社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
近日,有小伙伴说想看一篇关于视频下载的文章,这不,拿bilibili来开刀了。
由于没有深入的对bilibili进行研究,导致文章可读性比较差,不喜勿喷。
虽是浅尝辄止。但是下载视频的目的可以达到。
关于清视频晰度:
| 方法 | 描述 |
|---|---|
| 未登录状态 | 抓取的视音频url参数:mid=0 |
| 登录状态 | 抓取的视音频url参数:mid=xxx(一串数字) |
如果是未登录状态,那就没有什么清晰度可言。
若你登录状态下打开一个视频,选择高清,那么!!用你这串mid去请求的视频都是高清(视频本身没有高清除外)。
在这里说下整体思路!
话不多说,下面开始!!!
文章以下图中的视频为例。文中为Firefox浏览器,方便展示抓包效果。
首先就是打开开发者工具抓包啦。如下图: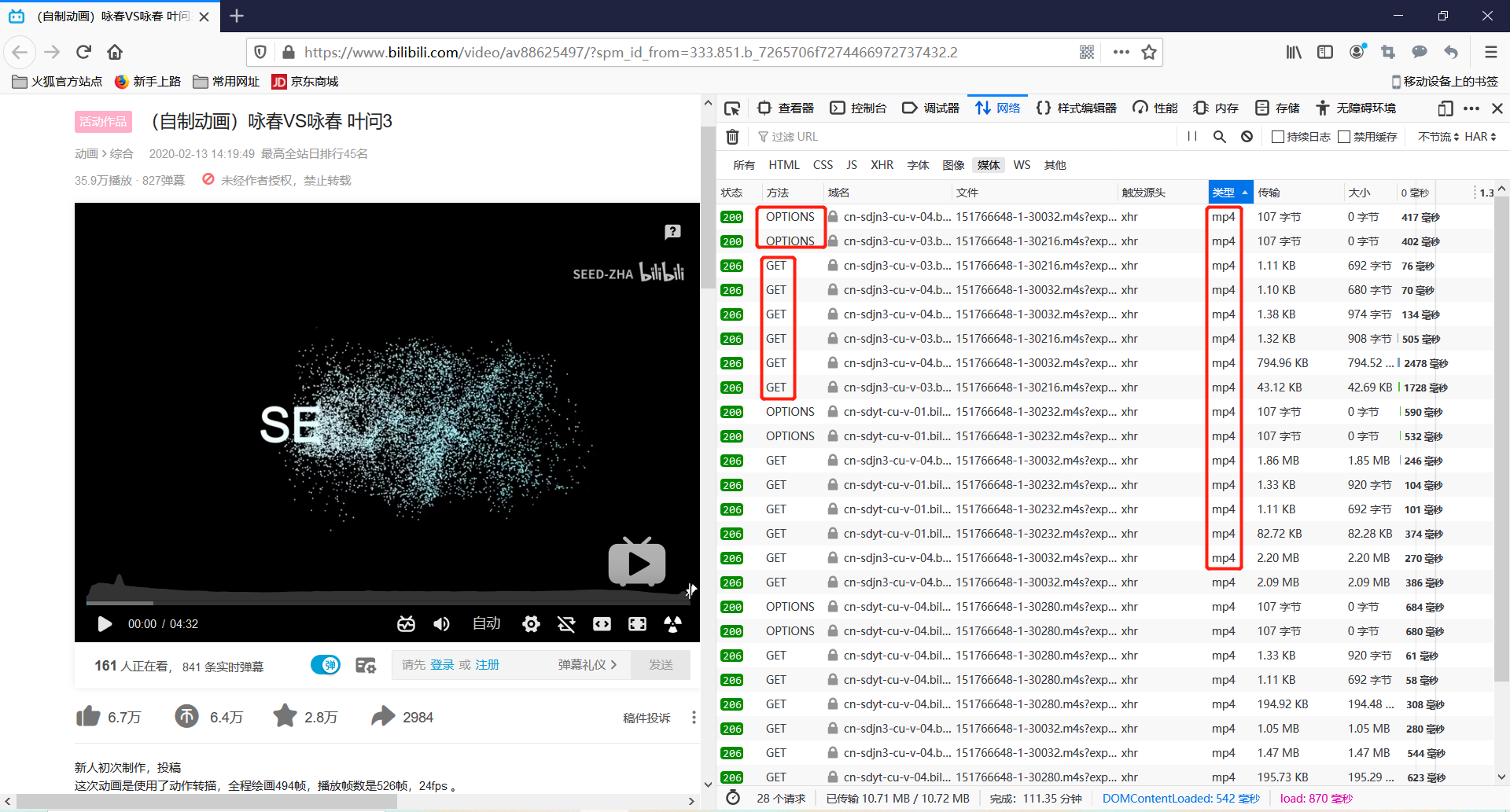
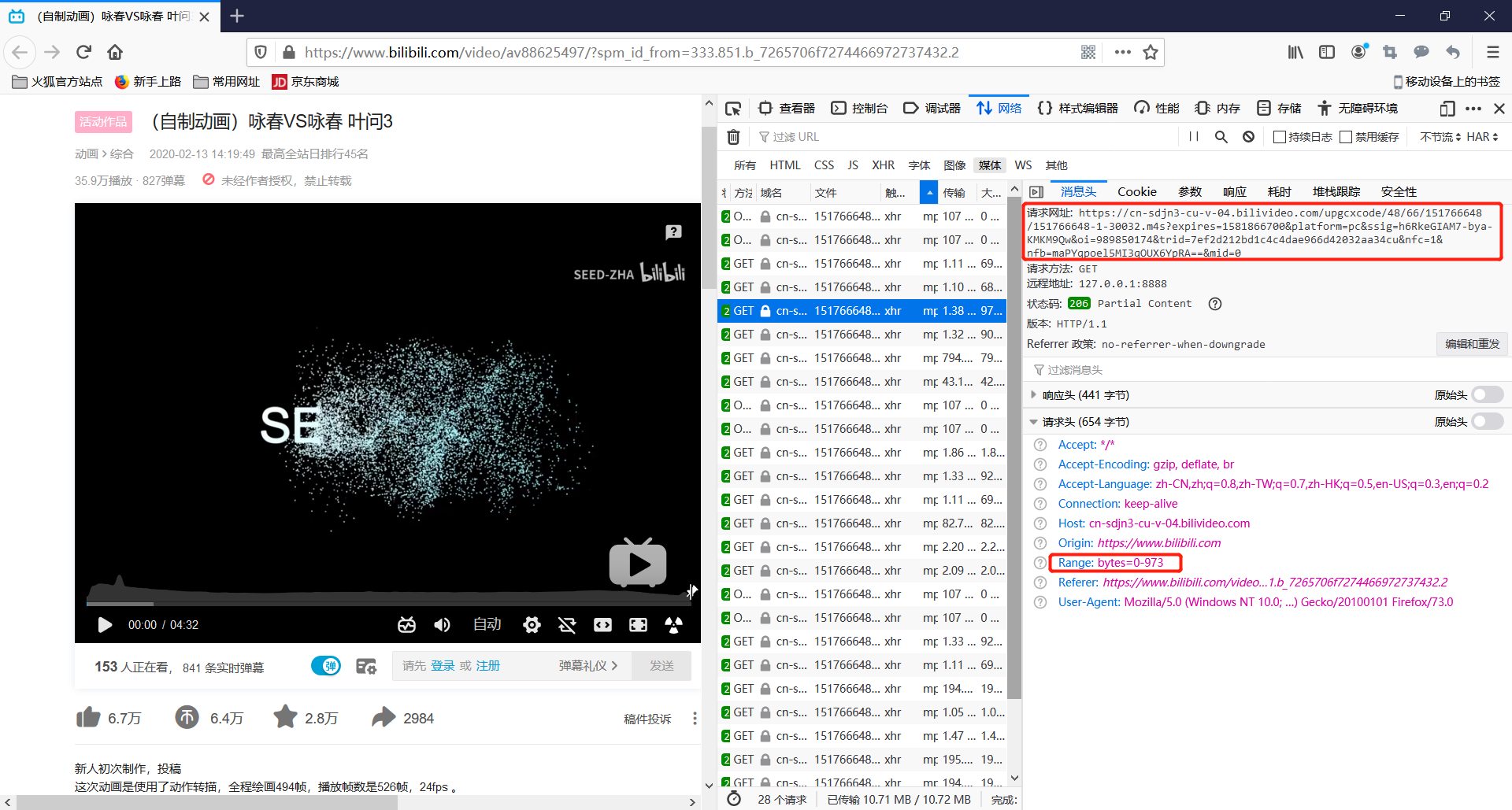
看到抓包页面的媒体分类,都是mp4格式的数据包,数据包的大小从107字节到2.30MB不等。有一个很有趣的规律如下:
既然如此,下面用代码来请求一下看看。
执行代码后,生成了一个1kb的test.mp4文件,很显然,打开时候报错了