社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
【转载请标明出处】https://blog.csdn.net/qq_25870633/article/details/83388952
接上篇文章 【我的区块链之路】- golang源码分析之select的底层实现 我这里因为面试的时候也有被问到过 channel的底层实现,所以就一并的去把 channel 啊,goroutine啊,go协程的调度器啊,interface啊,mutex啊,rwmutex啊,timer啊等等底层全部都去录了一遍。没办法啊,曾经我以为自己是个逆风尿三丈的耀眼王者,然而这段时间发现自己只是一只顺风尿湿鞋的不屈黑铁。。。
参考:
https://blog.csdn.net/nobugtodebug/article/details/45396507
https://studygolang.com/articles/10575?fr=sidebar
那么,我们这篇文章主要是讲channel的底层实现的。
首先,我们先看channel的实现是在哪里?在runtime包下面咯,路径为:./src/runtime/chan.go 文件中,其中主要的结构体为:
/**
定义了 channel 的结构体
*/
type hchan struct {
qcount uint // total data in the queue 队列中的当前数据的个数
dataqsiz uint // size of the circular queue channel的大小
buf unsafe.Pointer // points to an array of dataqsiz elements 数据缓冲区,存放数据的环形数组
elemsize uint16 // channel 中数据类型的大小 (单个元素的大小)
closed uint32 // 表示 channel 是否关闭的标识位
elemtype *_type // element type 队列中的元素类型
// send 和 recieve 的索引,用于实现环形数组队列
sendx uint // send index 当前发送元素的索引
recvx uint // receive index 当前接收元素的索引
recvq waitq // list of recv waiters 接收等待队列;由 recv 行为(也就是 <-ch)阻塞在 channel 上的 goroutine 队列
sendq waitq // list of send waiters 发送等待队列;由 send 行为 (也就是 ch<-) 阻塞在 channel 上的 goroutine 队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
// lock保护hchan中的所有字段,以及此通道上阻塞的sudoG中的几个字段。
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
// 保持此锁定时不要更改另一个G的状态(特别是,没有准备好G),因为这可能会因堆栈收缩而死锁。
lock mutex
}
/**
发送及接收队列的结构体
等待队列的链表实现
*/
type waitq struct {
first *sudog
last *sudog
}
然后还有在 runtime包的 ./src/runtime/runtime2.go 中定义的 sudoG对应的结构体:
/**
对 G 的封装
*/
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
selectdone *uint32 // CAS to 1 to win select race (may point to stack)
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
和select类似,hchan其实只是channel的头部。头部后面的一段内存连续的数组将作为channel的缓冲区,即用于存放channel数据的环形队列。qcount 和 dataqsiz 分别描述了缓冲区当前使用量【len】和容量【cap】。若channel是无缓冲的,则size是0,就没有这个环形队列了。如图:

下面我们来看看实例化一个channel的实现:
make 的过程还比较简单,需要注意一点的是当元素不含指针的时候,会将整个 hchan 分配成一个连续的空间。下面就是make创建channel的代码实现:
//go:linkname reflect_makechan reflect.makechan
func reflect_makechan(t *chantype, size int64) *hchan {
return makechan(t, size)
}
/**
创建 chan
*/
func makechan(t *chantype, size int64) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
if size < 0 || int64(uintptr(size)) != size || (elem.size > 0 && uintptr(size) > (_MaxMem-hchanSize)/elem.size) {
panic(plainError("makechan: size out of range"))
}
var c *hchan
if elem.kind&kindNoPointers != 0 || size == 0 {
// Allocate memory in one call.
// Hchan does not contain pointers interesting for GC in this case:
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
c = (*hchan)(mallocgc(hchanSize+uintptr(size)*elem.size, nil, true))
if size > 0 && elem.size != 0 {
c.buf = add(unsafe.Pointer(c), hchanSize)
} else {
// race detector uses this location for synchronization
// Also prevents us from pointing beyond the allocation (see issue 9401).
c.buf = unsafe.Pointer(c)
}
} else {
c = new(hchan)
c.buf = newarray(elem, int(size))
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; elemalg=", elem.alg, "; dataqsiz=", size, "n")
}
return c
}
可以看出来和之前说的select一样用了 //go:linkname 技巧,把函数关联到了 reflect包中的对应函数上了,这样纸就使用反射区出发整个make的入口。骚微过一下reflect包中真正make(chan type, int) 的函数吧
// MakeChan creates a new channel with the specified type and buffer size.
