转载请注明作者和出处:http://blog.csdn.net/u013829973
系统版本:window 7 (64bit)
文章出现的所有代码在我的GitHub:https://github.com/weepon
python版本:python 3.5
一、使用决策树预测隐形眼镜类型
在上一篇文章中,我们学习了决策树算法,接下来,让我们通过一个例子讲解决策树如何预测患者需要佩戴的隐形眼镜类型。
隐形眼镜数据集是非常著名的数据集,它包含了很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)。数据来源于UCI数据库,数据存储在文本文件中,数据集下载地址:下载
数据集信息:
* 特征有四个:age(年龄)、prescript(症状)、astigmatic(是否散光)、tearRate(眼泪数量)
* 隐形眼镜类别有三类(最后一列):硬材质(hard)、软材质(soft)、不适合佩戴隐形眼镜(no lenses)

在上篇文章的代码基本上,只需要在主函数改为如下代码即可。
if __name__ == '__main__':
fr = open('lenses.txt')
lenses = [inst.strip().split('t') for inst in fr.readlines()]
print(lenses)
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
myTree_lenses = createTree(lenses, lensesLabels)
createPlot(myTree_lenses)
运行结果:
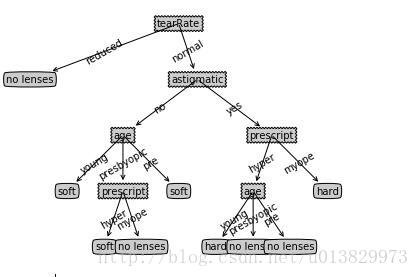
二、sklearn实战-预测隐形眼镜类型
sklearn官方文档地址
2-1 基本参数
参数说明如下:(参数说明网上有人已经翻译过了,这里就直接拿过来)
- criterion:特征选择标准,可选参数,默认是gini,可以设置为entropy。gini是基尼不纯度,是将来自集合的某种结果随机应用于某一数据项的预期误差率,是一种基于统计的思想。entropy是香农熵,也就是上篇文章讲过的内容,是一种基于信息论的思想。Sklearn把gini设为默认参数,应该也是做了相应的斟酌的,精度也许更高些?ID3算法使用的是entropy,CART算法使用的则是gini。
- splitter:特征划分点选择标准,可选参数,默认是best,可以设置为random。每个结点的选择策略。best参数是根据算法选择最佳的切分特征,例如gini、entropy。random随机的在部分划分点中找局部最优的划分点。默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random”。
- max_features:划分时考虑的最大特征数,可选参数,默认是None。寻找最佳切分时考虑的最大特征数(n_features为总共的特征数),有如下6种情况:
- 如果max_features是整型的数,则考虑max_features个特征;
- 如果max_features是浮点型的数,则考虑int(max_features * n_features)个特征;
- 如果max_features设为auto,那么max_features = sqrt(n_features);
- 如果max_features设为sqrt,那么max_featrues = sqrt(n_features),跟auto一样;
- 如果max_features设为log2,那么max_features = log2(n_features);
- 如果max_features设为None,那么max_features = n_features,也就是所有特征都用。
一般来说,如果样本特征数不多,比如小于50,我们用默认的”None”就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。
- max_depth:决策树最大深,可选参数,默认是None。这个参数是这是树的层数的。层数的概念就是,比如在贷款的例子中,决策树的层数是2层。如果这个参数设置为None,那么决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。或者如果设置了min_samples_slipt参数,那么直到少于min_smaples_split个样本为止。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
- min_samples_split:内部节点再划分所需最小样本数,可选参数,默认是2。这个值限制了子树继续划分的条件。如果min_samples_split为整数,那么在切分内部结点的时候,min_samples_split作为最小的样本数,也就是说,如果样本已经少于min_samples_split个样本,则停止继续切分。如果min_samples_split为浮点数,那么min_samples_split就是一个百分比,ceil(min_samples_split * n_samples),数是向上取整的。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
- min_weight_fraction_leaf:叶子节点最小的样本权重和,可选参数,默认是0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
- max_leaf_nodes:最大叶子节点数,可选参数,默认是None。通过限制最大叶子节点数,可以防止过拟合。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
