社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
CSDN的Python创意编程活动开始第一天就看到了,但是认为自己是菜鸟,就向当“吃瓜群众”,后来看到有好多人的代码是关于爬虫的,当初我就是由于对爬虫 感兴趣才自学的Python。现在也打算参加一下这个活动。
由于经常使用CSDN,所以收藏了好多优秀的文章,但是对于收藏夹没有整理好,要回去找之前收藏的文章不是很方便,经过研究,就用自学的简单Python爬虫帮我吧。
去到首页一看,收藏的文章是算是异步加载的吧。。但是每次都要点击“显示更多"才能看到后面的内容。
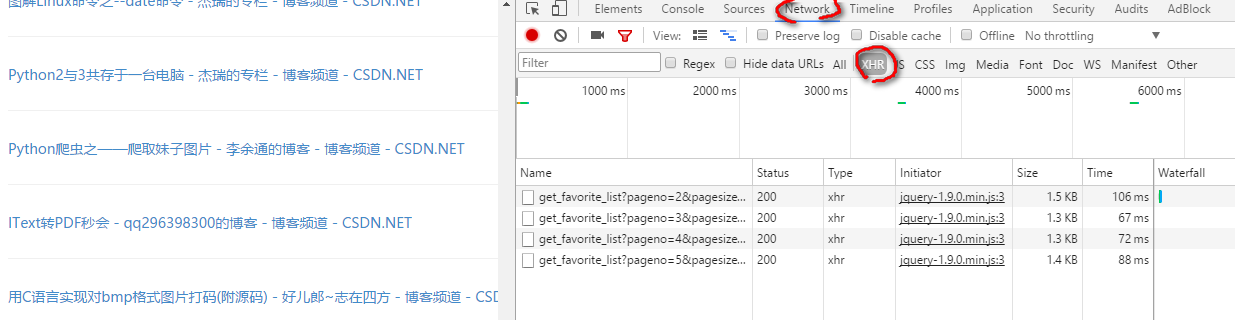
幸运的是我也知道一点异步加载的知识,就按F12进行研究:浏览后一些内容以后
双击打开Name下的链接:
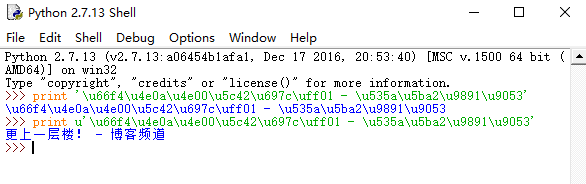
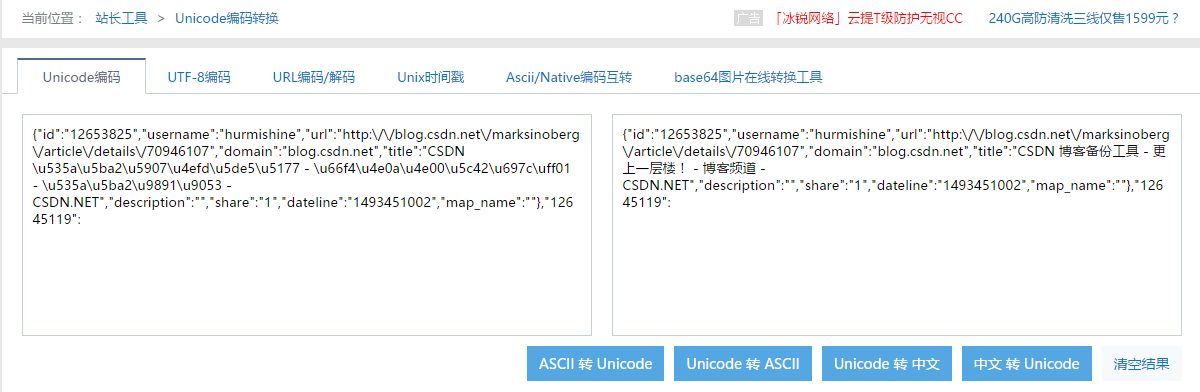
什么鬼,这是什么东西,我看不懂呀!其实这是unicode编码,要换成中文也很简单:在命令行就可以转换
当然,还有一个更好的方法,一个好用的网页: http://tool.chinaz.com/tools/unicode.aspx
可以实现在线转码的功能。把那个网页的第一条信息复制进来,点击unicode转中文,就可以看到中文了。
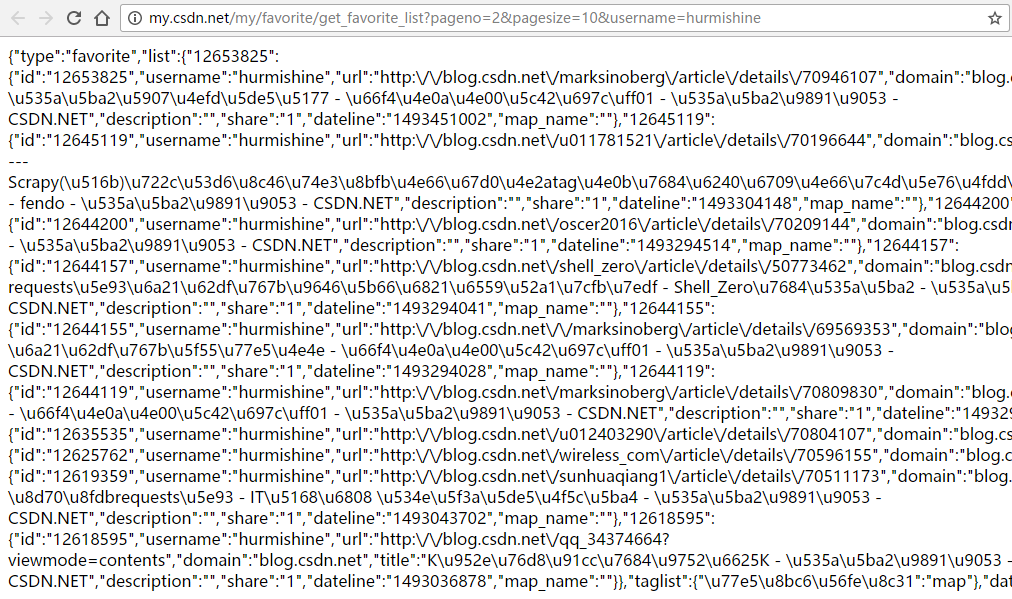
现在来研究一下那个链接,
http://my.csdn.net/my/favorite/get_favorite_list?pageno=2&pagesize=10&username=hurmishine
经过测试后发现,pageno这个参数控制显示页面起始编号,pagesize就是每页显示的数据条数。
我们可以通过改变参数来获取全部信息。
最后确定的链接为:
http://my.csdn.net/my/favorite/get_favorite_list?pageno=0&pagesize=10000&username=hurmishine
pagesize尽量设大一点,如果收藏的实际数量少于参数,将会以实际数量显示。
对于每一条数据:
{"id":"12653825","username":"hurmishine","url":"http://blog.csdn.net/marksinoberg/article/details/70946107","domain":"blog.csdn.net","title":"CSDN u535au5ba2u5907u4efdu5de5u5177 - u66f4u4e0au4e00u5c42u697cuff01 - u535au5ba2u9891u9053 - CSDN.NET","description":"","share":"1","dateline":"1493451002","map_name":""},完整代码如下,具体细节自己体会:
#coding:utf-8
import urllib,urllib2,re,cookielib
def saveByText():
f=open("html.html")#保存到本地的文件名
html = f.read();
#"url":"http://blog.csdn.net/zhangweiguo_717/article/details/52716677",
#"title":"Pythonu6a21u62dfu767bu5f55CSDN - u535au5ba2u9891u9053 - CSDN.NET",