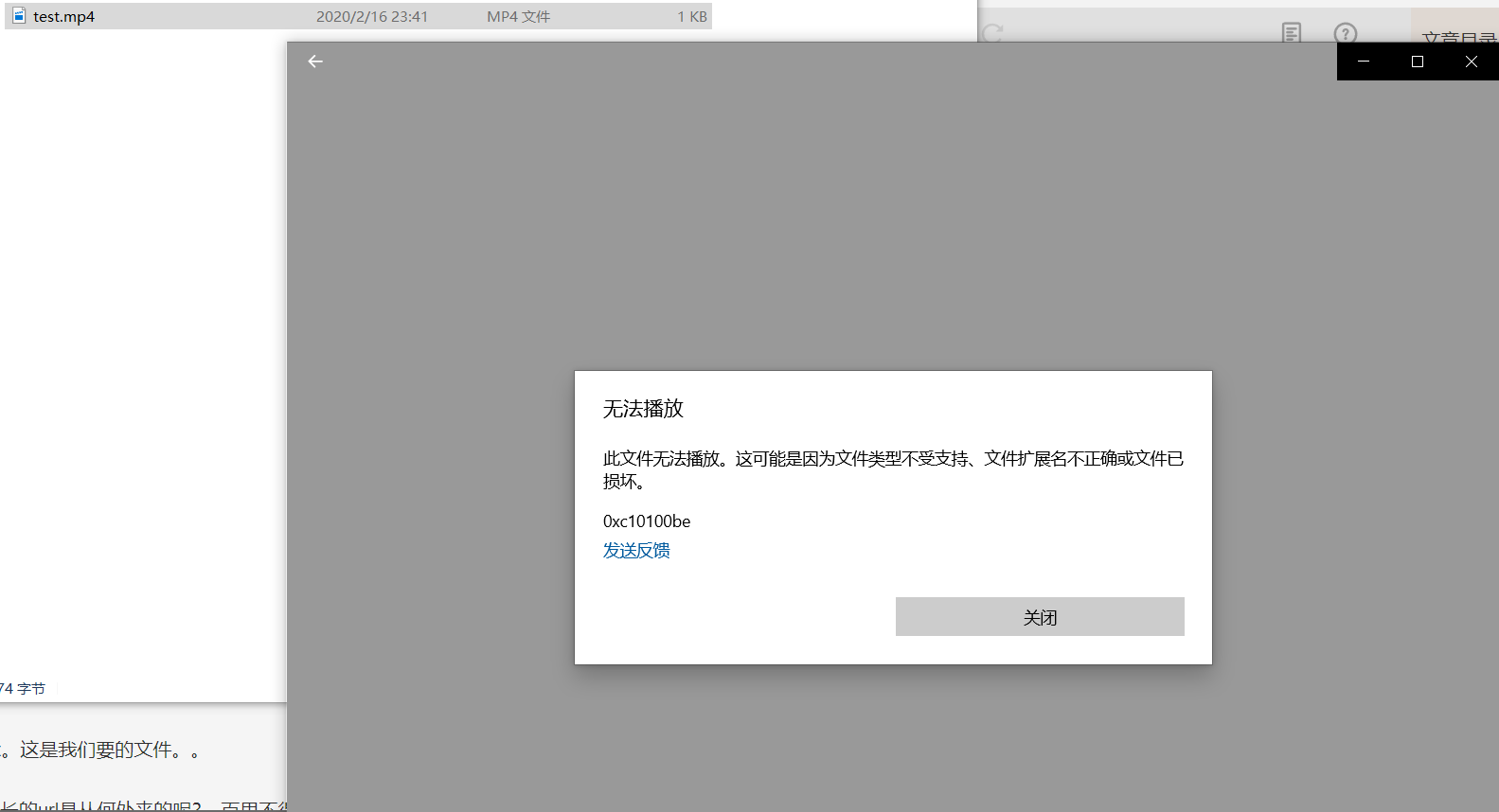
为什么会报错呢??我觉得是文件太小了,修改请求头的Range值为0-1024000,再次运行代码。
这次生成了一个1001kb的mp4文件,且可以播放!!但是视频没有声音,证实 了bilibili的视频文件是视音频分离的。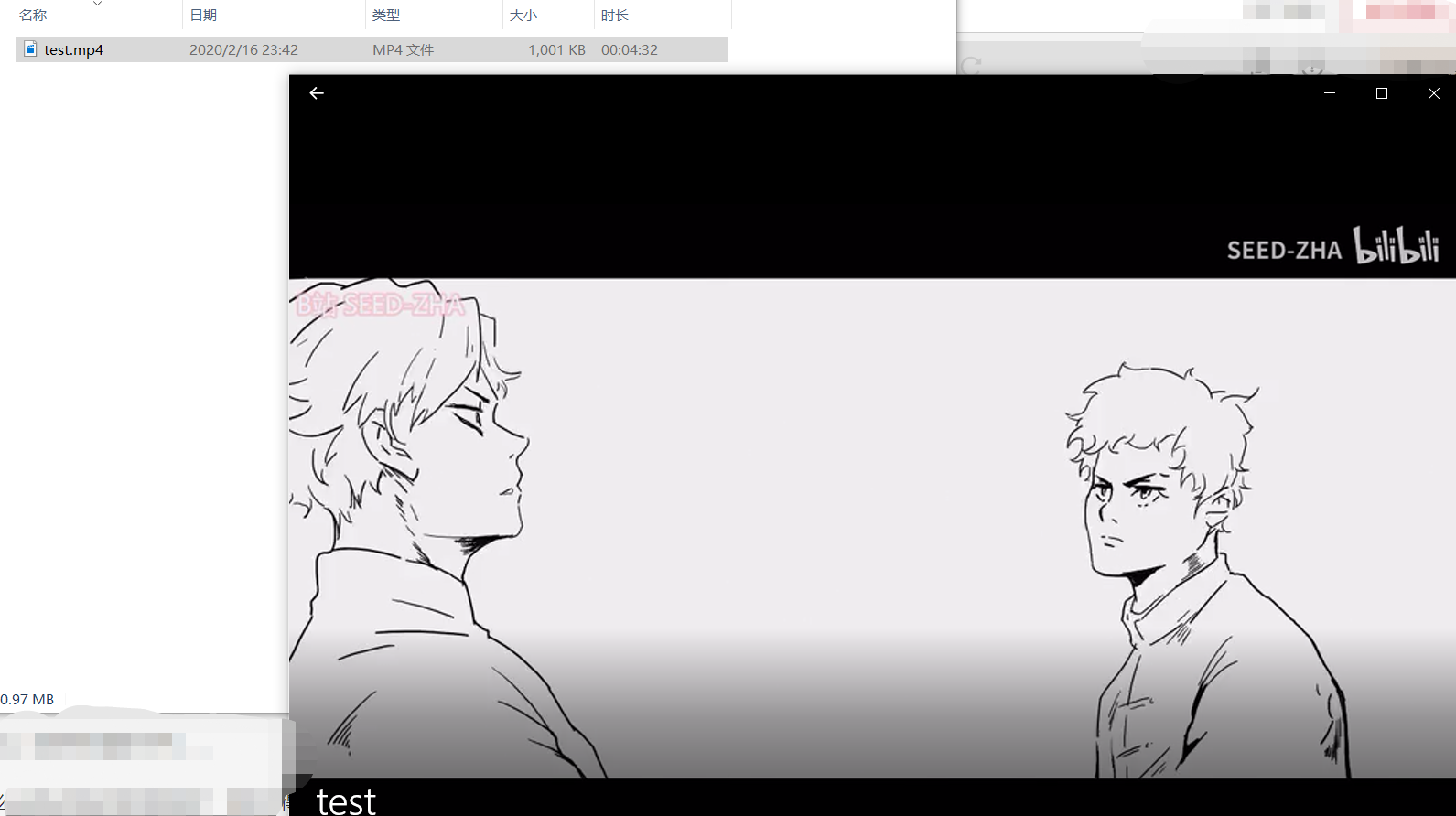
