
首先选一个免费的代理IP网站,我选的是西刺代理:http://www.xicidaili.com/
用到的是python 中的requests库和 lxml库
requests。它是一个Python第三方库,处理URL资源特别方便,官方文档http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
要想使用requests,必须先进行安装:pip install requests
lxml。一个功能强大的Pythonic XML处理库,在这里主要用他的etree模块来定位并获得html和xml中的数据,安装命令:
pip install lxml
接下来进行代码的操作:()
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from lxml import etree
#请求路径,西刺代理网站
url = 'http://www.xicidaili.com/'
#请求响应头
headers = header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
#通过requests的get方法访问目标网站,获得响应对象
response = requests.get(url=url,headers=headers)
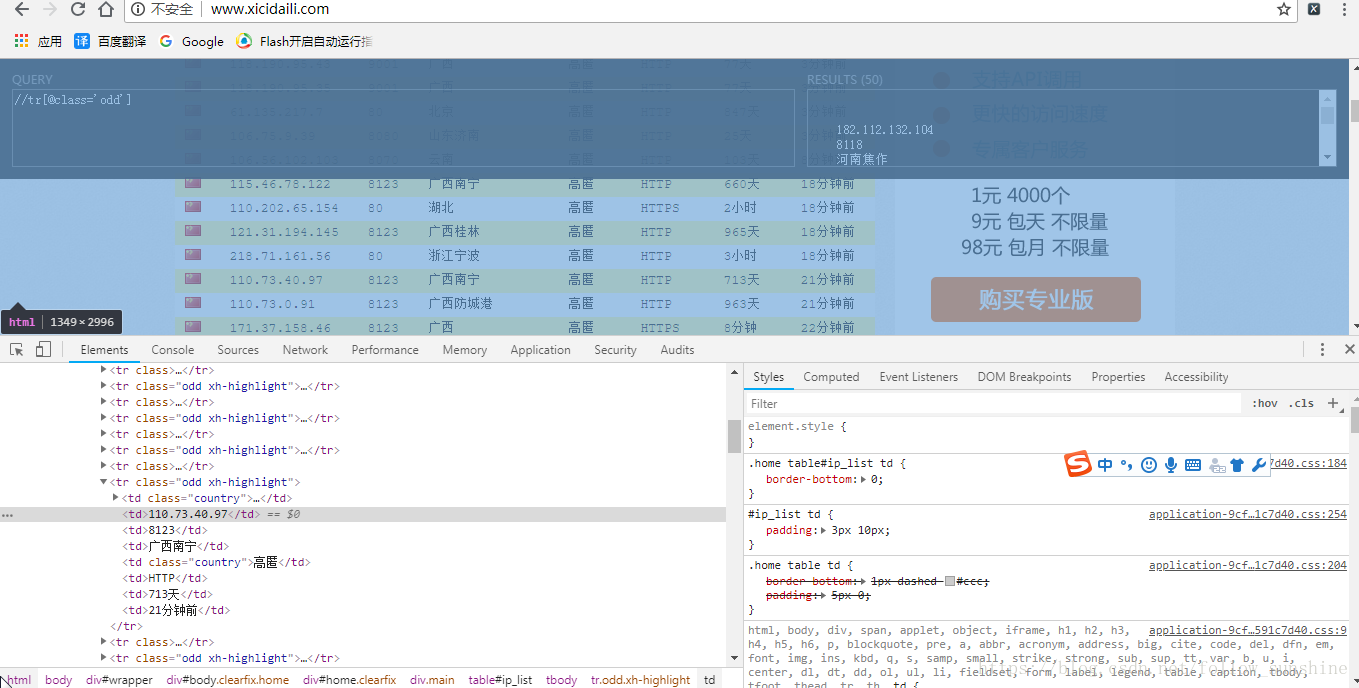
然后到西刺代理页面,通过chrome的开发者工具,通过xpath获取ip信息在页面中的位置:(这里如果用到xpath,需要用到google浏览器的xpath插件)
然后利用lxml中的etree对数据进行处理:
#创建一个etree对象,response.text为访问后的到的整个西刺代理页面
etree_obj = etree.HTML(response.text)
#通过筛选response.text,得到包含ip信息的列表
ip_list = etree_obj.xpath("//tr[@class='odd']")
item = []
#遍历得到的集合,将ip,和端口信息进行拼接,添加到item列表
for ip in ip_list:
ip_num = ip.xpath('./td[2]/text()')[0]
port_num = ip.xpath('./td[3]/text()')[0]
http = ip_num + ':' +port_num
item.append(http)
得到一个ip列表后就需要检测IP的活性:
#遍历访问,检测IP活性
for it in item:
#因为并不是每个IP都是能用,所以要进行异常处理
try:
proxy = {
'http':it
}
url1 = 'https://www.baidu.com/'
#遍历时,利用访问百度,设定timeout=1,即在1秒内,未送到响应就断开连接
res = requests.get(url=url1,proxies=proxy,headers=headers,timeout=1)
#打印检测信息,elapsed.total_seconds()获取响应的时间
print(it +'--',res.elapsed.total_seconds())
except BaseException as e:
print(e)
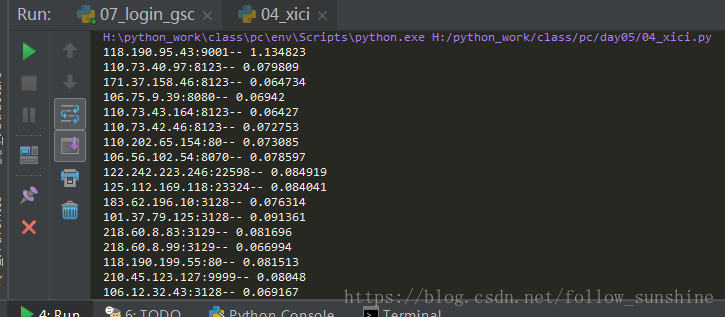
得到结果如下:(就可以将相应时间少于1秒的ip存放到列表中用来建立IP代理池)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!