社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
实时计算 Flink新增自动调优功能autoconf。能够在流作业以及上下游性能达到稳定的前提下,根据您作业的历史运行状况,重新分配各算子资源和并发数,达到优化作业的目的。更多详细说明请您参阅自动配置调优。
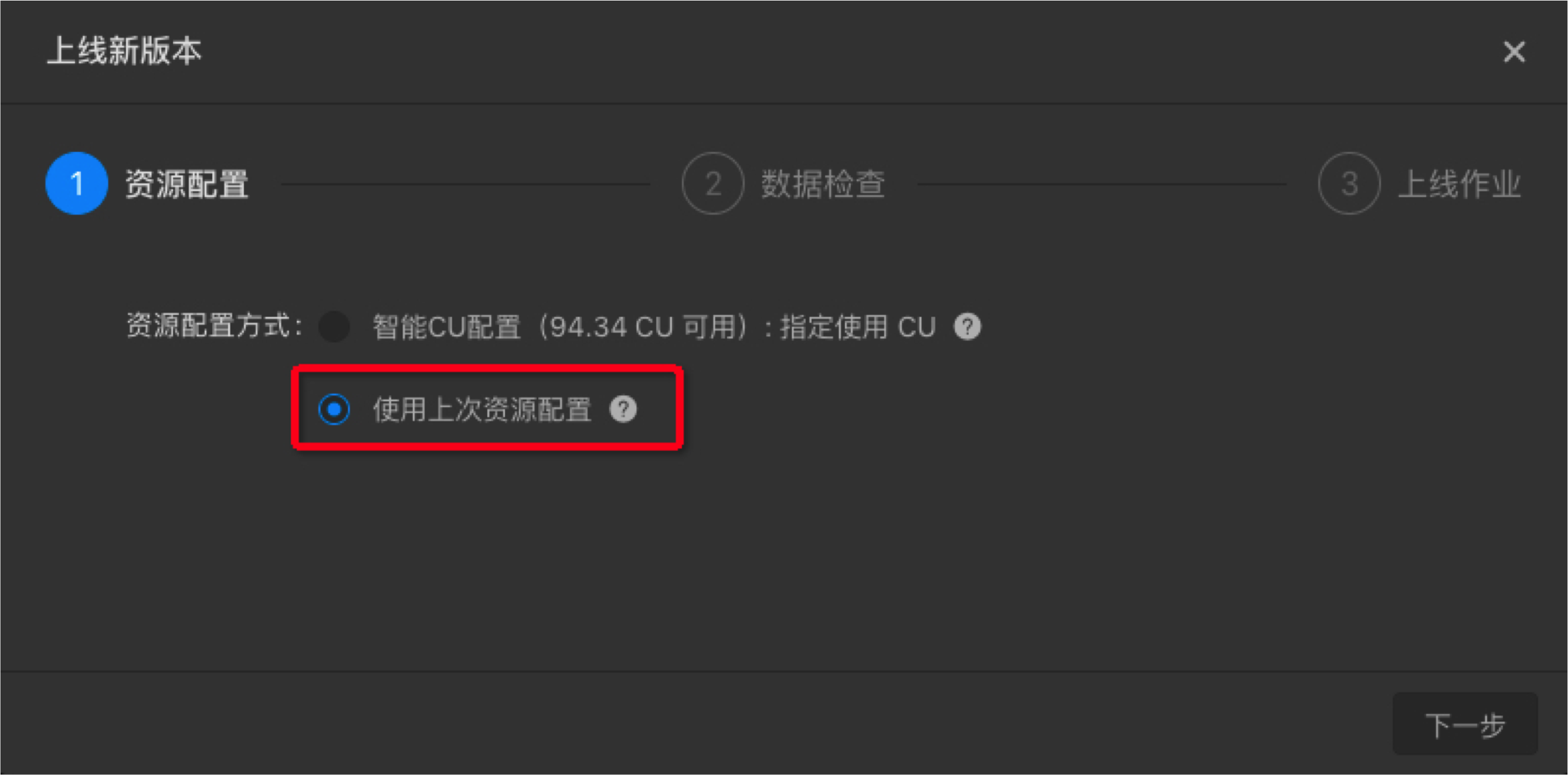
上线作业。选择智能推荐配置,指定使用CU数为系统默认,不填即可。点击下一步。
数据检查,预估消耗CU数。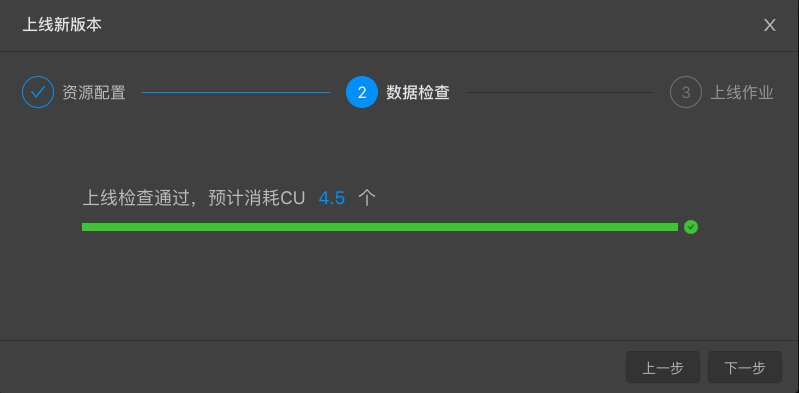
在运维界面启动作业,根据实际业务需要指定读取数据时间。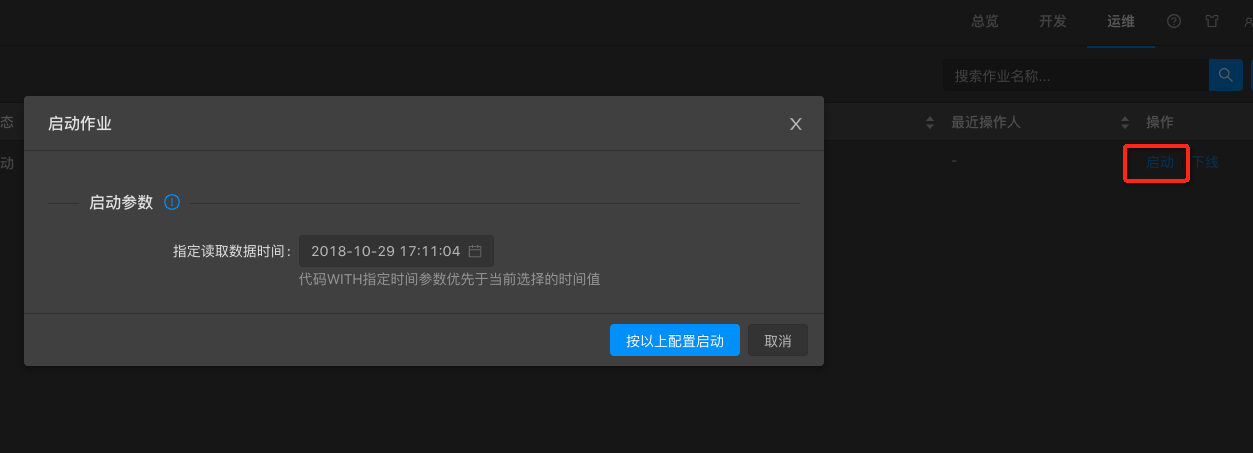
说明:实时计算作业启动时候需要您指定启动时间。实际上就是从源头数据存储的指定时间点开始读取数据。指定读取数据时间需要在作业启动之前。例如,设置启动时间为1小时之前。
待作业稳定运行10分钟后,且以下状态符合要求,即可开始下一次性能调优。

停止>下线作业。
重新上线作业。选择智能推荐配置,指定使用CU数为系统默认,不填即可。点击下一步。
数据检查,再次预估消耗CU数。
在运维界面启动作业,待作业稳定运行十分钟后,即可再一次性能调优。