func MakeChan(typ Type, buffer int) Value {
if typ.Kind() != Chan {
panic("reflect.MakeChan of non-chan type")
}
if buffer < 0 {
panic("reflect.MakeChan: negative buffer size")
}
if typ.ChanDir() != BothDir {
panic("reflect.MakeChan: unidirectional channel type")
}
ch := makechan(typ.(*rtype), uint64(buffer))
return Value{typ.common(), ch, flag(Chan)}
}
// 这个才是被runtime中 用 //go:linkname 链接的函数
func makechan(typ *rtype, size uint64) (ch unsafe.Pointer)
劫争上面继续说,make中做了什么:首先两个 if 主要是一些异常情况的判断,第三个 if 也很明显,判断 size 大小是否小于 0 或者过大。int64(uintptr(size)) != size 这句也是判断 size 是否为负。
然后接着判断,如果channel中元素类型不为指针或者channel为无缓冲通道那么就将其分配在连续的内存区域。【使用 mallocgc 函数进行分配内存空间】顺便看下 mallocgc 函数(这个函数在select那章其实也用到的)的代码吧:
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
/**
分配大小为字节的对象。
从每个P缓存的空闲列表中分配小对象。
大型对象(> 32 kB)直接从堆中分配。
*/
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
align = uintptr(typ.align)
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.kind&kindNoPointers != 0
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if size < uintptr(rate) && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(gcBackgroundMode, t)
}
}
return x
}
否则,在创建chan需要知道数据类型和缓冲区大小。channel 和 channel.buf 是分别进行分配的。对应上面的结构图 newarray 将生成这个环形队列。之所以要分开指针类型缓冲区主要是为了区分gc操作,需要将它设置为flagNoScan。并且指针大小固定,可以跟hchan头部一起分配内存,不需要先new(hchan)再newarry。
我们再看下 newarray函数:
func newarray(typ *_type, n int) unsafe.Pointer {
if n < 0 || uintptr(n) > maxSliceCap(typ.size) {
panic(plainError("runtime: allocation size out of range"))
}
return mallocgc(typ.size*uintptr(n), typ, true)
}
可以看出来,其实newarray函数底层也是调了 mallocgc 函数来分配内存空间的。
声明但不make初始化的chan是nil chan。读写nil chan会阻塞,关闭nil chan会panic。
从实现中可见读写chan都要lock,这跟读写共享内存一样都有lock的开销。
数据在chan中的传递方向从chansend开始从入参最终写入recvq中的goroutine的数据域,这中间如果发生阻塞可能先写入sendq中goroutine的数据域等待中转。
从gopark返回后sudog对象可重用。
首先,我们来看下对应chan的读写函数的定义:
// entry point for c <- x from compiled code
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc(unsafe.Pointer(&c)))
}
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
* 通用单通道发送/接收
* 如果阻塞不是nil,则将不会休眠,但如果无法完成则返回。
* 当睡眠中涉及的通道关闭时,睡眠可以通过g.param == nil唤醒。 最简单的循环和重新运行操作; 我们会
* 看到它现在已经关闭了。
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 当 channel 未初始化或为 nil 时,向其中发送数据将会永久阻塞
if c == nil {
if !block {
return false
}
// gopark 会使当前 goroutine 休眠,并通过 unlockf 唤醒,但是此时传入的 unlockf 为 nil, 因此,goroutine 会一直休眠
gopark(nil, nil, "chan send (nil chan)", traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "n")
}
if raceenabled {
racereadpc(unsafe.Pointer(c), callerpc, funcPC(chansend))
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
//
// After observing that the channel is not closed, we observe that the channel is
// not ready for sending. Each of these observations is a single word-sized read
// (first c.closed and second c.recvq.first or c.qcount depending on kind of channel).
// Because a closed channel cannot transition from 'ready for sending' to
// 'not ready for sending', even if the channel is closed between the two observations,
// they imply a moment between the two when the channel was both not yet closed
// and not ready for sending. We behave as if we observed the channel at that moment,
// and report that the send cannot proceed.
