社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
first
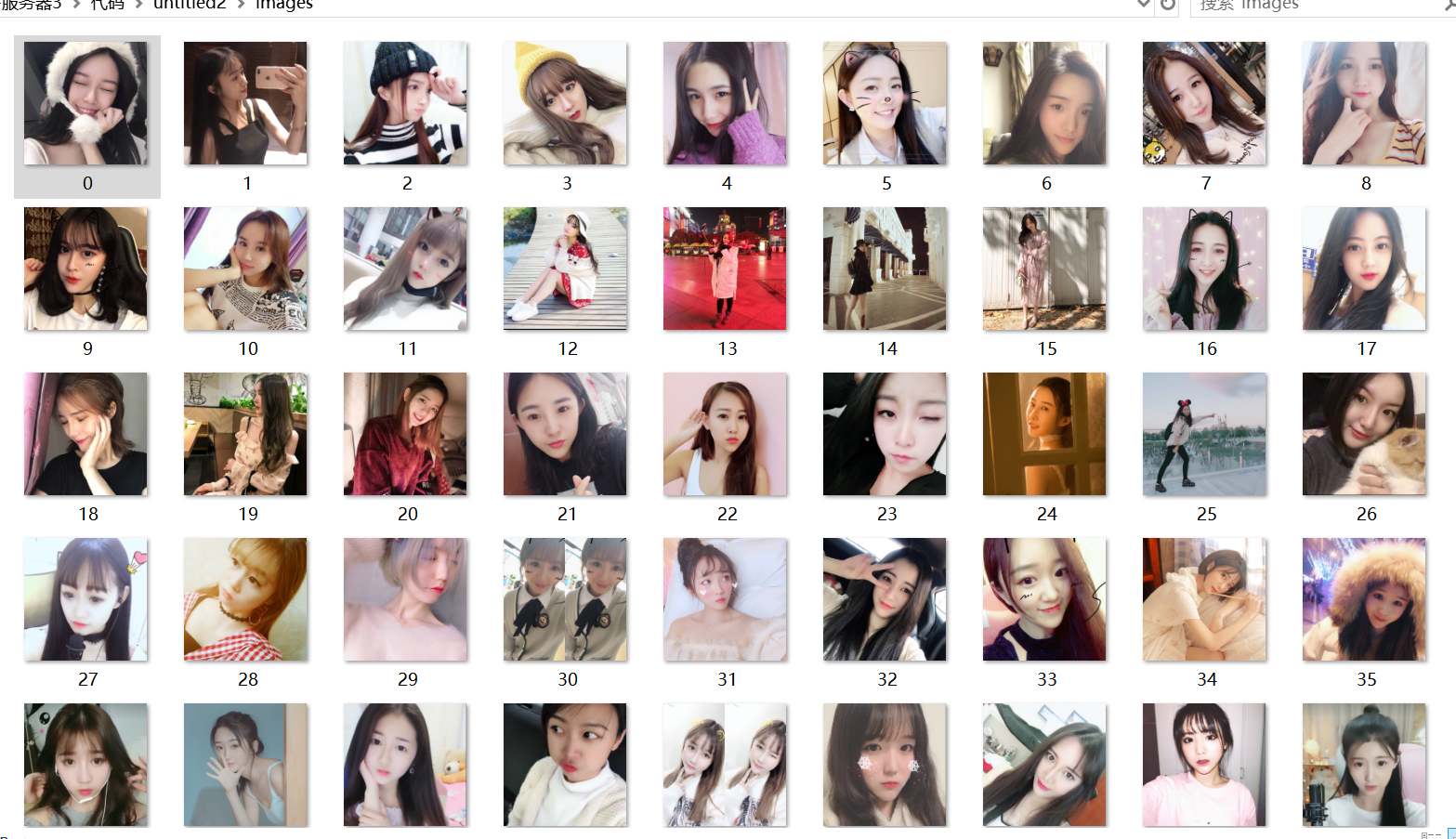
找到爬虫入口->获取目标链接->下载网页-> 解析网页 -> 获取价值信息 ->存库(文件保存)操作
爬什么呢?对就这个吧 别忘记f12 方便于开发人员欧
工具我就用py3好了,据说2020年官方将停止py2的更新。
second
#创建一个下载美女图片的方法
import urllib.request
import gevent
import gevent.monkey
gevent.monkey.patch_all() #把所有的耗时转化成gevent的函数
import re
def read_img():
with open("./cc.html") as f:
content = f.read()
#正则
reg = r'data-original="(https://.+.jpg)"' # 定义一个正则来匹配页面当中的图片
imgre = re.compile(reg) # 为了让正则更快,给它来个编译
imglist = re.findall(imgre, content)
return imglist #返回所有的图片 地址
def write_img(file_name,image_url):
#读取所有图片
req = urllib.request.urlopen(image_url)
content = req.read()
#写到文件中
with open("./images/%s.jpg"%file_name,'wb') as f:
f.write(content)
def main():
# down_img("./美女1.jpg","https://rpic.douyucdn.cn/live-cover/appCovers/2018/03/18/4356210_20180318215315_big.jpg")
# down_img("./美女2.jpg","https://rpic.douyucdn.cn/live-cover/appCovers/2018/01/30/2716613_20180130095710_big.jpg")
#
images = read_img()
spawns = list()
num = 0
for image_url in images:
spawns.append(gevent.spawn(write_img,num,image_url))
num += 1
#使用协程进行数据抓取
gevent.joinall(spawns)
if __name__ == '__main__':
main()
last
萌新在此膜拜大佬,
感谢捧场。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!