说明:
- 自动配置调优一般需要3到5次才能达到理想的调优效果。请完成首次性能调优后,重复非首次性能调优过程多次。
- 每次调优前,请确保足够的作业运行时长,建议10分钟以上。
- 指定CU数(参考值) = 实际消耗CU数*目标RPS/当前RPS。
- 实际消耗CU数:上一次作业运行时实际消耗CU
- 目标RPS:输入流数据的实际RPS(或QPS)
- 当前RPS:上一次作业运行时实际的输入RPS
手动配置调优可以分以下三个类型。
资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。
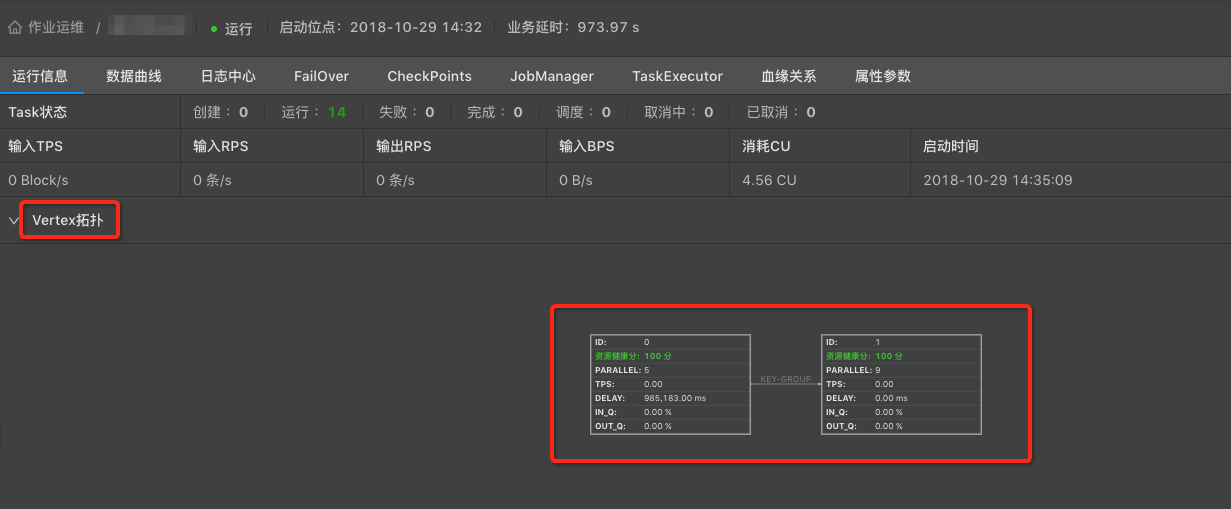
性能瓶颈节点为Vertex拓扑图最下游中参数IN_Q值为100%的一个或者多个节点。如下图,7号节点为性能瓶颈节点。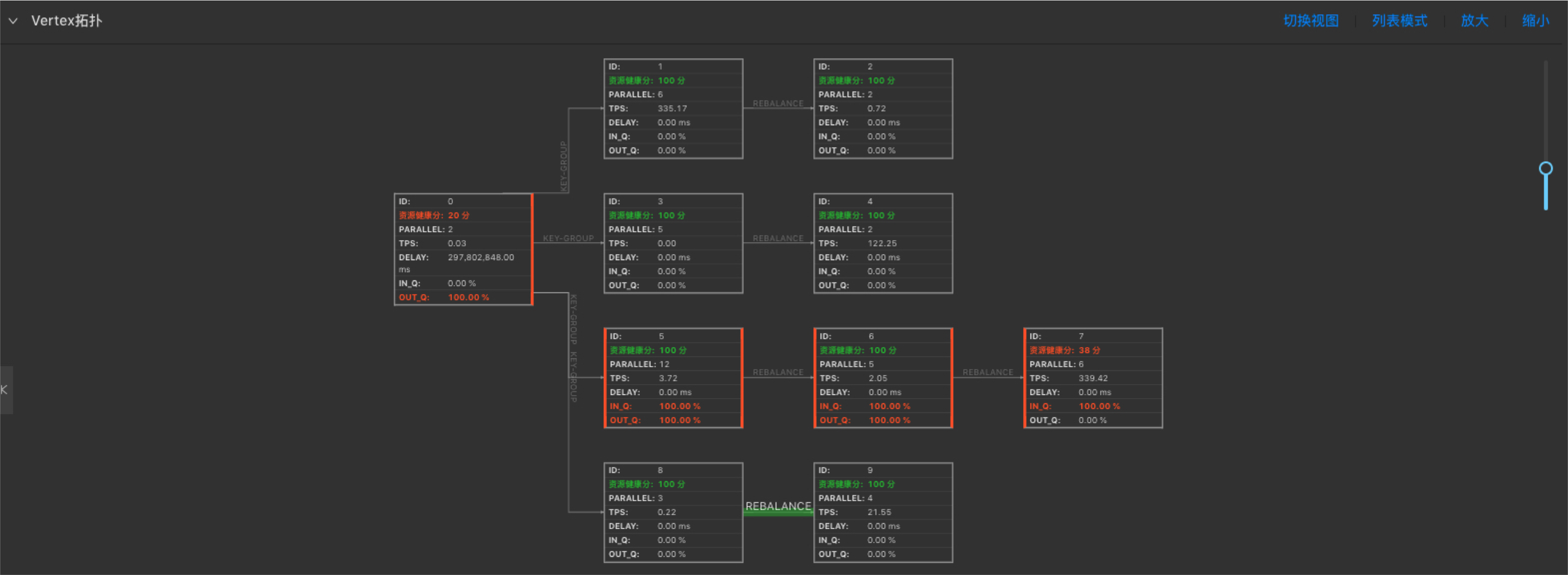
性能瓶颈的可分为三类。
如下图,7号节点的性能瓶颈是资源(CPU和/或MEM)配置不足所导致。
说明:判断性能瓶颈因素方法
- 瓶颈节点的资源健康分为100,则认为资源已经合理分配,性能瓶颈是并发数不足所导致。
- 瓶颈节点的资源健康分低于100,则认为性能瓶颈是单个并发的资源(CPU和/或MEM)配置不足所导致。
