
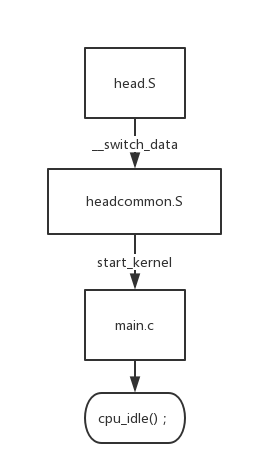
从stext开始到cpu_idle()结束
1、Makefile分析
(1)Makefile中刚开始定义了kernel的内核版本号。这个版本号挺重要(在模块化驱动安装时会需要用到),要注意会查,会改。
(2)在make编译内核时,也可以通过命令行给内核makefile传参(跟uboot配置编译时传参一样)。譬如make O=xxx可以指定不在源代码目录下编译,而到另外一个单独文件夹下编译。
(3)kernel的顶层Makefile中定义了2个变量很重要,一个是ARCH,一个是CROSS_COMPILE。ARCH决定当前配置编译的路径,譬如ARCH = arm的时候,将来在源码目录下去操作的arch/arm目录。CROSS_COMPILE用来指定交叉编译工具链的路径和前缀。
(4)CROSS_COMPILE = xxx和ARCH = xxx和O=xxx这些都可以在make时通过命令行传参的方式传给顶层Makefile。
所以有时候你会看到别人编译内核时:make O=/tmp/mykernel ARCH=arm CROSS_COMPILE=/usr/local/arm/arm-2009q3/bin/arm-none-linux-gnueabi-
2、链接脚本分析
(1)分析连接脚本的目的就是找到整个程序的entry
(2)kernel的连接脚本并不是直接提供的,而是提供了一个汇编文件vmlinux.lds.S,然后在编译的时候再去编译这个汇编文件得到真正的链接脚本vmlinux.lds。
(3)vmlinux.lds.S在arch/arm/kernel/目录下。
(4)思考:为什么linux kernel不直接提供vmlinux.lds而要提供一个vmlinux.lds.S然后在编译时才去动态生成vmlinux.lds呢?
猜测:.lds文件中只能写死,不能用条件编译。但是我们在kernel中链接脚本确实有条件编译的需求(但是lds格式又不支持),于是乎kernel工作者找了个投机取巧的方法,就是把vmlinux.lds写成一个汇编格式,然后汇编器处理的时候顺便条件编译给处理了,得到一个不需要条件编译的vmlinux.lds。
(5)入门在哪里?从vmlinux.lds中ENTRY(stext)可以知道入口符号是stext,在SI中搜索这个符号,发现arch/arm/kernel/目录下的head.S和head-nommu.S中都有。
(6)head.S是启用了MMU情况下的kernel启动文件,相当于uboot中的start.S。head-nommu.S是未使用mmu情况下的kernel启动文件。
3、内核启动的汇编阶段
3.1、head.S文件分析
1、内核运行的物理地址与虚拟地址
(1)KERNEL_RAM_VADDR(VADDR就是virtual address),这个宏定义了内核运行时的虚拟地址。值为0xC0008000
(2)KERNEL_RAM_PADDR(PADDR就是physical address),这个宏定义内核运行时的物理地址。值为0x30008000
(3)总结:内核运行的物理地址是0x30008000,对应的虚拟地址是0xC0008000。
2、内核的真正入口
(1)内核的真正入口就是ENTRY(stext)处
(2)前面的__HEAD定义了后面的代码属于段名为.head.text的段
3、内核运行的硬件条件
(1)内核的起始部分代码是被解压代码调用的。回忆之前讲zImage的时候,uboot启动内核后实际调用运行的是zImage前面的那段未经压缩的解压代码,解压代码运行时先将zImage后段的内核解压开,然后再去调用运行真正的内核入口。
(2)内核启动不是无条件的,而是有一定的先决条件,这个条件由启动内核的bootloader(我们这里就是uboot)来构建保证。
(3)ARM体系中,函数调用时实际是通过寄存器传参的(函数调用时传参有两种设计:一种是寄存器传参,另一种是栈内存传参)。所以uboot中最后theKernel (0, machid, bd->bi_boot_params);执行内核时,运行时实际把0放入r0中,machid放入到了r1中,bd->bi_boot_params放入到了r2中。ARM的这种处理技巧刚好满足了kernel启动的条件和要求。
