社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
机器学习入门——决策树的实例
我们的数据集 tree(1).csv 长这样:
| RID | age | income | student | credit_rating | buy |
|---|---|---|---|---|---|
| 1 | youth | high | no | fair | no |
| 2 | youth | high | no | excellent | no |
| 3 | middle_aged | high | no | fair | yes |
| 4 | senior | medium | no | fair | yes |
| 5 | senior | low | yes | fair | yes |
| 6 | senior | low | yes | excellent | no |
| 7 | middle_aged | low | yes | excellent | yes |
| 8 | youth | medium | no | fair | no |
| 9 | youth | low | yes | fair | yes |
| 10 | senior | medium | yes | fair | yes |
| 11 | youth | medium | yes | excellent | yes |
| 12 | middle_aged | medium | no | excellent | yes |
| 13 | middle_aged | high | yes | fair | yes |
| 14 | senior | medium | no | excellent | no |
#导入必要的库
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree#加载数据文件
load_file = open(r'tree(1).csv')
reader = csv.reader(load_file) #载入数据
headers = reader.__next__() #读取第一行
print(headers)
#试着打印结果,也可以作为指标加载数据是否成功打印结果:
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']观察我们的数据,发现数据中的特征,例如:age:youth ..等,导入无法识别,因此需要对特征进行抽取,用到了DictVectorizer
DictVectorizer 使用可以参考这篇文章
说明: DictVectorizer的处理对象是符号化(非数字化)的但是具有一定结构的特征数据,如字典等,将符号转成数字0/1表示。
lables = [] #用于存储标记实例,也就是本例中的是否购入电脑
feature = [] #用于存储特征
#reader返回的值是csv文件中每行的列表,将每行读取的值作为列表返回
for row in reader:
lables.append(row[len(row)-1])
features = {}
for each in range(1,len(row)-1):
features[headers[each]] = row[each]
feature.append(features)
vec = DictVectorizer()
x = vec.fit_transform(feature).toarray()
print('特征提取后的X'+'n'+str(x))
# print(headers)
lab = preprocessing.LabelBinarizer()
y = lab.fit_transform(lables)
print('Y'+'n'+str(y))输出:
特征提取后的X
[[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
特征提取后的Y:
[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]建立决策树模型
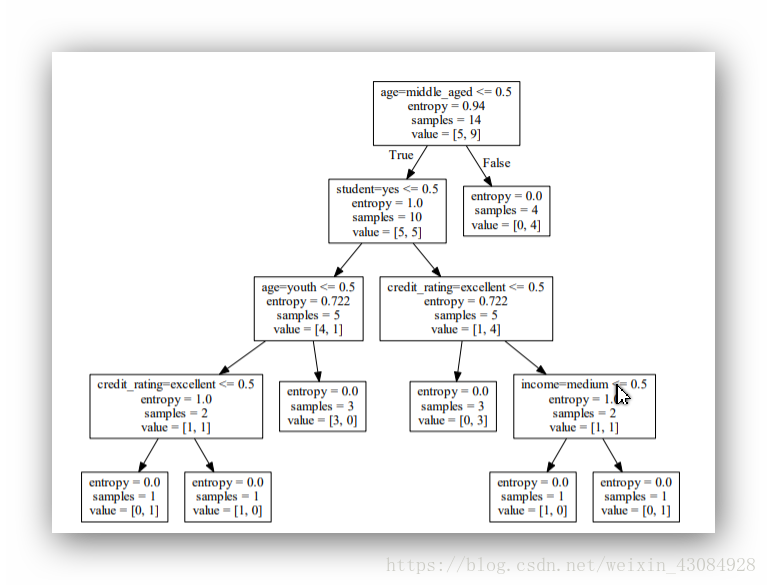
result = tree.DecisionTreeClassifier(criterion='entropy')
#使用特征选择标准为entropy,默认为基尼系数”gini”
result.fit(x,y)
# print('result'+str(result))
with open('tree1.dot','w') as f:
f = tree.export_graphviz(result,out_file=f,feature_names=vec.get_feature_names())
#保存成文件可以使用Graphviz工具可视化决策树(需要配置成环境变量才可以在控制台使用)
命令:dot -Tpdf tree1.dot -o pic.pdf
结果如下:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!