- 无持续反压,但资源健康分低于100,仅表明单个并发的资源使用率较高,但暂不影响作业性能,可暂不做调优。
通过作业运维页面中Metrics Graph功能,进一步判断性能瓶颈是CPU不足还是MEM不足。步骤如下。
运维界面中,点击TaskExecutor,找到性能瓶颈节点ID,点击查看详情。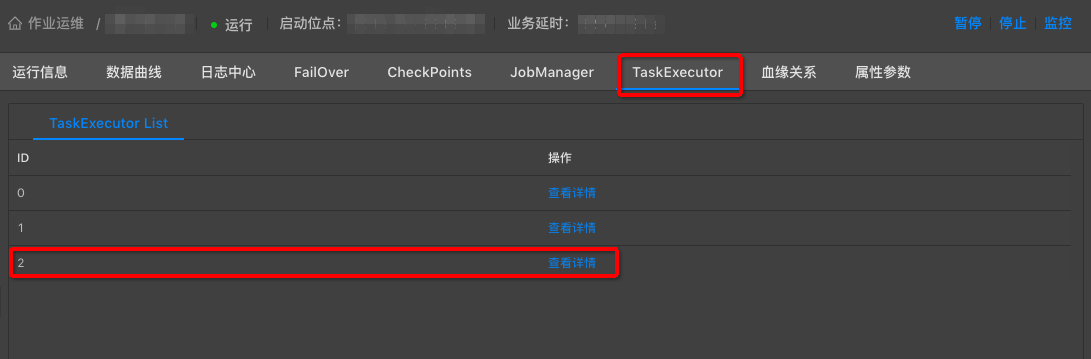
选择Metrics Graph,根据曲线图判断CPU或者MEM是否配置不足(很多情况下两者同时不足)。
完成了性能瓶颈因素判断后,点击开发>基本属性>跳转到新窗口配置,开始调整资源配置。
点击GROUP框,进入批量修改Operator数据窗口。
说明:
- GROUP内所有的operator具有相同的并发数。
- GROUP的core为所有operator的最大值。
- GROUP的_memory为所有operator之和。
- 建议单个Job维度的CPU:MEM=1:4,即1个核对应4G内存。
配置修改完成后点击应用当前配置并关闭窗口。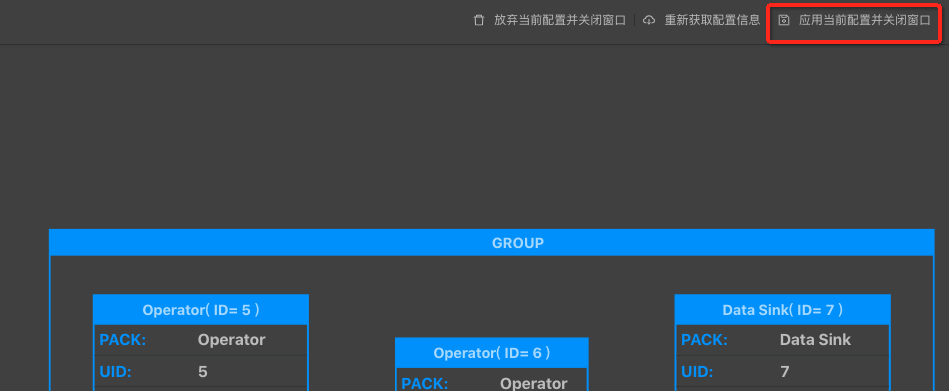
点击Operator框,进入修改Operator数据窗口。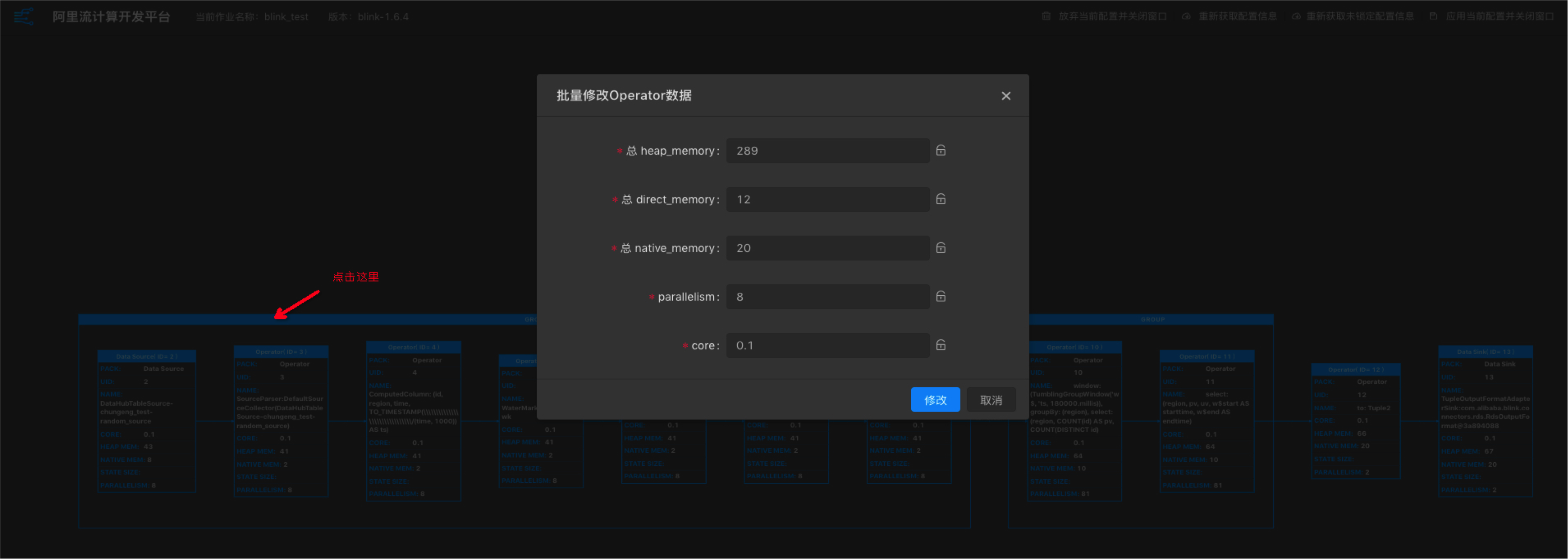