- class_weight:类别权重,可选参数,默认是None,也可以字典、字典列表、balanced。指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。类别的权重可以通过{class_label:weight}这样的格式给出,这里可以自己指定各个样本的权重,或者用balanced,如果使用balanced,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的None。
- random_state:可选参数,默认是None。随机数种子。如果是证书,那么random_state会作为随机数生成器的随机数种子。随机数种子,如果没有设置随机数,随机出来的数与当前系统时间有关,每个时刻都是不同的。如果设置了随机数种子,那么相同随机数种子,不同时刻产生的随机数也是相同的。如果是RandomState instance,那么random_state是随机数生成器。如果为None,则随机数生成器使用np.random。
- min_impurity_split:节点划分最小不纯度,可选参数,默认是1e-7。这是个阈值,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。
- presort:数据是否预排序,可选参数,默认为False,这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。
除了这些参数要注意以外,其他在调参时的注意点有:
- 当样本数量少但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
- 如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
- 推荐多用决策树的可视化,同时先限制决策树的深度,这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
- 在训练模型时,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
- 决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
- 如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
2-2 加载数据
pandas是一个非常强大的库,用它处理CSV、txt数据文件很方便。接下来我们使用pandas加载隐形眼镜文件,代码如下:
import pandas as pd
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate','class']
feature = ['age', 'prescript', 'astigmatic', 'tearRate']
lenses = pd.read_table('lenses.txt',names=lensesLabels, sep='t')
查看lenses变量:
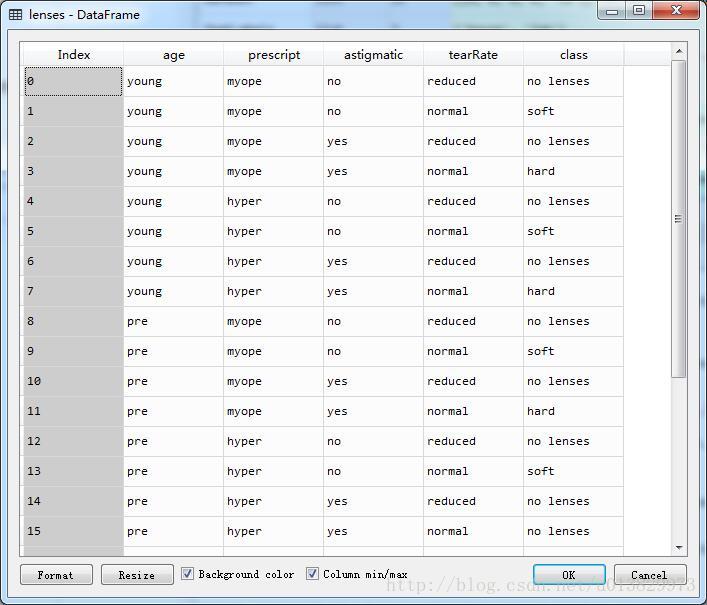
2-3 数据处理
了解了上面的参数可以知道,sklearn函数fit时需要数据X(也即是特征数据)满足numpy的float32类型。但是隐形眼镜的特征数据是各种英文单词,是字符串。格式不对,所以,在使用fit()函数之前,我们需要对数据集进行编码,这里可以使用两种方法:
使用LabelEncoder编码结果:
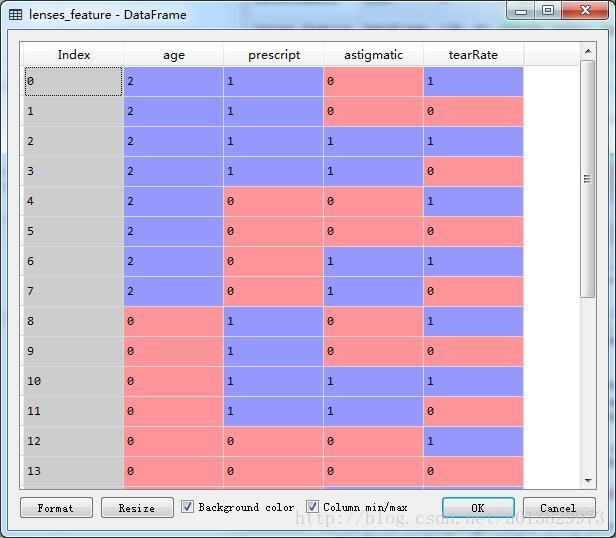
2-3 建立决策树
代码如下:
'''
Created on Nov 10, 2017
Decision Tree Source Code for Machine Learning in Action Ch. 3
author: weepon
blog: http://blog.csdn.net/u013829973
Modify:
2017-11-10
'''
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
import pandas as pd
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate','class']
feature = ['age', 'prescript', 'astigmatic', 'tearRate']
lenses = pd.read_table('lenses.txt',names=lensesLabels, sep='t')
lenses_feature = lenses[feature]
le = LabelEncoder()
for col in lenses_feature.columns:
lenses_feature[col] = le.fit_transform(lenses_feature[col])
clf = tree.DecisionTreeClassifier(max_depth = 4)
model = clf.fit(lenses_feature.values, lenses['class'])
print(model)
pre = model.predict([[0,1,0,1]])
print('预测结果为',pre)
运行结果:

PS: 如果觉得本篇本章对您有所帮助,欢迎关注、评论、顶!
本文出现的所有代码和数据集,均可在我的github上下载,欢迎Follow、Star:
我的GitHub:https://github.com/weepon
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u013829973/article/details/78509019
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