(4)kernel启动时MMU是关闭的,因此硬件上需要的是物理地址。但是内核是一个整体(zImage)只能被连接到一个地址(不能分散加载),这个连接地址肯定是虚拟地址。因此内核运行时前段head.S中尚未开启MMU之前的这段代码就很难受。所以这段代码必须是位置无关码,而且其中涉及到操作硬件寄存器等时必须使用物理地址。
3.2、内核启动的汇编阶段
1、__lookup_processor_type
(1)我们从cp15协处理器的c0寄存器中读取出硬件的CPU ID号,然后调用这个函数来进行合法性检验。如果合法则继续启动,如果不合法则停止启动,转向__error_p启动失败。
(2)该函数检验cpu id的合法性方法是:内核会维护一个本内核支持的CPU ID号码的数组,然后该函数所做的就是将从硬件中读取的cpu id号码和数组中存储的各个id号码依次对比,如果没有一个相等则不合法,如果有一个相等的则合法。
(3)内核启动时设计这个校验,也是为了内核启动的安全性着想。
2、__lookup_machine_type
(1)该函数的设计理念和思路和上面校验cpu id的函数一样的。不同之处是本函数校验的是机器码。
3、__vet_atags
(1)该函数的设计理念和思路和上面2个一样,不同之处是用来校验uboot给内核的传参ATAGS格式是否正确。这里说的传参指的是uboot通过tag给内核传的参数(主要是板子的内存分布memtag、uboot的bootargs)
(2)内核认为如果uboot给我的传参格式不正确,那么我就不启动。
(3)uboot给内核传参的部分如果不对,是会导致内核不启动的。譬如uboot的bootargs设置不正确内核可能就会不启动。
4、__create_page_tables
(1)顾名思义,这个函数用来建立页表。
(2)linux内核本身被连接在虚拟地址处,因此kernel希望尽快建立页表并且启动MMU进入虚拟地址工作状态。但是kernel本身工作起来后页表体系是非常复杂的,建立起来也不是那么容易的。kernel想了一个好办法
(3)kernel建立页表其实分为2步。第一步,kernel先建立了一个段式页表(和uboot中之前建立的页表一样,页表以1MB为单位来区分的),这里的函数就是建立段式页表的。段式页表本身比较好建立(段式页表1MB一个映射,4GB空间需要4096个页表项,每个页表项4字节,因此一共需要16KB内存来做页表),坏处是比较粗不能精细管理内存;第二步,再去建立一个细页表(4kb为单位的细页表),然后启用新的细页表废除第一步建立的段式映射页表。
(4)内核启动的早期建立段式页表,并在内核启动前期使用;内核启动后期就会再次建立细页表并启用。等内核工作起来之后就只有细页表了。
5、__switch_data(headcommon.S)
(1)建立了段式页表后进入了__switch_data部分,这东西是个函数指针数组。
(2)分析得知下一步要执行__mmap_switched函数
(3)复制数据段、清除bss段(目的是构建C语言运行环境)
(4)保存起来cpu id号、机器码、tag传参的首地址。
(5)b start_kernel跳转到C语言运行阶段。
总结:汇编阶段其实也没干啥,主要原因是uboot干了大部分活。汇编阶段主要就是校验启动合法性、建立段式映射的页表并开启MMU以方便使用内存、跳入C阶段。
4、内核启动的C语言阶段
4.1、杂碎
(1)smp。smp就是对称多处理器(其实就是我们说的多核心CPU)
(2)lockdep。锁定依赖,是一个内核调试模块,处理内核自旋锁死锁问题相关的。
(3)cgroup。control group,内核提供的一种来处理进程组的技术。
4.2、打印内核版本信息
(1)代码位于:kernel/init/main.c中的572行
(2)printk函数是内核中用来从console打印信息的,类似于应用层编程中的printf。内核编程时不能使用标准库函数,因此不能使用printf,其实printk就是内核自己实现的一个printf。
(3)printk函数的用法和printf几乎一样,不同之处在于可以在参数最前面用一个宏来定义消息输出的级别。为什么要有这种级别?主要原因是linux内核太大了,代码量太多,里面的printk打印信息太多了。如果所有的printk都能打印出来而不加任何限制,则最终内核启动后得到海量的输出信息。