配置修改完成后点击应用当前配置并关闭窗口。
您只需调整parallelism、core和heap_memory三个参数,即能满足大部分的资源调优需求。
在开发页面的右侧选择作业参数。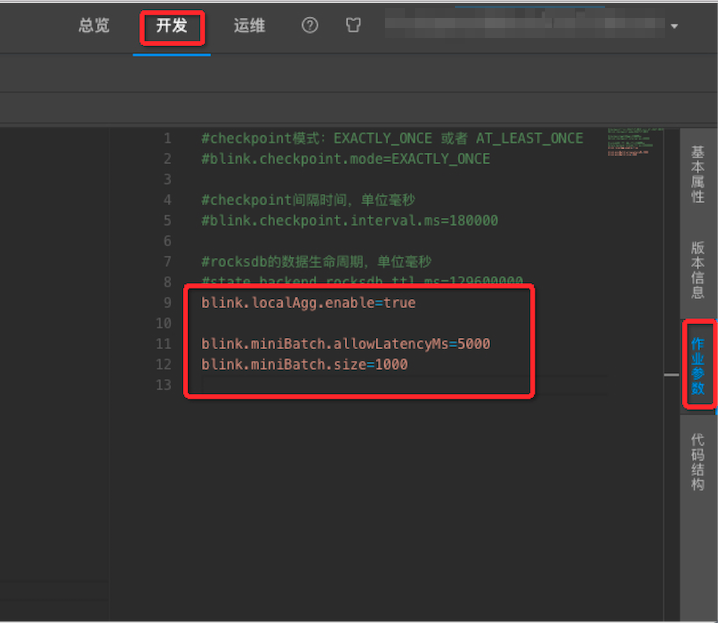
输入调优语句。
| 优化 | 解决问题 | 调优语句 |
|---|---|---|
| MiniBatch | 提升吞吐,降低对下游压力仅对Group by有效。 |
blink.miniBatch.allowLatencyMs=5000blink.miniBatch.size=1000
|
| LocalGlobal | 优化数据倾斜问题 | blink.localAgg.enable=true |
| TTL | 设置State状态时间 |
1.x:state.backend.rocksdb.ttl.ms=1296000002.x:state.backend.niagara.ttl.ms=129600000其中,1.x 表示需显式开启,2.x 表示默认开启。 |
注意:添加或删除MiniBatch或LocalGlobal参数,job状态会丢失,修改值大小状态不会丢失。
