社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1.前提:最近项目一阶段的需求搞完,然后就闲下来看某乎看的不亦乐乎。。。正好本人看到某乎上说有人用python做了顶帖脚本并找到了女朋友((转)怎么用python找女朋友…),所以还等什么,python学起来!!!
鉴于本人比较懒完全看不下python基础啊((转)菜鸟教程了解一下),那就给自己找个需求一边搞需求一边学习python吧。
2.需求:实现自动登录chrome浏览器,登录公司erp系统并且自动填写用户名密码验证码
3.说明:①功能基本实现花了一天;②由于是站在巨人的肩上使用了轮子,所以有些代码并不是本人写的;③从中学习了python的基础常识和selenium应用,本人觉得这种通过某一功能去学习新的语言的方式挺好的,因此写下整个学习的过程。④文中引用了大量转载(毕竟是萌新),这些都是在学习过程中搜索到的靠谱的。
4.搭建python环境:
老样子,学一门语言先写一个helloworld。给个链接((转)IDEA 安装Python插件 + 创建Python项目),类似的还有很多直接度娘就好了,本文主要是说一下流程和注意点。
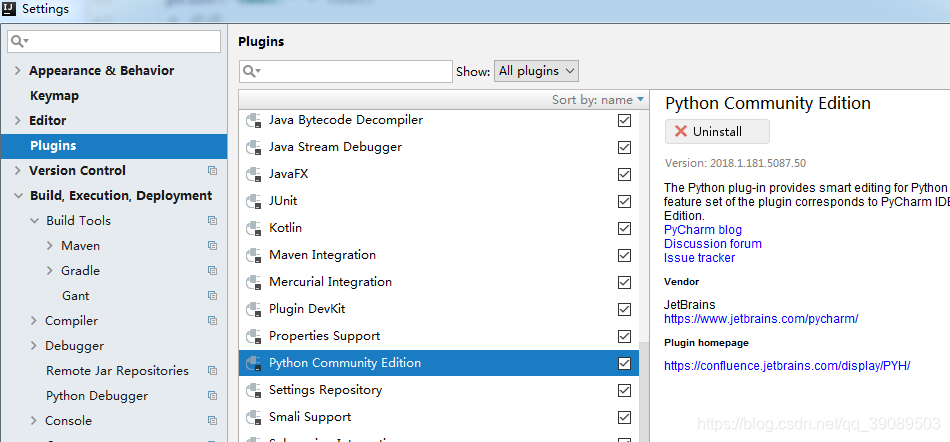
4.1:这里直接使用的是IDEA社区版
idea插件是python community edition,在setting-plugins中搜索python然后安装插件
python是3.7的64位exe文件
windows x86 executable 表示windows 32位系统 可执行文件
windows x86-64 embeddable zip 表示windows 64位系统 zip压缩文件
以此类推看自己要下哪一个
4.2流程:
安装python,配置环境变量path,cmd查看

安装ieda,安装插件,创建工程(这边都有教程也没有难点),创建helloworld文件
看下结构: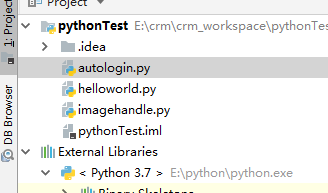
4.3 helloworld
好了,到这里就要开始了解python的一些知识点了。
由于本人是学java的,所以一开始觉得python的编码风格很别扭,比如命名,文件名是全小写的(其他规范在实际中体验);还有就是代码规范,main函数,缩进,最后一行空行等(这里只是接触到的,其他的可以看菜鸟教学了解一下);IDEA有很完整的提示,对于学习有很大帮助的(基础操作就是瞎几把写然后看提示度娘再回来改)。。。
这边helloworld很简单,就是调用了main函数然后print一个HelloWorld!!((转)收藏的代码规范)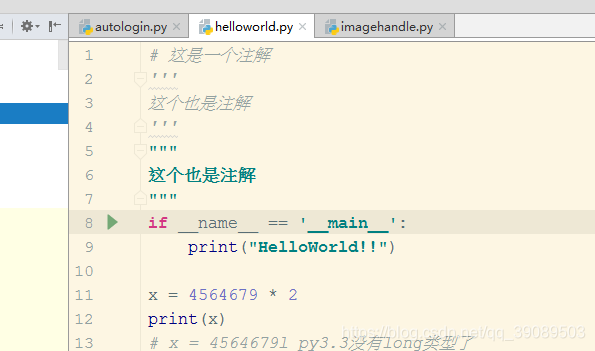
可以看到上图中还有一些变量等的实践,可以在这个文件中照着基础教学了解一下基础。
5.selenium和driver
好了,在helloworld中瞎写了一两个小时后,感觉已经不能满足我了,那么就开始需求吧。
5.1 启动chrome并登录
使用selenium和driver启动浏览器,总结了一下可用的方法
然后就可以启动了,比如百度
# 打开chrome
driver = webdriver.Chrome(chrome_driver, options=option)
driver.get('https://www.baidu.com/')
# 最大化谷歌
driver.maximize_window()
time.sleep(1)
感觉很完美,但是在登录公司内部erp系统时遇到了这个问题: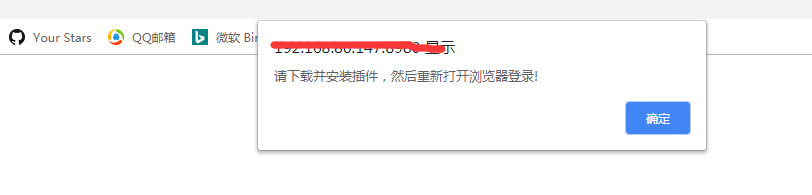
在IE上可以在安全设置中设置允许运行active脚本,然后就不会有这个下载提示框,但是chrome貌似不行。。。所以要解决这个alert才行。
5.2 模拟点击alert
autologin
# 弹窗自动点击
alert = driver.switch_to.alert
at_text = alert.text
print("at_text:" + at_text)
alert.accept()
核心就是switch_to.alert,这个是python3的写法,要注意,这样就能自动点击确认了
但是如果alert没有呢,也就是switch_to.alert 抛异常NoAlertPresentException。这边就涉及到异常处理了,正好学习一下。
autologin
from selenium.common.exceptions import NoAlertPresentException
