社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在日常生活中我们常常会用到PDF格式的文档,这种格式虽然阅读方便,但我们通常无法修改PDF里面的内容,如果想要修改的需要把PDF转成Word形式。除此之外,PDF字间距较大,如果完整打印下来会花费不少钱,也需要转成Word的形式调整字间距及字体的大小来减少打印成本。
想要满足这样的需求我们通常会去使用一些软件,比如我们最常用的WPS办公程序。但是像WPS这样的办公程序PDF转Word也是需要收费的,价格也不低,如果要转换几十个甚至上百个PDF文档那要多久啊!(手估计都累残了!)。总而言之,当然没有我写的Jacob_PWD好了!(哈哈小编说了这么多心机已经完全暴露出来了~~)接下来我就给大家介绍一下我的这款程序。(下面有彩蛋哦!)
小编调用了glob模块加上.pdf后缀名实现了文件的自动搜寻并记录文件个数,通过for循环逐个处理待转换的PDF文件实现了批量转换的功能,这样上百个PDF文件通过一个回车键轻松解决,剩下的就是坐等电脑完工!(机智如我!!哈哈~)。话不多说,上图!上图!上图!
- 程序运行图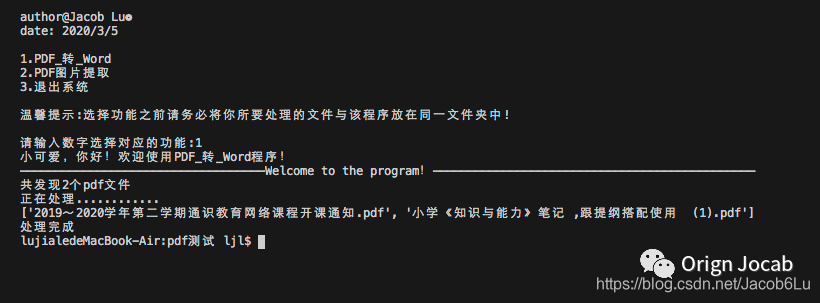
- 转换效果展示

从上图我们看到转换的效果还是不错的,转换一些纯文本的PDF绝对是够用了,但细心的小编发现一个问题——功能1无法完成图片的转换。因此,小编又通过搜寻,参考了一些前辈的代码,解决了这样的一个问题。通过测试,小编不禁倒吸一口凉气,感叹电脑运算速度之快,提取6张图片不到0.05S!上图!上图!上图!
- 程序运行图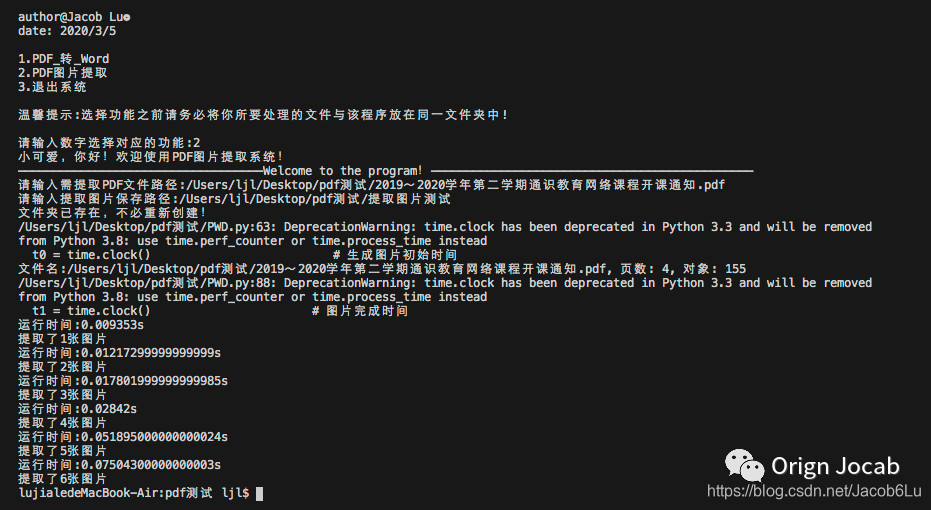
- 提取效果展示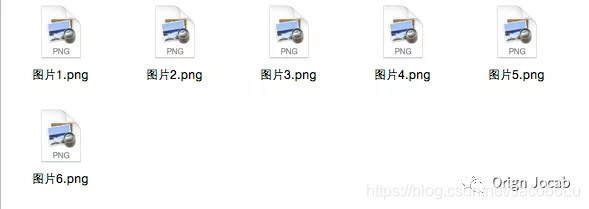
print("""
author@Jacob Lu❁
date: 2020/3/5
""")
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
from docx import Document
import warnings
import os
import time
import glob
import fitz
import re
J=True
while J:
print('1.PDF_转_Wordn2.PDF图片提取n3.退出系统n')
print("""温馨提示:选择功能之前请务必将你所要处理的文件与该程序放在同一文件夹中!n""")
choice = int(input('请输入数字选择对应的功能:'))
if choice==1:
print('小可爱,你好!欢迎使用PDF_转_Word程序!')