实时计算 Flink可以在with参数内设置相应的参数,达到调优上下游存储性能的目的。
调优步骤:

实时计算 Flink的每条数据均会触发上下游存储的读写,会对上下游存储形成性能压力。可以通过设置batchsize,批量的读写上下游存储数据来降低对上下游存储的压力。
| 名字 | 参数 | 详情 | 设置参数值 |
|---|---|---|---|
| Datahub源表 | batchReadSize | 单次读取条数 | 可选,默认为10 |
| Datahub结果表 | batchSize | 单次写入条数 | 可选,默认为300 |
| 日志服务源表 | batchGetSize | 单次读取logGroup条数 | 可选,默认为10 |
| ADB结果表 | batchSize | 每次写入的批次大小 | 可选,默认为1000 |
| RDS结果表 | batchSize | 每次写入的批次大小 | 可选,默认为50 |
注意: 添加、修改或者删除以上参数后,作业必须停止-启动后,调优才能生效。
| 名字 | 参数 | 详情 | 设置参数值 |
|---|---|---|---|
| RDS维表 | Cache | 缓存策略 | 默认值为None,可选LRU、ALL。 |
| RDS维表 | cacheSize | 缓存大小 | 默认值为None,可选LRU、ALL。 |
| RDS维表 | cacheTTLMs | 缓存超时时间 | 默认值为None,可选LRU、ALL。 |
| OTS维表 | Cache | 缓存策略 | 默认值为None, 可选LRU,不支持ALL。 |
| OTS维表 | cacheSize | 缓存大小 | 默认值为None, 可选LRU,不支持ALL。 |
| OTS维表 | cacheTTLMs | 缓存超时时间 | 默认值为None, 可选LRU,不支持ALL。 |
注意: 添加、修改或者删除以上参数后,作业必须停止-启动后,调优才能生效。
说明:完成资源、作业参数、上下游参数调优后,手动配置调优后续的步骤与自动配置调优基本一致。区别在于资源配置环节需要选择使用上次资源配置。
A:可能性1:首次自动配置时指定了CU数,但指定的CU数太小(比如小于自动配置默认算法的建议值,多见于作业比较复杂的情况),建议首次自动配置时不指定CU数。
可能性2:默认算法建议的CU数或指定的CU数超过了项目当前可用的CU数,建议扩容。
A:可能性1:若延时直线上升,需考虑是否上游source中部分partition中没有新的数据,因为目前delay统计的是所有partition的延时最大值。