import traceback
try:
alert1 = driver.switch_to.alert
except NoAlertPresentException as e:
print("no alert")
traceback.print_exc()
else:
at_text1 = alert1.text
print("at_text:" + at_text1)
5.3 获取页面元素并且自动填入
autologin
# 用户名密码
driver.find_element_by_id('parent_login_name').clear()
driver.find_element_by_id('parent_login_name').send_keys('cth')
driver.find_element_by_id('ext-comp-1002').clear()
driver.find_element_by_id('ext-comp-1002').send_keys('789456')

这边是使用id去定位用户名和密码的输入框(转)定位元素的方式
但是又出问题了,验证码怎么搞?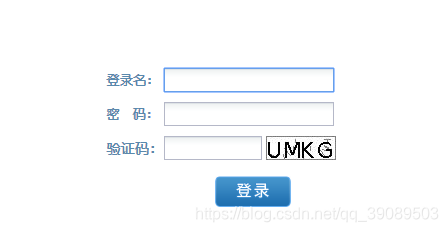
好吧,那就用图片识别吧,毕竟python的图像识别挺好的
6 使用PIL,pytesseract,tesseract对图像识别
6.1 首先是pillow和pytesseract,这个和selenium一样,直接cmd输入即可:
pip install pytesseract
pip install Pillow
然后是安装tesseract:
网上也有说配置path环境,但是在代码中加入就行了
imagehandle
# tesseract.exe所在的文件路径
pytesseract.pytesseract.tesseract_cmd = "E:py-ocrTesseract-OCR\tesseract.exe"
(是因为转义)
6.2 识别代码:
到这里也已经下午三点,还有2小时下班了,看了大半天的各种知识脑子已经乱了,所以咋办,那就直接拿轮子吧
(转)图片验证码识别
这边我是将该方法作为一个模块引入的,所以去掉了main方法,就是这个imagehandle
autologin
# 识别验证码
driver.save_screenshot('E:py-picwhole.png')
imgelement = driver.find_element_by_id('safecode')
location = imgelement.location
size = imgelement.size
coderange = (int(location['x']), int(location['y']),
int(location['x'] + size['width']), int(location['y'] + size['height']))
img = Image.open('E:py-picwhole.png')
frame = img.crop(coderange) # 使用Image的crop函数,从截图中再次截取我们需要的区域
frame.save('E:py-pic\frame.png')
text = imagehandle.OCR_lmj("E:py-pic\frame.png") # 使用imagehandle
print("text:" + text)
这个也是网上看到的,忘了是哪篇了,思路就是先截全屏图,然后定位到验证码的方位,截取验证码,然后使用 imagehandle.OCR_lmj 对图片进行二值化,去噪处理。
在OCR_lmj函数中增加了去边框处理:
imagehandle
# 去掉边框
def remove_frame(img, width):
w, h = img.size
pixdata = img.load()
for x in range(width):
for y in range(0, h):
pixdata[x, y] = 255
for x in range(w - width, w):
for y in range(0, h):
pixdata[x, y] = 255
for x in range(0, w):
for y in range(0, width):
pixdata[x, y] = 255
for x in range(0, w):
for y in range(h - width, h):
pixdata[x, y] = 255
return img
def OCR_lmj(img_path):
.