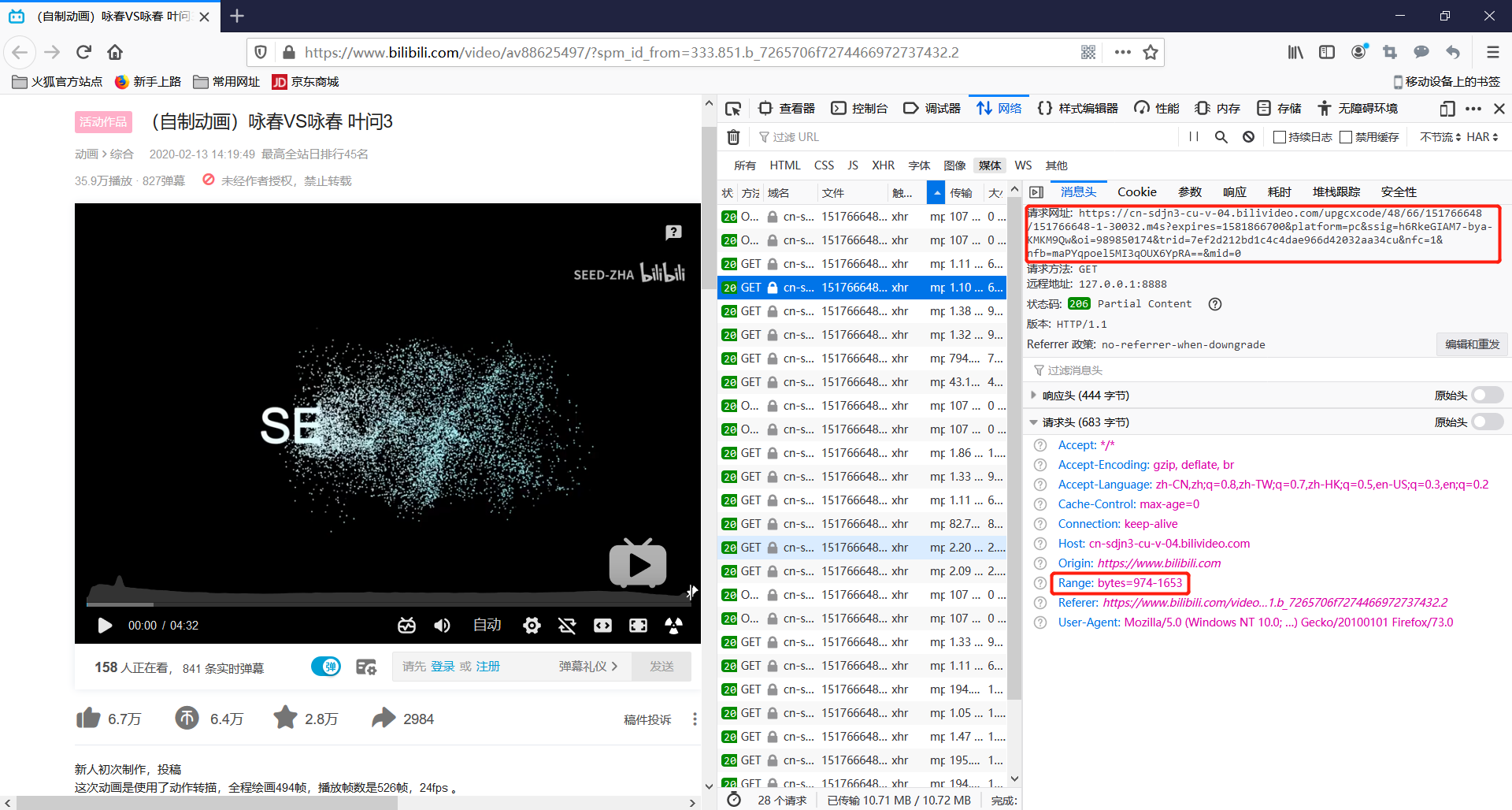
上面有说到,抓到的数据包大部分是两个重复的URL,现在请求另一个URL看看。
代码只是将URL做了修改,请求头没有变化。
(图中看不出是音频,但是是有声音的),这样,就完成本次抓包工作了。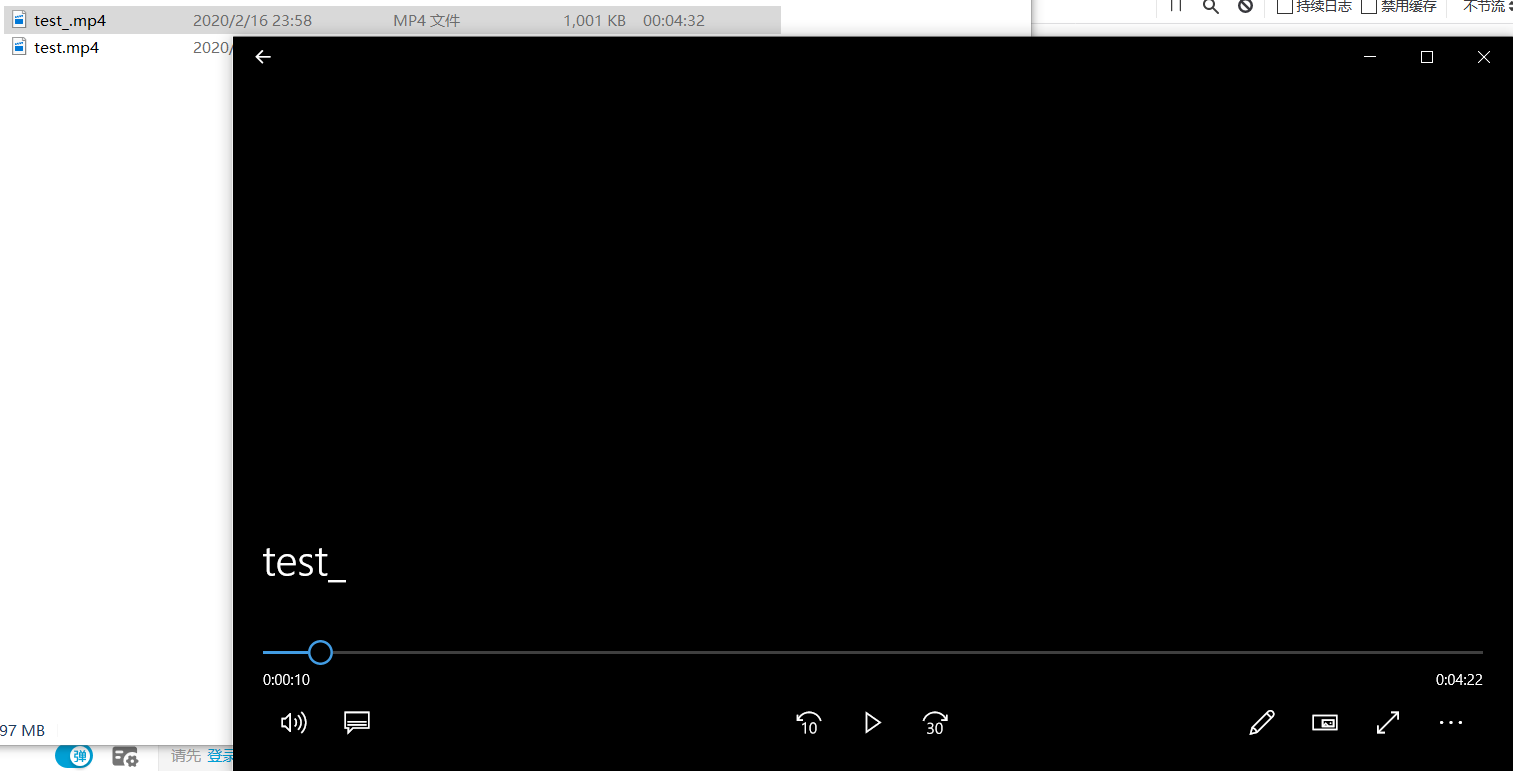
到了这里,抓包工作已经完成,视音频的由来也清楚了,那问题来了,这么长的一串URL是从哪里来的呢?