可能性2:Vertex拓扑中看不到持续反压,那么性能瓶颈点可能出现在source节点。因为source节点没有输入缓存队列,即使有性能问题,IN_Q也永远为0(同样,sink节点的OUT_Q也永远为0)。
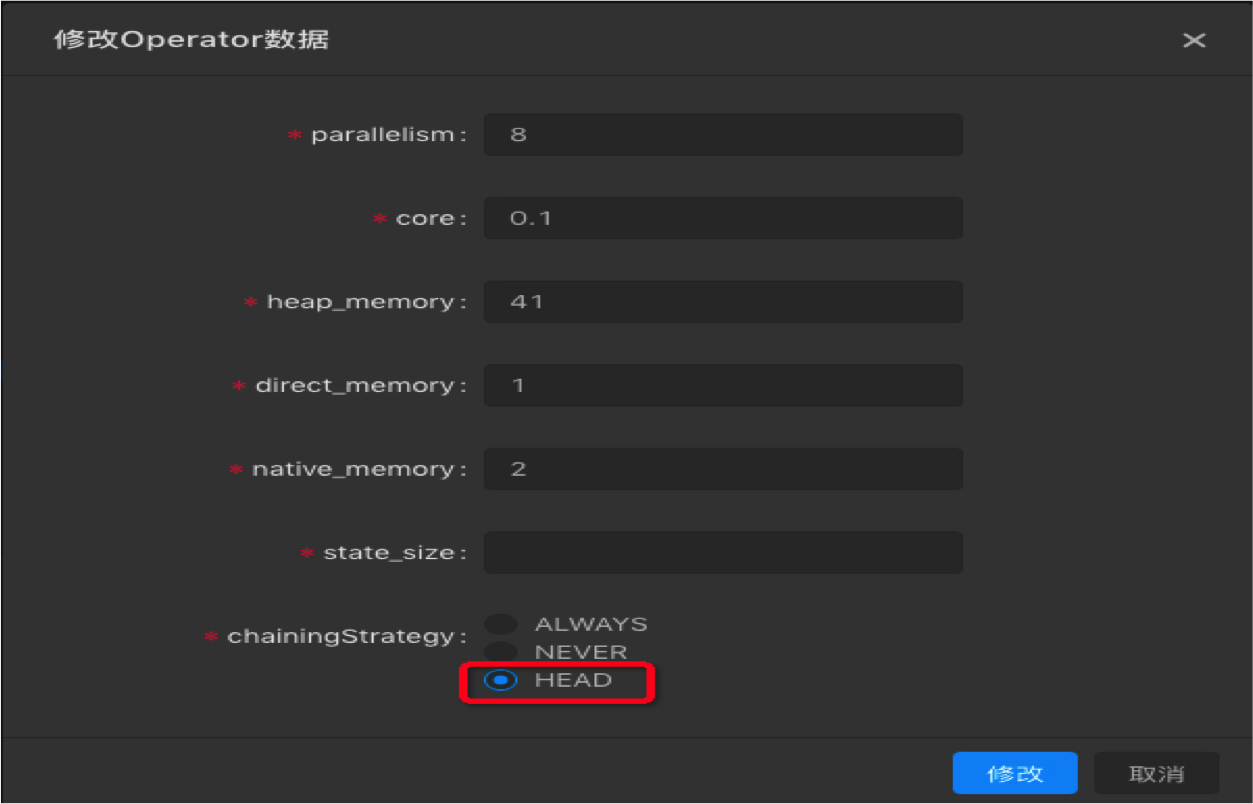
解决方案:通过手动配置调优,将source节点(GROUP)中的operator中chainingStrategy修改为HEAD,将其从GROUP中拆解出来。然后上线运行后再看具体是哪个节点是性能瓶颈节点,若依然看不到性能瓶颈节点,则可能是因为上游source吞吐不够,需考虑增加source的batchsize或增加上游source的shard数。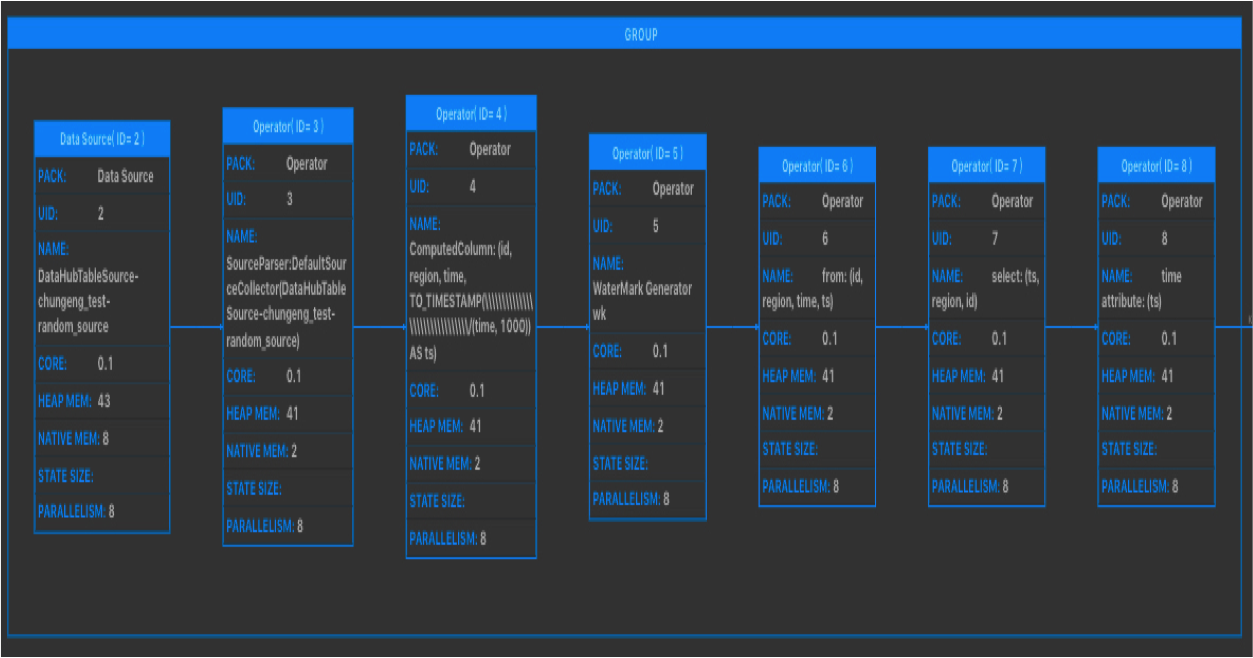
A:Vertex拓扑中某些节点的IN_Q持续为100%则存在持续反压情况,最后一个(或多个)IN_Q为100%的节点为性能瓶颈点。如下示例:
上图存在反压,瓶颈在6号节点。
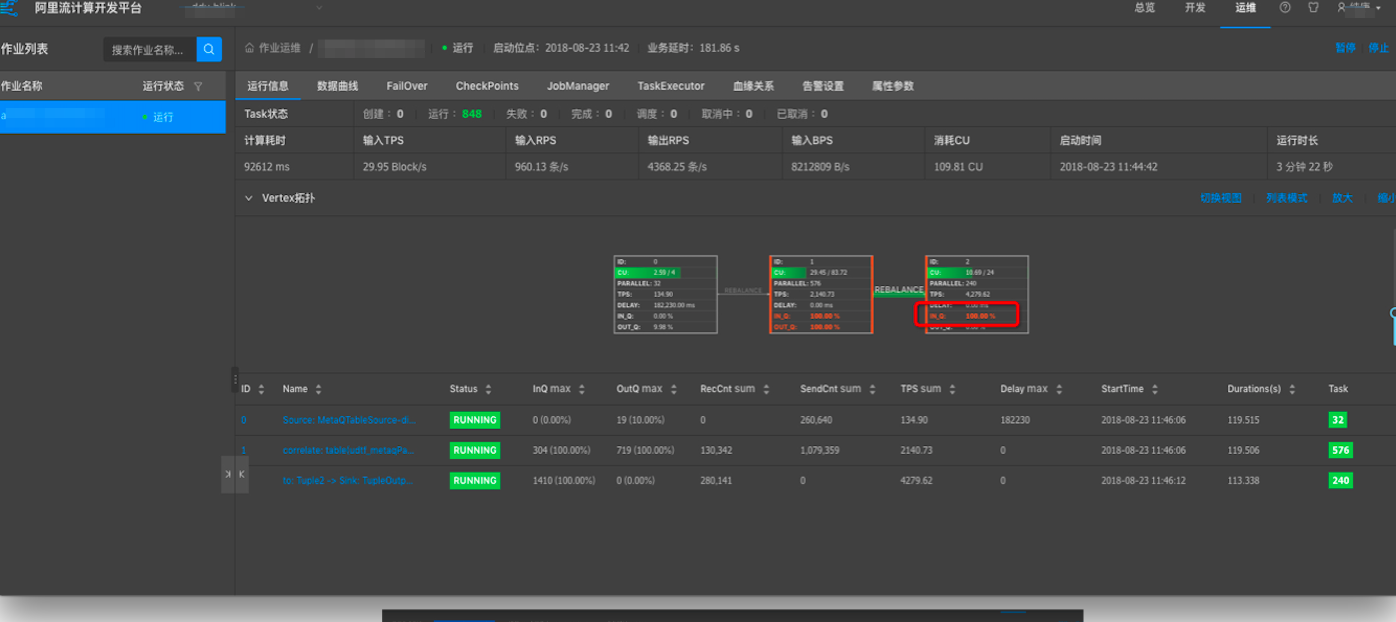
上图存在反压,瓶颈在2号节点。
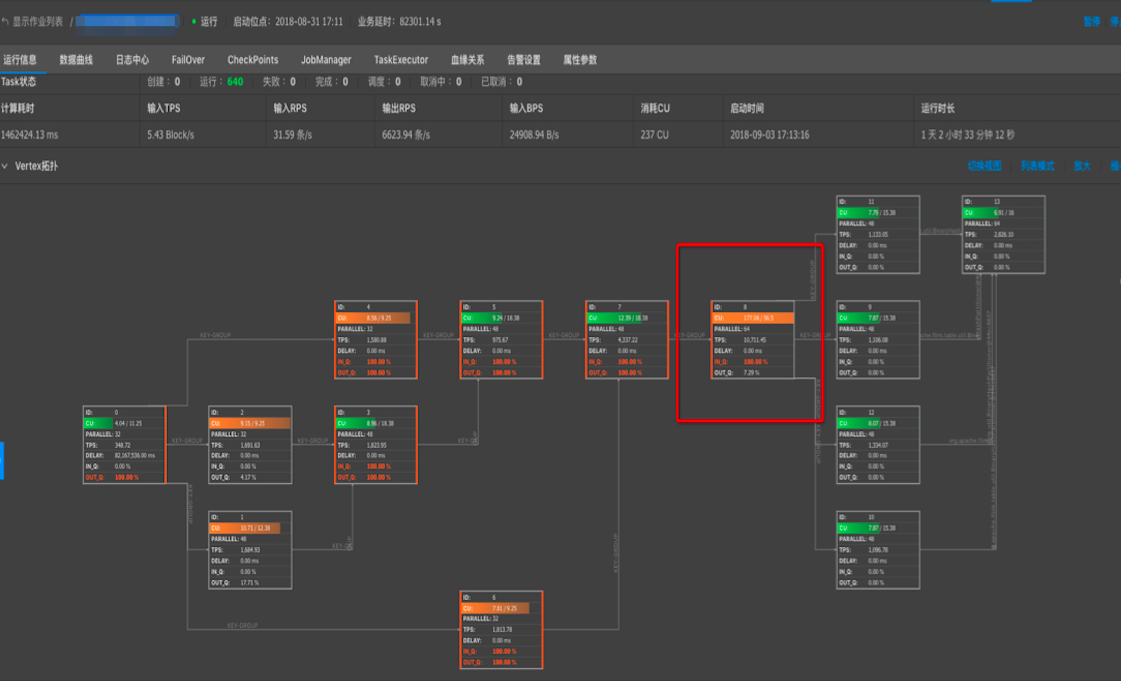
上图存在反压,瓶颈在8号节点。
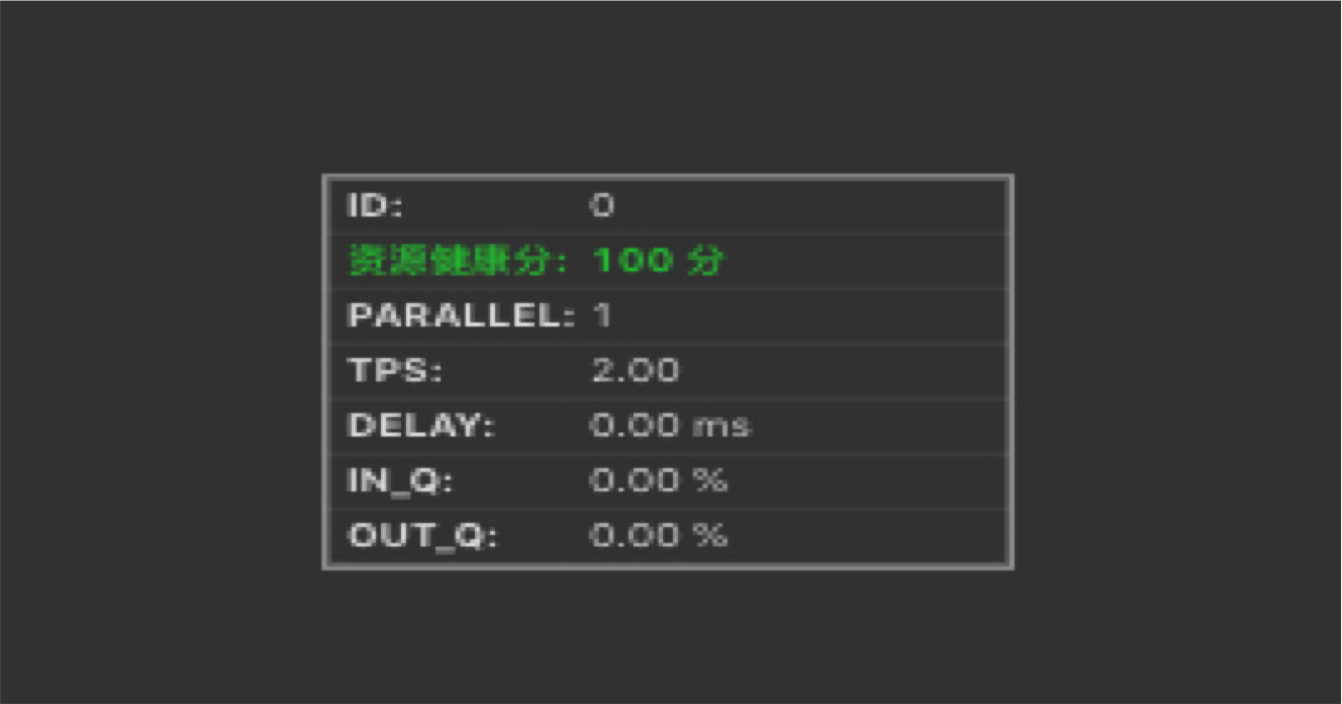