# urls = re.findall(r'"url":"(.*?)",',html)
# links = re.findall(r'"title":"(.*?)",',html)
links = re.findall(r'"url":"(.*?)",.*?"title":"(.*?)"',html)
f2=open("index.html","w")
f2.write("<meta charset='utf-8'>rn")
index=0
for link in links :
ans=link[1].decode('unicode-escape').encode('utf-8')
# print ans
ans=ans.replace(' - 博客频道 - CSDN.NET','').replace("/",'/')
# print ans
url = link[0].replace("/",'/')
index+=1
f2.write('<font size="5">'+' '*10+str(index)+"、</font>"+"n<a href="+url+' target="_blank">'+'n')
f2.write('<font size="5">'+ans+"</font></a><br><br><br>nn")
f2.close()
if __name__ == '__main__':
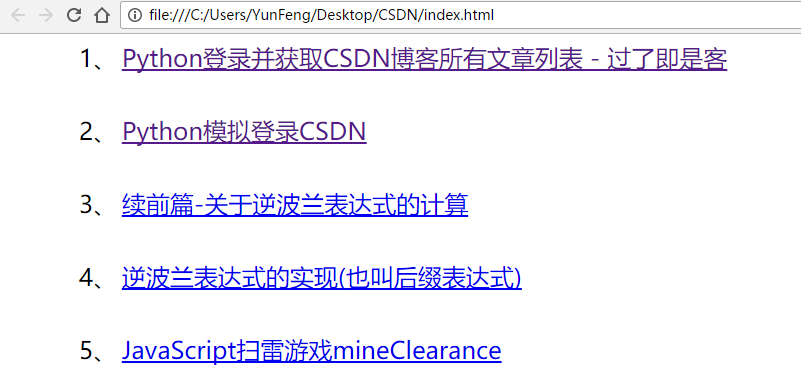
saveByText()PS:自己也没想到自己竟然收藏了那么多的文章,其间也发现,竟然有重复的收藏文章,应该是之前的Bug的吧,还有,收藏夹或许是个罪恶的根源,总以为收藏了以后去看。。。但是实际呢?
到现在可以说是基本完成了,但是每次都要复制,有点麻烦,如果可以模拟登陆,全自动那该多好呀,但是我还不会呀,但是经过不懈的努力,终于在网上找到了模拟登陆CSDN博客成功的代码,就拿来用了....
链接地址:http://blog.csdn.net/zhangweiguo_717/article/details/52716677
虽然此次活动中备份CSDN博客的那份代码也涉及到模拟登陆:http://blog.csdn.net/Marksinoberg/article/details/70946107
自动登陆获取收藏内容代码:
#coding:utf-8
import urllib,urllib2,re,cookielib
import re
import getpass #密文输入
UA='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'
headers = {'User-Agent':UA}
def login(username,password):
#建立带有cookie的opener
cookie = cookielib.CookieJar()
cookieProc = urllib2.HTTPCookieProcessor(cookie)
global opener
opener = urllib2.build_opener(cookieProc)
h = opener.open('https://passport.csdn.net').read().decode("utf8")
patten1 = re.compile(r'name="lt" value="(.*?)"')
patten2 = re.compile(r'name="execution" value="(.*?)"')
b1 = patten1.findall(h)