!!! 看源码。
百思不得其解,却忘记了最简单的方法,查看网页源码(花费了好一会儿时间才发现,原来源码里面就有!!!)
video的URL: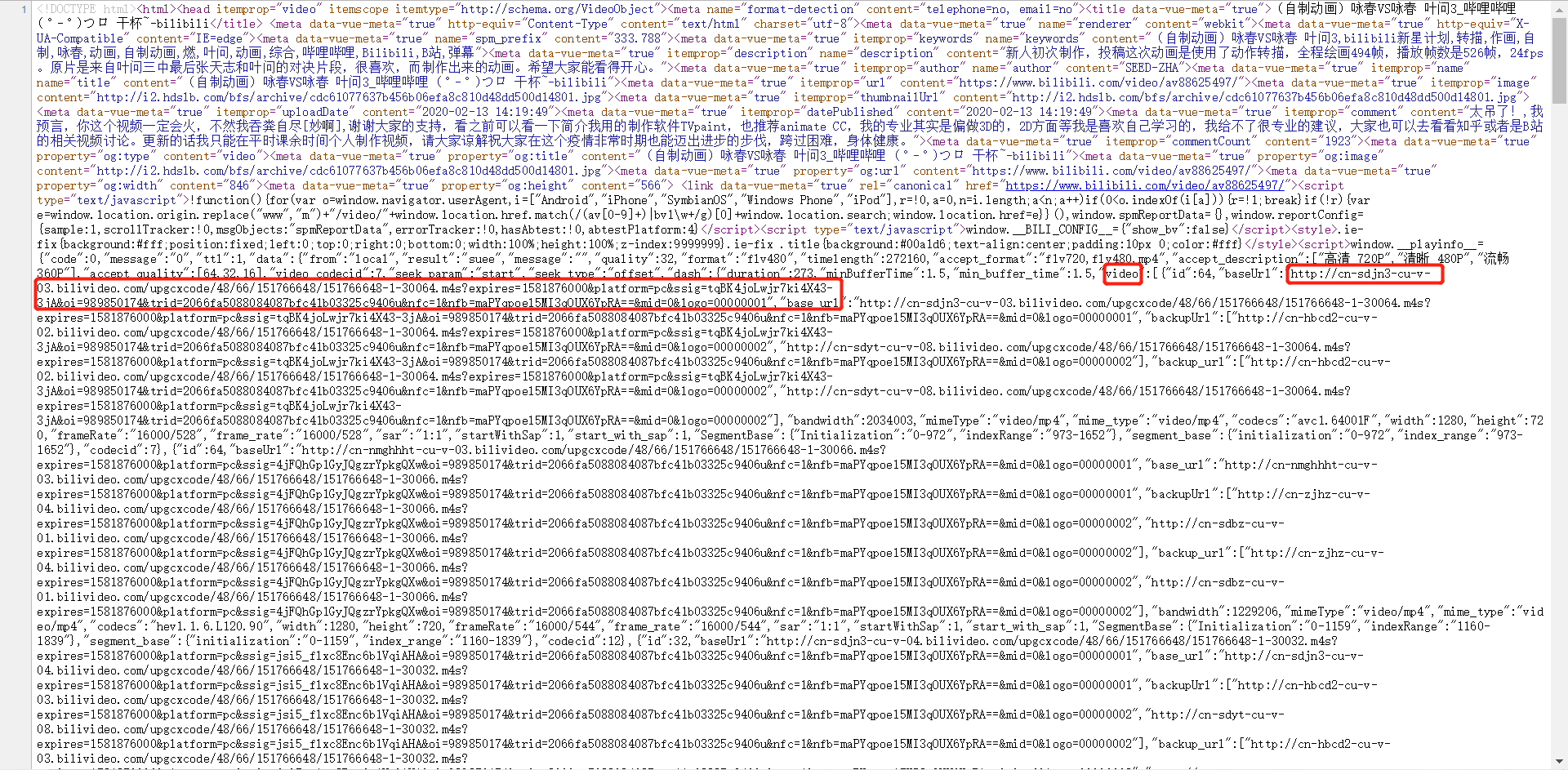
audio的URL: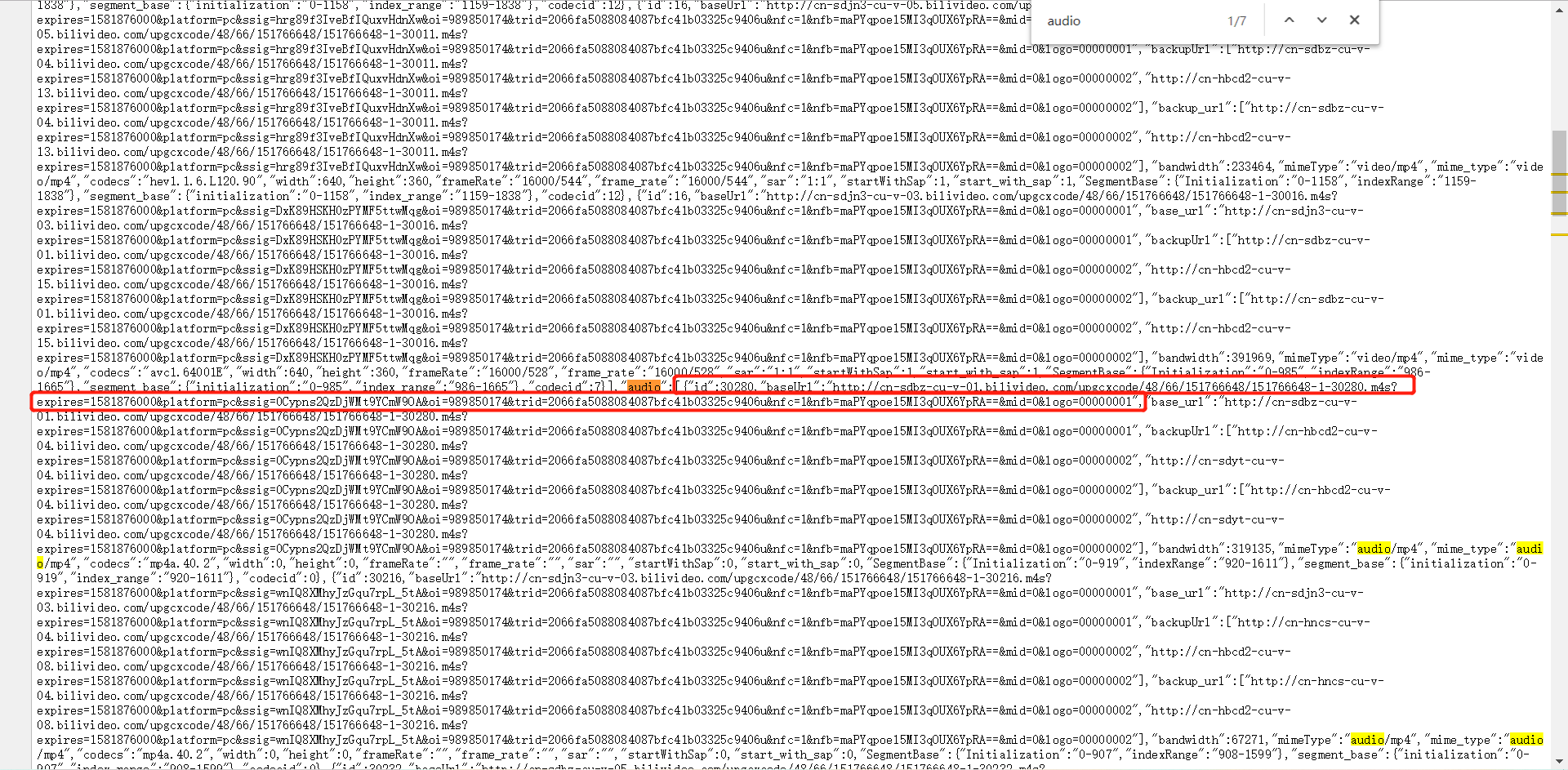