//
// It is okay if the reads are reordered here: if we observe that the channel is not
// ready for sending and then observe that it is not closed, that implies that the
// channel wasn't closed during the first observation.
if !block && c.closed == 0 && ((c.dataqsiz == 0 && c.recvq.first == nil) ||
(c.dataqsiz > 0 && c.qcount == c.dataqsiz)) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 获取同步锁
lock(&c.lock)
// 向已经关闭的 channel 发送消息会产生 panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// CASE1: 当有 goroutine 在 recv 队列上等待时,跳过缓存队列,将消息直接发给 reciever goroutine
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
// 找到了等待receiver。 我们将要发送的值直接传递给receiver,绕过通道缓冲区(如果有的话)。
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// CASE2: 缓存队列未满,则将消息复制到缓存队列上
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
// CASE3: 缓存队列已满,将goroutine 加入 send 队列
// 初始化 sudog
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 加入队列
c.sendq.enqueue(mysg)
// 休眠
goparkunlock(&c.lock, "chan send", traceEvGoBlockSend, 3)
// 唤醒 goroutine
// someone woke us up.
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
return true
}
// send processes a send operation on an empty channel c.
// The value ep sent by the sender is copied to the receiver sg.
// The receiver is then woken up to go on its merry way.
// Channel c must be empty and locked. send unlocks c with unlockf.
// sg must already be dequeued from c.
// ep must be non-nil and point to the heap or the caller's stack.
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if raceenabled {
if c.dataqsiz == 0 {
racesync(c, sg)
} else {
// Pretend we go through the buffer, even though
// we copy directly. Note that we need to increment
// the head/tail locations only when raceenabled.
qp := chanbuf(c, c.recvx)
raceacquire(qp)
racerelease(qp)
raceacquireg(sg.g, qp)
racereleaseg(sg.g, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
}
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
send 有以下四种情况:【都是对不为nil的chan的情况】
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 看send 部分逻辑
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if raceenabled {
if c.dataqsiz == 0 {
racesync(c, sg)
} else {
// Pretend we go through the buffer, even though
// we copy directly. Note that we need to increment
// the head/tail locations only when raceenabled.
qp := chanbuf(c, c.recvx)
raceacquire(qp)
racerelease(qp)
raceacquireg(sg.g, qp)
racereleaseg(sg.g, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
}
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
// 一些初始化工作
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg) // 当前 goroutine 如等待队列
goparkunlock(&c.lock, "chan send", traceEvGoBlockSend, 3) //休眠
// entry points for <- c from compiled code
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: don't need to check ep, as it is always on the stack
// or is new memory allocated by reflect.
if debugChan {
print("chanrecv: chan=", c, "n")
}
// 从 nil 的 channel 中接收消息,永久阻塞
if c == nil {
if !block {
return
}
gopark(nil, nil, "chan receive (nil chan)", traceEvGoStop, 2)
throw("unreachable")
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
//
// After observing that the channel is not ready for receiving, we observe that the
// channel is not closed. Each of these observations is a single word-sized read
// (first c.sendq.first or c.qcount, and second c.closed).
// Because a channel cannot be reopened, the later observation of the channel
// being not closed implies that it was also not closed at the moment of the
// first observation. We behave as if we observed the channel at that moment
// and report that the receive cannot proceed.
//
// The order of operations is important here: reversing the operations can lead to
// incorrect behavior when racing with a close.
if !block && (c.dataqsiz == 0 && c.sendq.first == nil ||
c.dataqsiz > 0 && atomic.Loaduint(&c.qcount) == 0) &&
atomic.Load(&c.closed) == 0 {
return
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// CASE1: 从已经 close 且为空的 channel recv 数据,返回空值
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(unsafe.Pointer(c))
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// CASE2: send 队列不为空
// CASE2.a: 缓存队列为空,直接从 sender recv 元素
// CASE2.b: 缓存队列不为空,此时只有可能是缓存队列已满,从队列头取出元素,
//并唤醒 sender 将元素写入缓存队列尾部。由于为环形队列,因此,队列满时只需要将队列头复制给 reciever,
//同时将 sender 元素复制到该位置,并移动队列头尾索引,不需要移动队列元素
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// CASE3: 缓存队列不为空,直接从队列取元素,移动头索引
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// CASE4: 缓存队列为空,将 goroutine 加入 recv 队列,并阻塞
// no sender available: block on this channel.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, "chan receive", traceEvGoBlockRecv, 3)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, !closed
}
// recv processes a receive operation on a full channel c.
