社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Beautiful Soup库是解析,遍历,维护“标签树”的功能库。
条件:
pip install lxml
pip install html5lib
以下5种基本元素是使用方法!
Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
提前要写的代码:
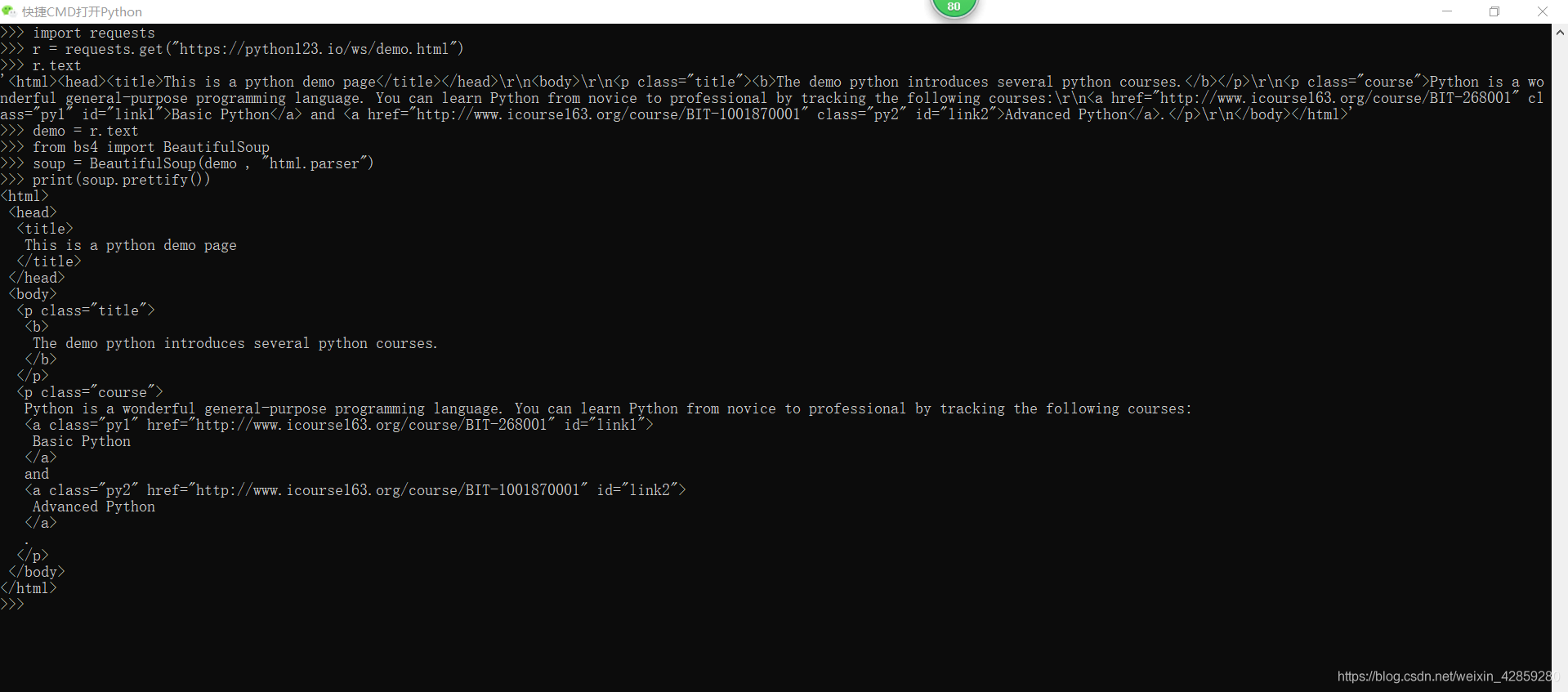
import requests
r = requests.get("https://python123.io/ws/demo.html")
r.text
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo , "html.parser")
print(soup.prettify())
执行结果:(比例不对就用放大镜查看!)
做汤:

可以查看标题!
Name:标签的名字,<p>...</p>的名字是'p',格式:<tag>.name
(比例不对就用放大镜查看!)
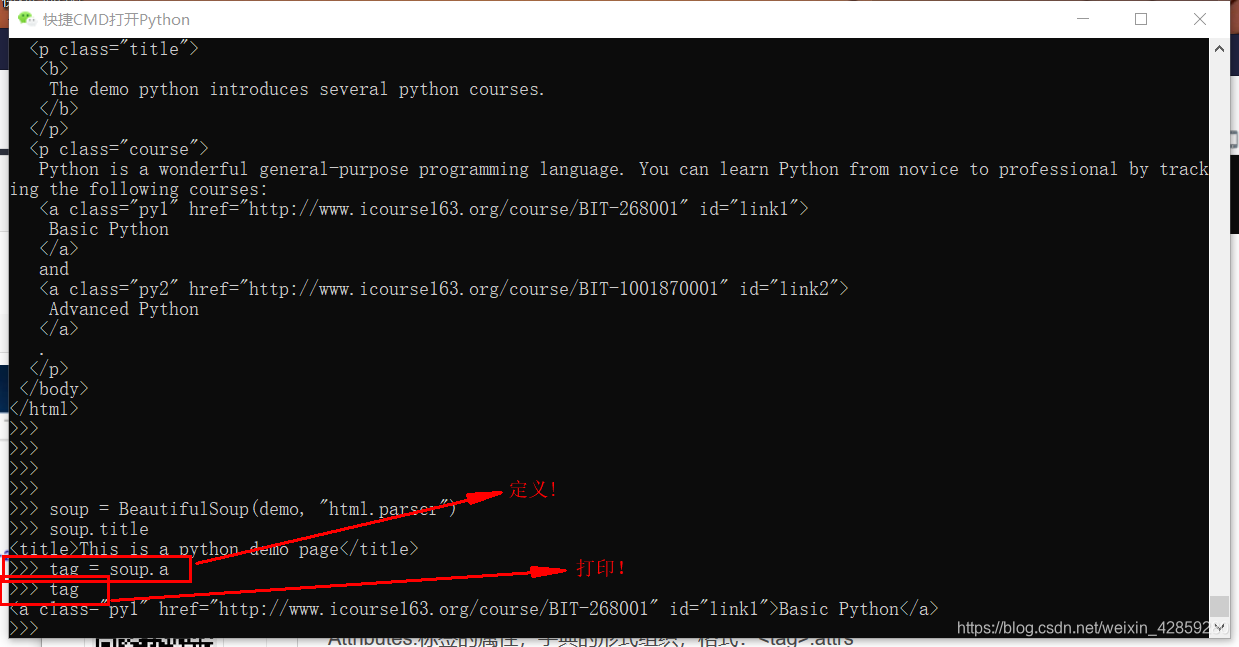
获取标签名字:
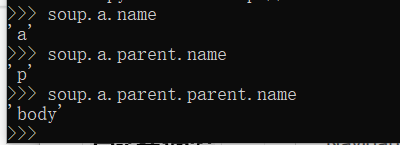
它父亲的名字,就是上一层的:

其父亲的上一层的名字:
Attributes:标签的属性,字典的形式组织,格式:<tag>.attrs
说明标签特点:

有一个字典。
上图为字典属性值。

上图为连接属性值。
标签属性类型:

为字典类型。
tag标签属性:

NavigableString:标签内非属性字符串,<>...</>中字符串,格式:<tag>.string
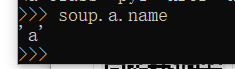
a标签的字符串信息:

p标签:

p标签的字符串信息:


Comment:标签内字符串的注释部分,一种特殊的Comment类型
处理注释部分:

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