到了这里,剩下的用正则匹配源码里面的video和audio的URL都不是问题了吧!!!
剩余问题:
ps:这里用了其他视频做示例。
1.下载好的视音频:
2.打开格式工厂: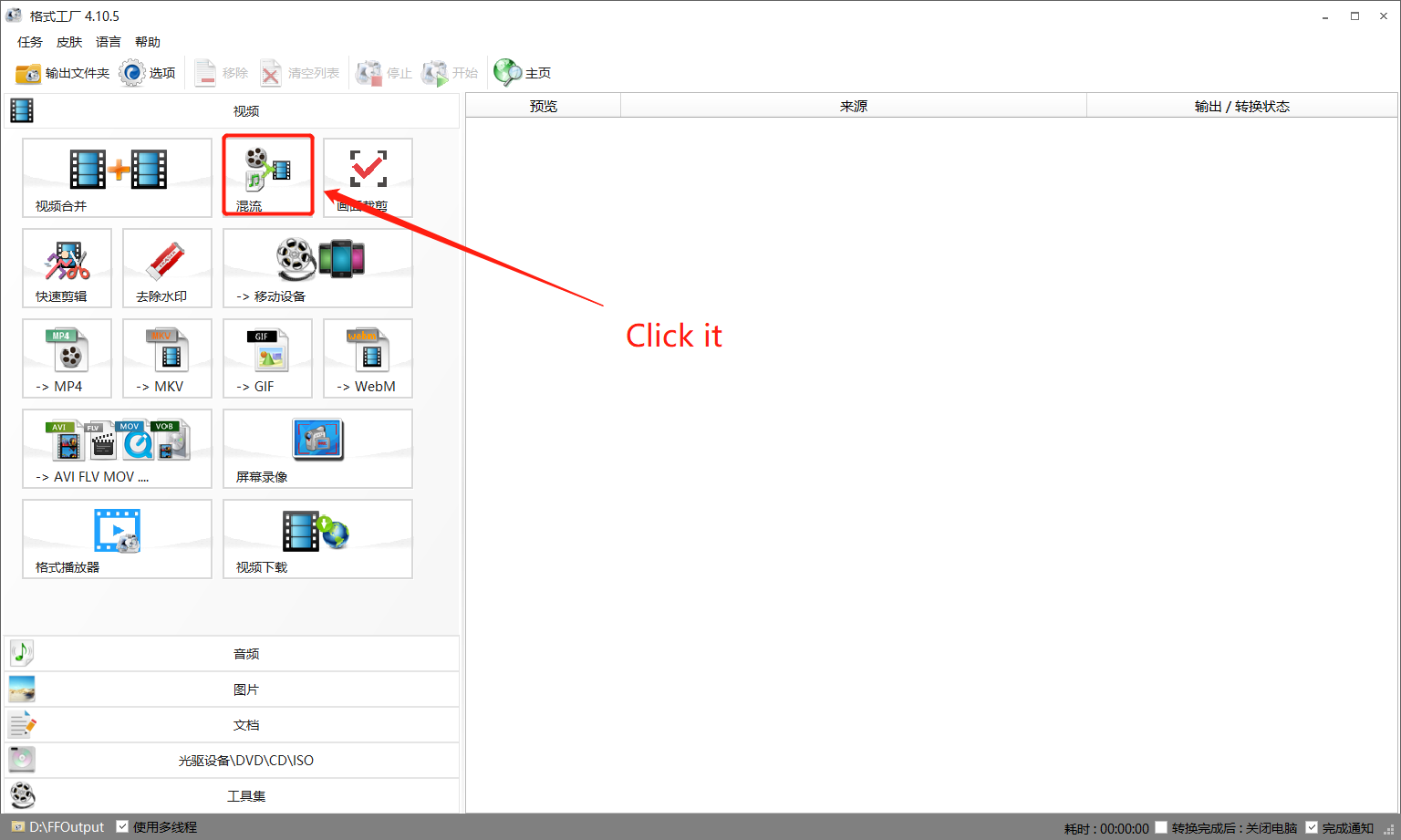
3.视音频混流: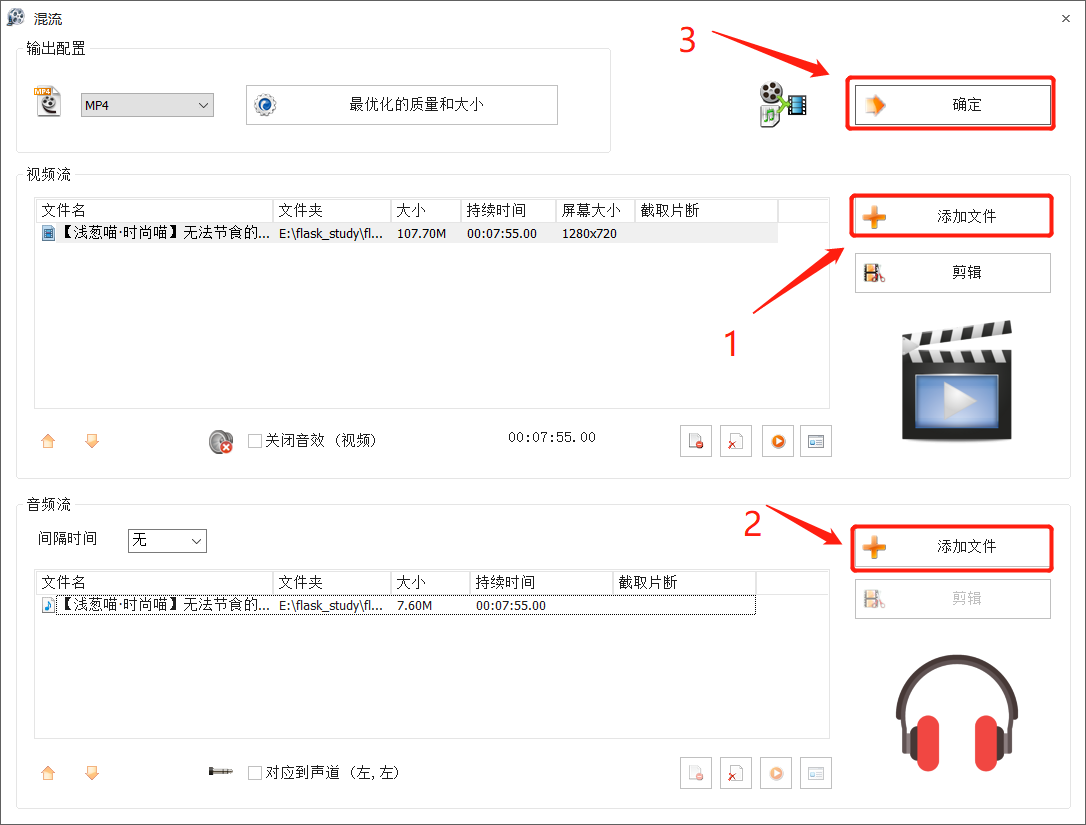
最后,静静等待混流完成即可。
以上代码,在这里下载。
代码自取: https://github.com/SunriseCai/spiderCode
小伙伴们如果感兴趣的话,可以完善代码。几个建议如下:
小伙伴们若是完善后代码记得发我一份哦!!!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