b2 = patten2.findall(h)
global postData
postData = {
'username': username,
'password': password,
'lt': b1[0],
'execution': b2[0],
'_eventId': 'submit',
}
postData= urllib.urlencode(postData)
opener.addheaders = [('User-Agent',UA),
('Referer', 'https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn')
]
response = opener.open('https://passport.csdn.net', data=postData)
# response2 = opener.open('http://my.csdn.net/my/fans')
# text2 = response2.read()
# print text2
def autoSave(username):
url='http://my.csdn.net/my/favorite/get_favorite_list?pageno=0&pagesize=10000&username=hurmishine'
# req = urllib2.Request(url=url.format(username),headers=headers)
# html = urllib2.urlopen(req).read()
html = opener.open(url.format(username), data=postData).read()
links = re.findall(r'"url":"(.*?)",.*?"title":"(.*?)"',html)
f2=open("index.html","w")
f2.write("<meta charset='utf-8'>rn")
index=0
flag=''
print len(links)
for link in links :
ans=link[1].decode('unicode-escape').encode('utf-8')
ans=ans.replace(' - 博客频道 - CSDN.NET','').replace("/",'/')
url = link[0].replace("/",'/')
index+=1
print ans,url
f2.write('<font size="5">'+' '*10+str(index)+"、</font>"+"n<a href="+url+' target="_blank">'+'n')
f2.write('<font size="5">'+ans+"</font></a><br><br><br>nn")
f2.close()
if __name__ == '__main__':
username=""
password=""
login(username,password)
autoSave(username)
好了,就这样吧。
自动获取收藏的那份代码,上传的47行有问题,注释部分忘了去除,上面代码已更正.
参考博客:http://blog.csdn.net/haichao062/article/details/8107316
http://blog.csdn.net/devil_2009/article/details/38796533
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!