.
.
out2 = remove_frame(out1,1)
out2.save('E:py-picimage_remove.png')
.
.
.
<–2018-11-28改–>发现先去边框再去噪声的图片更好
最后处理后的图片:whole是截全图,frame是截取验证码,img_bin是二值化,img_noise是去噪,img_remove是去边框。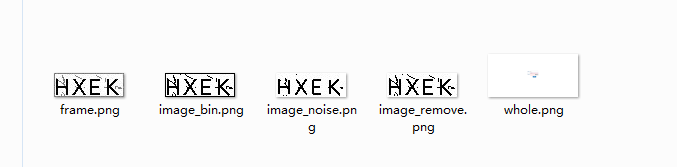
# 登录
driver.find_element_by_id('randCode').clear()
driver.find_element_by_id('randCode').send_keys(text) #text就是识别的数字和字母
driver.find_element_by_id('ext-gen29').click()
希望本文能够对其他人有用。。。
------------------------------------------2018-11-28---------------------------------------------------
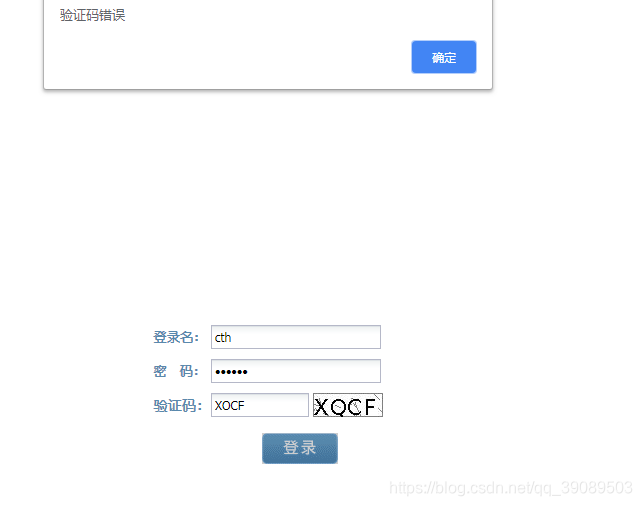
1.增加验证码识别错误处理:判断alert提示,如果是验证码错误会自动刷新,只需要重新识别登录,重复3次。实测十几次都成功了。。。
def ecpt_handle(driver, name, pwd):
for i in range(0, 3):
print("循环%d次" % (i+1))
# 验证码失败处理
try:
alert1 = driver.switch_to.alert
except NoAlertPresentException as e:
time.sleep(1)
print("登陆成功")
break
# traceback.print_exc()
else:
at_text1 = alert1.text
if at_text1 == "验证码错误":
print("at_text1:" + at_text1)
alert1.accept()
time.sleep(1)
print("重新登录%d次" % (i+1))
login(driver, name, pwd) # 重新识别并输入
time.sleep(3)
print("关闭")
driver.quit()
2.关于训练的方法: (转)tesseract训练
写的很全,照着试下果然成功率提升了
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