上图可能存在节点,瓶颈在0号节点。
A:(1)表象上看,某些节点不论增加多大的并发仍存在性能瓶颈,则可能存在数据倾斜。
(2)在Vertex拓扑中点击疑似存在数据倾斜的节点(一般为性能瓶颈节点),进入SubTask List界面,重点观察RecvCnt和InQueue,若各ID对应的RecvCnt值差异较大(一般超过1个数量级)则认为存在数据倾斜,若个别ID的InQueue长期为100%,则认为可能存在数据倾斜。
解决方案:请您参看GROUP BY 数据出现热点、数据倾斜。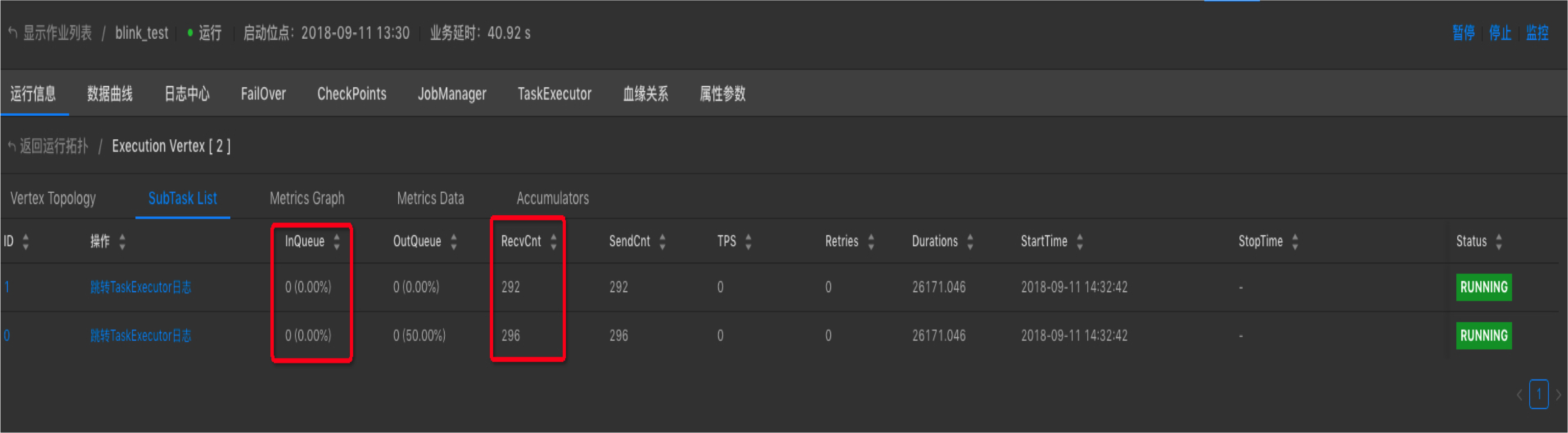
A:这种问题一般发生在Vertex只有一个节点的情况,此时由于source上游的物理表的shard数为1,Flink要求source的并发不能超过上游shard数,导致无法增加并发,因此亦无法增加到指定的CU数。
解决方案:
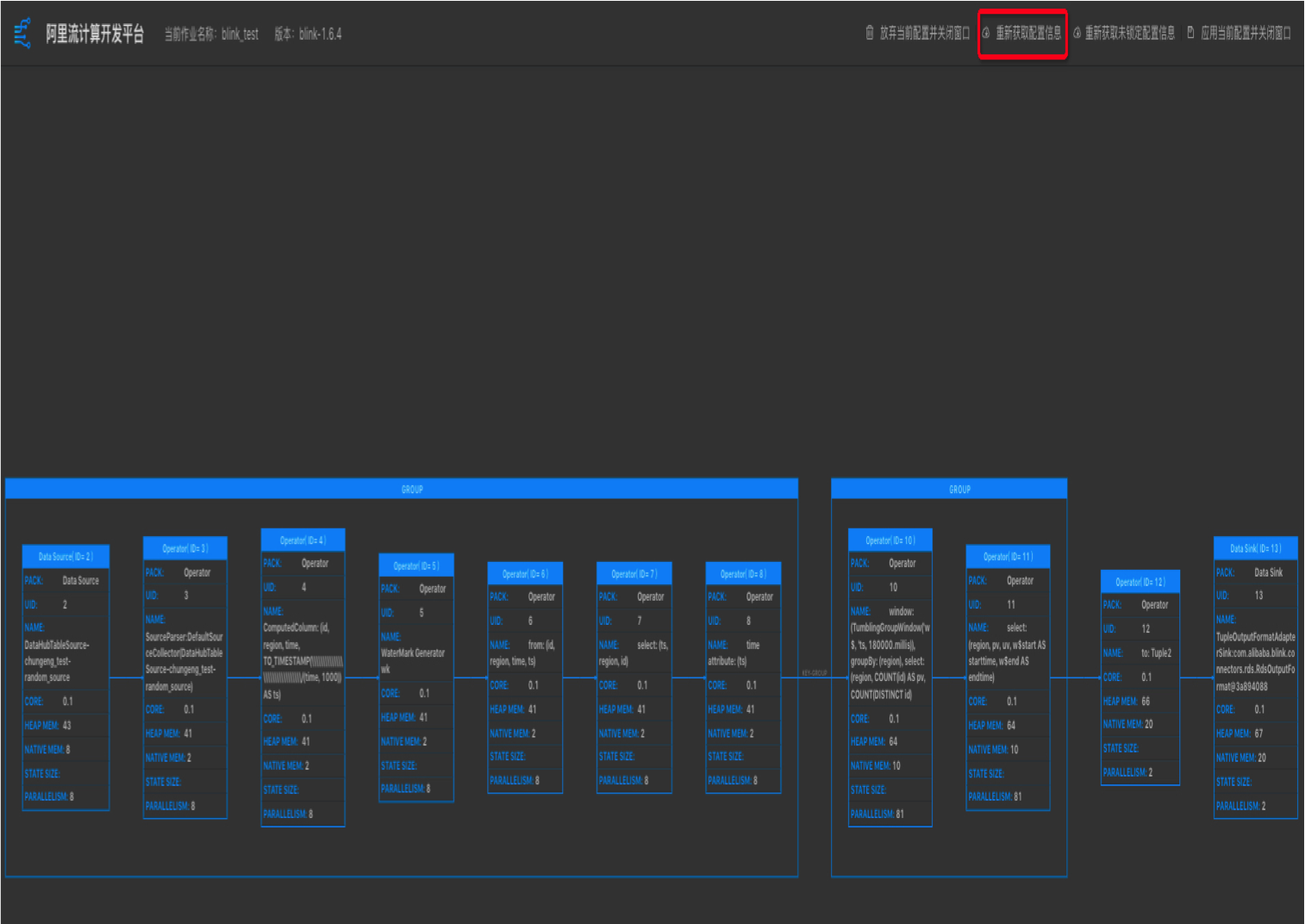
A:这是由于作业的SQL有改动,导致DAG改变。
解决方案:通过重新获取配置解决,开发-基本属性-跳转到新窗口配置-重新获取配置信息。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!