time.sleep(1.5)
print('———————————————————————————————————Welcome to the program!——————————————————————————————————————————————' )
time.sleep(1.5)
pdf_list = glob.glob('*.pdf') #查看同文件夹下的csv文件数
print(u'共发现%s个pdf文件'% len(pdf_list))
print(u'正在处理............')
print(pdf_list)
for l in iter(pdf_list):
file_name = os.open(l, os.O_RDWR)
document = Document()
warnings.filterwarnings("ignore")
def pdf2word():
fn = open(file_name, 'rb')
parser = PDFParser(fn)
doc = PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
resource = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(resource, laparams=laparams)
interpreter = PDFPageInterpreter(resource, device)
for i in doc.get_pages():
interpreter.process_page(i)
layout = device.get_result()
for out in layout:
if hasattr(out, "get_text"):
content = out.get_text().replace(u'xa0', u' ')
document.add_paragraph(
content, style='ListBullet'
)
document.save(l+ '.docx')
pdf2word()
print('处理完成')
break
elif choice==2:
print('小可爱,你好!欢迎使用PDF图片提取系统!')
time.sleep(1.5)
print('———————————————————————————————————Welcome to the program!——————————————————————————————————————————————' )
time.sleep(1.5)
def pdf2pic(path, pic_path):
t0 = time.clock() # 生成图片初始时间
checkXO = r"/Type(?= */XObject)" # 使用正则表达式来查找图片
checkIM = r"/Subtype(?= */Image)"
doc = fitz.open(path) # 打开pdf文件
imgcount = 0 # 图片计数
lenXREF = doc._getXrefLength() # 获取对象数量长度
# 打印PDF的信息
print("文件名:{}, 页数: {}, 对象: {}".format(path, len(doc), lenXREF - 1))
# 遍历每一个对象
for i in range(1, lenXREF):
text = doc._getXrefString(i) # 定义对象字符串
isXObject = re.search(checkXO, text) # 使用正则表达式查看是否是对象
isImage = re.search(checkIM, text) # 使用正则表达式查看是否是图片
if not isXObject or not isImage: # 如果不是对象也不是图片,则continue
continue
imgcount += 1
pix = fitz.Pixmap(doc, i) # 生成图像对象
new_name = "图片{}.png".format(imgcount) # 生成图片的名称
if pix.n < 5: # 如果pix.n<5,可以直接存为PNG
pix.writePNG(os.path.join(pic_path, new_name))
else: # 否则先转换CMYK
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, new_name))
pix0 = None
pix = None # 释放资源
t1 = time.clock() # 图片完成时间
print("运行时间:{}s".format(t1 - t0))
print("提取了{}张图片".format(imgcount))
if __name__=='__main__':
path =input('请输入需提取PDF文件路径:')
pic_path =input('请输入提取图片保存路径:')
# 创建保存图片的文件夹
if os.path.exists(pic_path):
print("文件夹已存在,不必重新创建!")
pass
else:
os.mkdir(pic_path)
pdf2pic(path, pic_path)
break
elif choice==3:
print('拜拜~欢迎下次光临!')
break
else:
print('小伙子小姐姐不要开车哦!我可不是傻子,请按照正确的流程输入!')
print('——————————————————————❁—————————————————————————❁———————————————————————————❁——————————————————————————' )
time.sleep(1.5)
continue
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
