社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
百度的deepvoice已经推出了三个版本,每一个版本都更加优化和高效。直到最近才有时间对此进行编译和测试。
DeepVoiceV1语音系统在2017年初就已出现,它运用人工智能技术,能深入学习,可以把文本文字转换为语音。这个版本能够转换简单的短句的,声音基本接近人声,不仔细听,几乎与真人说话无法区分。该系统可以一次学习一个声音,并需要数小时的数据输入来掌握每个声音。
DeepVoiceV2可以学习数百种不同的语音。从每个说话者那里吸收的数据不到半个小时,但却可以实现很高的音质。该系统可以完全凭借自己的能力找到进行训练的语音之间的共同特点,不需要接受任何事先指导。
DeepVoice3 则在半小时内就可学习2500种声音。对于之前的产品而言,要达到类似的目的,每个声音至少需要接受20小时的训练。
1、论文原理
在论文(https://arxiv.org/pdf/1710.07654.pdf)中提出了DeepVoice3的几大特性:
(1)提出了一个全卷积的特征到频谱的架构,它使我们能对一个序列的所有元素完全并行计算,并且使用了递归单元 (e.g., Wang et al., 2017) 使其训练速度比类似的架构极大地加快。
(2)支持大规模数据集训练,实验数据包含了 2484 个说话人的将近 820 个小时的录音数据。
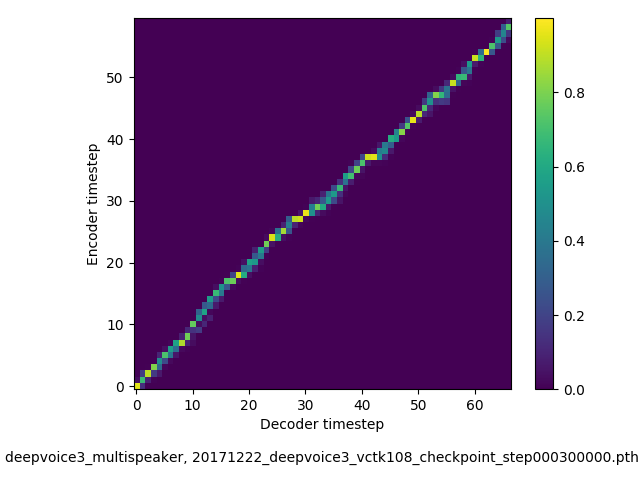
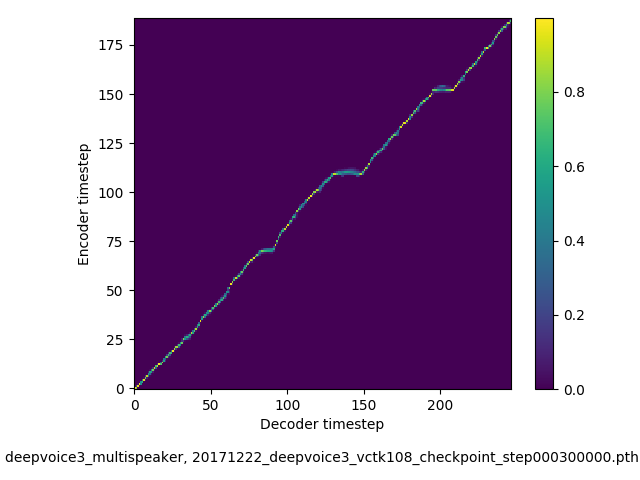
(3)实验结果证明了新方法可以生成单调注意行为(monotonic attention behavior),并避免语音合成常见的错误模式。
(4)实验比较了多个信号合成方法合成单个说话人语音的质量,其中包括了 WORLD(Morise et al., 2016)、Griffin-Lim(Griffin & Lim, 1984) 和 WaveNet(Oord et al., 2016)。
(5)速度非常快,它可以在一个单 GPU 服务器上每天完成多达 1000 万次推断。
论文的框架如下:

该框架将各种文本特征(字、音素、重音)转换为各种声学特征(mel-band 声谱、线性尺度对数幅度的声谱,或一套声码器特征比如基础频率、幅频包络和非周期性参数)。然后将这些声学特征作为声音波形合成模型的输入。从上图可以看出,即采用Seq2Seq的方式来实现TTS效果。
其中Encode阶段:一种全卷积编码器,将文本特征转换为内部学习表征。
解码阶段:一种全卷积因果解码器,将学习到的表征以一种多跳型(multi-hop)卷积注意机制解码(以一种自动回归的模式)为低维声音表征(mel-band 声谱)。
转换器:一种全卷积后处理网络,可以从解码的隐藏状态预测最后输出的特征(依赖于信号波形合成方法的类型)。和解码器不同,转换器是非因果的,因此可以依赖未来的语境信息。
2、实践测试
对源码进行重新编译,效果如下:
对新闻上的表述进行测试,逗号可以直接通过。
此外测试发现,deepvoice3速度超快,而且可以实现多个说话人的语音模仿,其多人语音模仿如下:
for speaker_id in range(N):
print(speaker_id)
tts(model, text, speaker_id=speaker_id, figures=False)National rejuvenation relies on the "hard work" of the Chinese people, and the country's innovation capacity must be raised through independent efforts, President Xi Jinping said on Tuesday.
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!