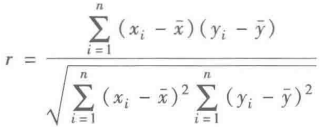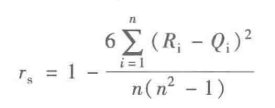社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据质量分析的主要任务是检查原始数据中是否存在脏数据:缺失值、异常值、不一致值、重复数据和含有特殊符号的数据。
1)缺失的原因:
3)缺失值分析
异常值是指样本中的个别值,其数值明显偏离其余的观测值。
1)简单统计分析
可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。常用统计量是最大值和最小值,用来判断这个变量的取值是否超出了合理的范围。
2)3δ原则
如果数据服从正态分布,在3δ原则下,异常值被定义为一组测量值中与平均值的偏差超过3倍标准差的值。如果数据不服从正态分布,可以用远离平均值的多少倍标准差来描述。
3)箱型图分析
箱型图提供了一个识别异常值的表准:异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。QL为下四分位数--表示全部观察值中有四分之一取值比它小;QU为上四分位数--表示全部观察值中有四分之一取值比它大;IRQ称为四分位数间距--表示上四分与下四分之差,期间包含了全部观察值的一半。
数据的不一致是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相违背的挖掘结果。
分布分析能揭示数据的分布特征和分布类型。
对于定量数据:想了解其分布形式是对称的还是非对称的、发现某些特大和特小的可疑值,可通过绘制频率分布图、频率分布直方图、茎叶图进行直观地分析。
对于定性分类数据:可用饼图、条形图直观地显示分布情况。
1)定量数据的分布分析
对于定量数据而言,选择“组数”和“组宽”是做频率分布分析时最主要的问题,一般按一下步骤进行:
2)定性数据的分布分析
对于定性变量,常常根据变量的分类类型来分组,可以采用饼形和条形图来描述定性变量的分布。
对比分析是对两个相互联系的指标进行比较,从数量上说明和展示研究对象规模的大小,水平的高低,速度的快慢,以及各种关系是否协调。特别适用于指标间的横纵向比较、时间序列的比较分析。对比分析主要有两种形式:
1)绝对数比较
利用绝对数进行对比,从而寻找差异的一种方法。
2)相对数比较
由两个有联系的指标进行对比计算,用以反映客观现象之间数量联系程度的综合指标,其数值表现为相对数。相对数可以分为以下几种:
用统计指标对定量数据进行统计描述,常从集中趋势和离中趋势两个方面进行分析。
平均水平的指标是对个体集中趋势的度量,使用最为广泛的是均值和中位数;反应变异程度的指标则是对个体离开平均水平的度量,使用较广泛的是标准差(方差)和四分位间距。
1)集中趋势度量
2)离中趋势度量
周期性分析是探索某个变量是否随着时间变化而呈现出某种周期性变化趋势
贡献度分析又称为帕累托分析,原则是帕累托法则,又称2/8定律。同样的投入放在不同的地方会产生不同的效益。
分析连续变量之间线性相关程度的强弱,并用适当的统计指标表示出来的过场叫相关性分析。
1)直接绘制散点图
判断两个变量是否有相关性最直观的方式是直接绘制散点图。
2)绘制散点图矩阵
需要同时考察多个变量间的相关关系时,可利用散点图矩阵同时绘制各变量间的散点图,从而快速发现多个变量间的主要相关性,这在进行多元线性回归时显得尤为重要。
3)计算相关系数
通过计算相关系数来进行相关分析
Pearson相关系数:一般用来分析两个连续性变量之间的关系。-1<=r<=1,r>0正相关,r<0负相关,r=0不存在相关性,|r|=1完全线性相关。
Spearman秩相关系数:不服从正态分布的变量、分类或等级变量之间的关联性可以采用Spearman秩相关系数,也称等级相关系数描述。
对两个变量成对的取值分别按照从小到大(或从大到小)顺序编秩,Ri代表Xi的秩次,Qi代表Yi的秩次
判定系数:是相关系数的平方。
1)D.sum():按列计算数据样本的总和。
2)D.mean():算数平均数
3)D.var():方差
4)D.std():标准差
5)D.corr(S2, method='pearson'):相关系数矩阵(pearson、spearman)
6)D.cov(S2):协方差矩阵
7)D.skew()/D.kurt():偏度(三阶矩)/峰度(四阶矩)
8)D.describe():直接给出基本统计量,如:均值、标准差、最大值、最小值、分位数等。
除了基本统计特征外,Pandas还提供了一些非常方便实用的计算统计特征的函数,主要分累计计算(cum)和滚动计算(rolling_),如下:
通过统计作图函数绘制的图标可以直观地反映出数据及统计量的性质及内在规律。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!