社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
决策树是判别式模型,可以解决分类和回归问题。分类树对离散型变量做决策,回归树是对连续变量做决策;其在空间上表示,类似于在不同维度进行切分。(决策树可以为二叉树或非二叉树)
决策树构建的三个部分:特征选择,决策树生成,剪枝
ID3采用信息增益作为节点分裂选择特征的衡量标准,。
熵的概念:源于香农信息论,用于刻画信息混乱程度的一种度量。
信息熵公式:*Entropy=-p*logp
信息增益=原数据集的经验熵-去条件经验熵
python代码:
from math import log
import operator
def createDataSet():
dataSet =[[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers'] #分类的属性
return dataSet,labels
def calcShannonEnt(dataSet):
numEntries=len(dataSet)
##计算不同label的数量
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
#划分数据集,三个参数为带划分的数据集,划分数据集的特征,特征的返回值
def splitDataSet(dataSet,axis,value):
retDataSet=[]
##将特征在axis这一列的去掉
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFea=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0
beatFeature=-1
##挑选所有特征中的最佳信息增益的特征
for i in range(numFea):
fea_list=set([fea[i] for fea in dataSet])
newEntropy=0.0
for fea in fea_list:
subDataSet=splitDataSet(dataSet,i,fea)
###对应fea的不同取值占总数据量的概率
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain=baseEntropy-newEntropy
if bestInfoGain>infoGain:
bestInfoGain=infoGain
bestFea=i
return besFea
##对classList里的类别进行统计,返回统计次数最多的
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList=[example[-1] for example in dataSet]##数据的类别
if classList.count(classList[0])==len(classList):##如果只剩下一种类别,返回类别
return classList[0]
if len(dataSet[0])==1:##如果按照特征分割数据集,最后数据集只剩一个特征
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del (labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
##递归调用创建决策树函数
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
if __name__ == '__main__':
dataSet,labels=createDataSet()
print(createTree(dataSet,labels))
决策树的优缺点:决策树适用于数值型,读取数据集合,并从不断的分裂过程中学习到蕴含的规则。决策树计算复杂度不高、便于使用、而且高效,决策树可处理具有不相关特征的数据、可很容易地构造出易于理解的规则,而规则通常易于解释和理解。决策树模型也有一些缺点,比如处理缺失数据时的困难、过度拟合以及忽略数据集中属性之间的相关性等。
C4.5比起ID3改进了很多地方
def chooseBestFeatureToSplit(dataSet):
numFea=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0
beatFeature=-1
##挑选所有特征中的最佳信息增益的特征
for i in range(numFea):
fea_list=set([fea[i] for fea in dataSet])
infoGainRatio=0
newEntropy=0.0
fea_entro=0.0
for fea in fea_list:
subDataSet=splitDataSet(dataSet,i,fea)
###对应fea的不同取值占总数据量的概率
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
##计算该特征fea的熵
fea_entro-=prob*log(prob,2)
infoGain=baseEntropy-newEntropy
newInfoRatio=infoGain/fea_entro
if newInfoRatio>infoGainRatio:
newInfoRatio=infoGainRatio
bestFea=i
return bestFea
分类与回归树(classification and regression tree, CART),cart树是一个二叉树,它是在给定随机变量X条件下,输出随机变量Y的条件概率分布。
策略:回归树使用平方误差最小化,分类树用基尼指数最小化准则
回归树中最终的输出y是怎么的得到的?
在输入空间划分的区域R内,所有输入实例x对应的输出的y的均值
最小二乘回归树的构建过程:
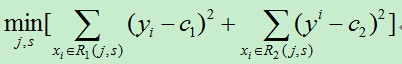

推荐刘建平的博客园,分析的很透彻:https://www.cnblogs.com/pinard/p/6053344.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