// There are 2 parts:
// 1) The value sent by the sender sg is put into the channel
// and the sender is woken up to go on its merry way.
// 2) The value received by the receiver (the current G) is
// written to ep.
// For synchronous channels, both values are the same.
// For asynchronous channels, the receiver gets its data from
// the channel buffer and the sender's data is put in the
// channel buffer.
// Channel c must be full and locked. recv unlocks c with unlockf.
// sg must already be dequeued from c.
// A non-nil ep must point to the heap or the caller's stack.
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
// Queue is full. Take the item at the
// head of the queue. Make the sender enqueue
// its item at the tail of the queue. Since the
// queue is full, those are both the same slot.
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
raceacquireg(sg.g, qp)
racereleaseg(sg.g, qp)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
receive 有以下四种情况:【都是对不为nil的chan的情况】
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(unsafe.Pointer(c))
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
// Queue is full. Take the item at the
// head of the queue. Make the sender enqueue
// its item at the tail of the queue. Since the
// queue is full, those are both the same slot.
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
raceacquireg(sg.g, qp)
racereleaseg(sg.g, qp)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
// no sender available: block on this channel.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, "chan receive", traceEvGoBlockRecv, 3)
下面,我们来看看关闭通道具体的实现:
//go:linkname reflect_chanclose reflect.chanclose
func reflect_chanclose(c *hchan) {
closechan(c)
}
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
// 重复 close,产生 panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&c))
racewritepc(unsafe.Pointer(c), callerpc, funcPC(closechan))
racerelease(unsafe.Pointer(c))
}
c.closed = 1
var glist *g
// 唤醒所有 reciever
// release all readers
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, unsafe.Pointer(c))
}
gp.schedlink.set(glist)
glist = gp
}
// 唤醒所有 sender,并产生 panic
// release all writers (they will panic)
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, unsafe.Pointer(c))
}
gp.schedlink.set(glist)
glist = gp
}
unlock(&c.lock)
// 唤醒所哟叜glist中的goroutine
// Ready all Gs now that we've dropped the channel lock.
for glist != nil {
gp := glist
glist = glist.schedlink.ptr()
gp.schedlink = 0
goready(gp, 3)
}
}
close channel 的工作
处理方式是分别遍历 recvq 和 sendq 队列,将所有的 goroutine 放到 glist 队列中,最后唤醒 glist 队列中的 goroutine。
OK上述就是channel的源码分析,我们下面通过几张图来看一下chan的工作原理:
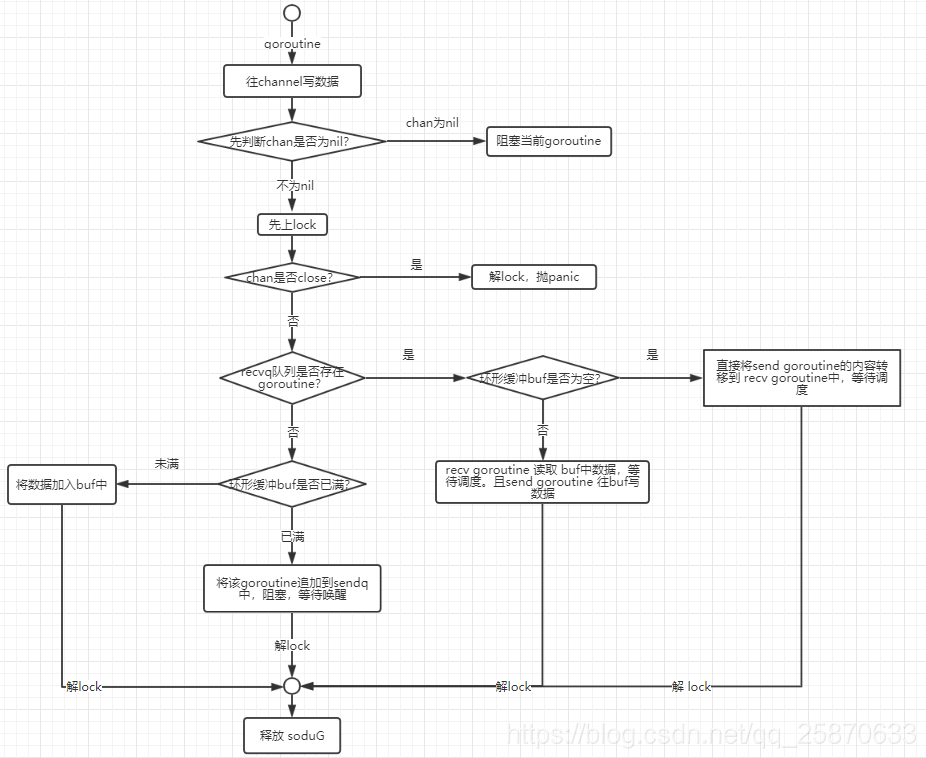
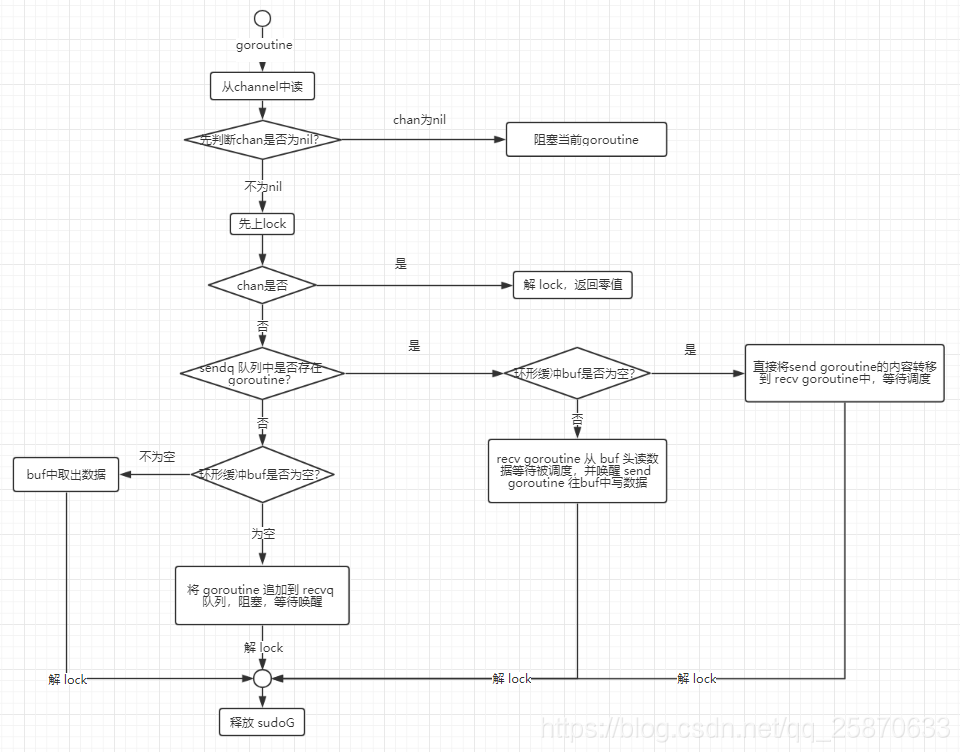
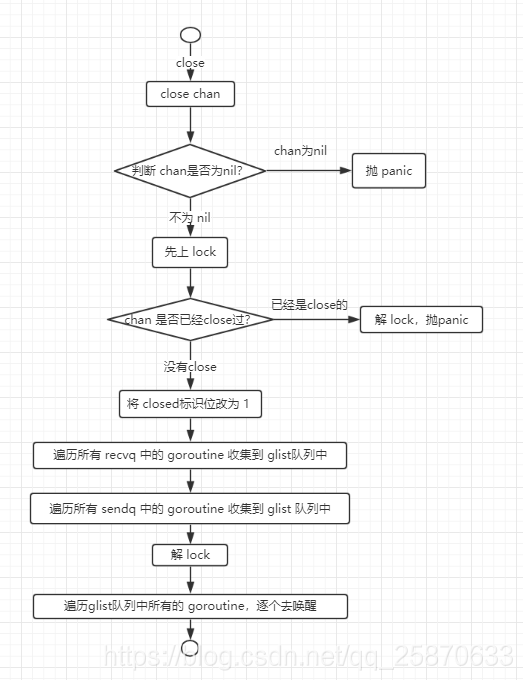
以上就是对 chan的底层操作原理及讲解。
问chan是否线程安全的呢?是线程安全的,因为其hchan结构汇总内置了mutex,且send 及 recv 及close 的操作中均会去 加锁/解锁 等动作。
到这里我们对chan的底层讲解就结束了!大家手下留情了~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
