社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
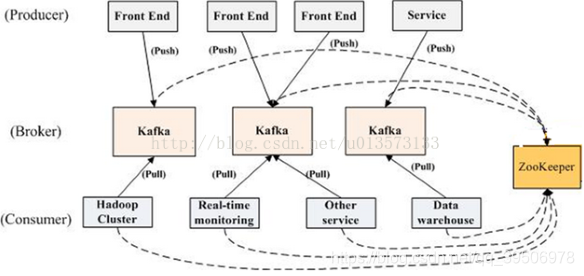
分区机制——高性能,一个topic分多个partition,发消息可以根据消息的key或轮询均匀写到不同broker的分区,消费时也可以指定要消费的partition;副本机制——高可用,partition的副本(如图虚线)跟自己一般不再同一个broker,类似ES,但是ES是副本与主分片绝不能在同一个节点,宁愿无法分配副本也不冗余。
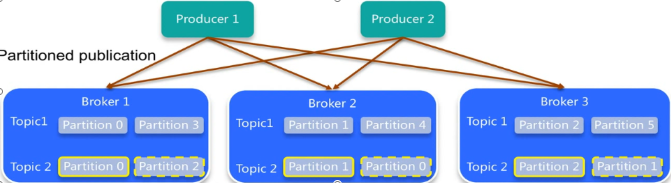
partition默认都在/tmp/kafka-logs/下面,每个partition会分为多个segment(逻辑概念),每个segment由索引文件00000000XXX.index对应的消息文件000000XXX.log。XXX为每个segment消息的offset开始值。kafka可以根据offset快速查找对应的索引再找到对应的消息文件进行消息读写。可以看到很多消费者消费消息的offset文件,在低版本。这些消费offset是写到ZK的,但ZK集群只有master节点能写,请求到fllower节点的写请求都会转发到master,这样唯一的master写压力可能会很大。高版本kafka是把这些偏移量写到kafka的一些topic如 _consumer_offset_XX.
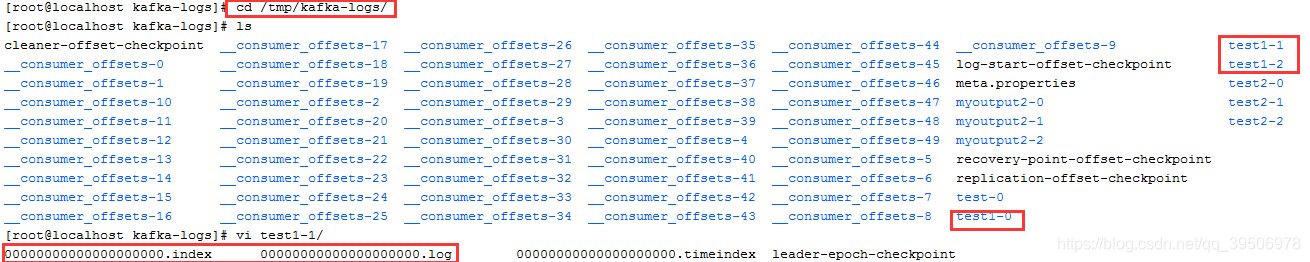
连上ZK,可以看到/consumer这个节点时空的,/brokers/topics下面有_consumer_offsets这个topic

Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加offset并且向Producer发送ACK。这样这条commit的消息就可以被消费了。
每个partition的leader维护的ISR(in-syinc replica),如果一个follower比leader落后太多或超过一定时间未发主动拉取leader数据,leader将其从ISR移除,ISR所有replica都发送完ACK后leader才commit,当有超过10000ms没有向learder拉取或与leader差了4000条数据(配置:replica.lag.time.max.ms=10000 replica.lag.max.messages=4000),或heartbeat无效都会被leader移除ISR,之后就不在等待它拉取数据的ack了。当这个follow赶上进度小鱼4000差距并10000ms有拉取数据,leader就会再次加入ISR,下次复制时就会等待期ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
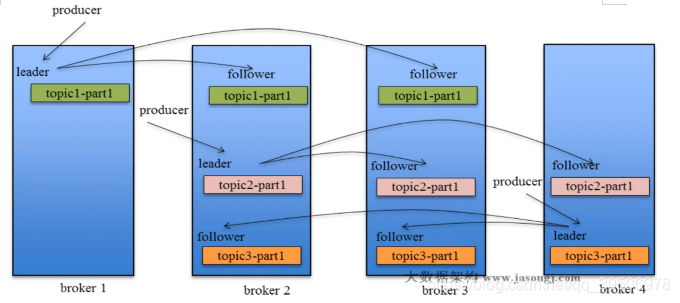
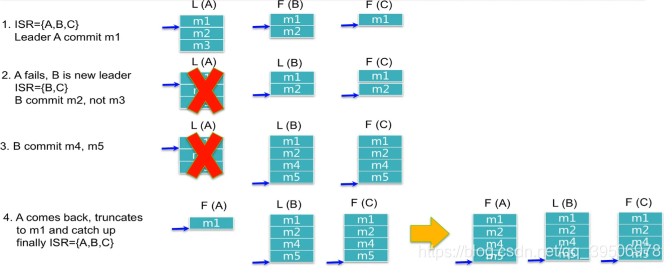
消息丢失现象:step2 Leader(A) 宕机,当其还是m4未被ISR的fowller copy。会从优先从ISR或非ISR(默认)选出一个leader,但它没有m3消息,就这样丢失了。step4 原leader活过来需要truncates掉offset后的数据并拉取新leader最新的数据与偏移量。
消费顺序问题:如produce发送的消息m3 retry第3次都才收到leader 才commit,此时在m4.m5后可能已经commit,就会发送的顺序与commit的顺序不一致,从而消费顺序不一致,即便是同一个partition。同一个partition中消费的顺序是同commit的一致的,跟发送顺序有可能不一致。不同partition如果其消费者消费得快也会超前其它partition很多。可以配置retry为0保证同一个partition的发送顺序与消费顺序一样,但丢失风险更大。
可以定义一个消费组来消费消息增强消息处理能力,消费组内的每个成员一开始消费就确定好了消费哪个partition的消息了,如果没有指定消费哪个partition,kafka会默认消费某个partition并且力求负载均衡,有消费组offline或online会进行Rebalance。kafka消费者会定期(可配置)提交其在某个partition的offset,下次消费就从这里消费,提交偏移量周期过大如重启可能导致重复消费较多已消费但offset未来得及提交的消息。Consumer或者Topic自身发生变化时,会触发Rebalance,如consumer加入或下线,topic分区变化等。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