(4)为了解决打印信息过多,无效信息会淹没有效信息这个问题,linux内核的解决方案是给每一个printk添加一个打印级别。级别定义0-7(注意编程的时候要用相应的宏定义,不要直接用数字)分别代表8种输出的重要性级别,0表示最重要,7表示最不重要。我们在printk的时候自己根据自己的消息的重要性去设置打印级别。
(5)linux的控制台监测消息的地方也有一个消息过滤显示机制,控制台实际只会显示级别比我的控制台定义的级别高的消息。譬如说控制台的消息显示级别设置为4,那么只有printk中消息级别为0-3(也可能是0-4)的才可以显示看见,其余的被过滤掉了。
(6)linux_banner的内容解析。
4.3、setup_arch函数简介
(1)从名字看,这个函数是CPU架构相关的一些创建过程。
(2)实际上这个函数是用来确定我们当前内核的机器(arch、machine)的。我们的linux内核会支持一种CPU的运行,CPU+开发板就确定了一个硬件平台,然后我们当前配置的内核就在这个平台上可以运行。之前说过的机器码就是给这个硬件平台一个固定的编码,以表征这个平台。
(3)当前内核支持的机器码以及硬件平台相关的一些定义都在这个函数中处理。
4.4、Machine查找
(1)setup_processor函数用来查找CPU信息,可以结合串口打印的信息来分析。
(2)setup_machine函数的传参是机器码编号,machine_arch_type符号在include/generated/mach-types.h的32039-32050行定义了。经过分析后确定这个传参值就是2456.
(3)函数的作用是通过传入的机器码编号,找到对应这个机器码的machine_desc描述符,并且返回这个描述符的指针。
(4)其实真正干活的函数是lookup_machine_type,找这个函数发现在head-common.S中,真正干活的函数是__lookup_machine_type
(5)__lookup_machine_type函数的工作原理:内核在建立的时候就把各种CPU架构的信息组织成一个一个的machine_desc结构体实例,然后都给一个段属性.arch.info.init,链接的时候会保证这些描述符会被连接在一起。__lookup_machine_type就去那个那些描述符所在处依次挨个遍历各个描述符,比对看机器码哪个相同。
4.5、setup_arch函数进行了基本的cmdline处理
(1)这里说的cmdline就是指的uboot给kernel传参时传递的命令行启动参数,也就是uboot的bootargs。
(2)有几个相关的变量需要注意:
default_command_line:看名字是默认的命令行参数,实际是一个全局变量字符数组,这个字符数组可以用来存东西。
CONFIG_CMDLINE:在.config文件中定义的(可以在make menuconfig中去更改设置),这个表示内核的一个默认的命令行参数。
(3)内核对cmdline的处理思路是:内核中自己维护了一个默认的cmdline(就是.config中配置的这一个),然后uboot还可以通过tag给kernel再传递一个cmdline。如果uboot给内核传cmdline成功则内核会优先使用uboot传递的这一个;如果uboot没有给内核传cmdline或者传参失败,则内核会使用自己默认的这个cmdline。以上说的这个处理思路就是在setup_arch函数中实现的。
4.6、实验验证内核的cmdline确定
(1)验证思路:首先给内核配置时配置一个基本的cmdline,然后在uboot启动内核时给uboot设置一个bootargs,然后启动内核看打印出来的cmdline和uboot传参时是否一样。
(2)在uboot中去掉bootargs,然后再次启动内核看打印出来的cmdline是否和内核中设置的默认的cmdline一样。
注意:uboot给内核传递的cmdline非常重要,会影响内核的运行,所以要谨慎。有时候内核启动有问题,可以分析下是不是uboot的bootargs设置不对。
注意:这个传参在这里确定出来之后,还没完。后面还会对这个传参进行解析。解析之后cmdline中的每一个设置项都会对内核启动有影响。
思考:内核为什么要这样设计?
4.7、setup_command_line
(1)也是在处理和命令行参数cmdline有关的任务。
2.16.8.2、parse_early_param&parse_args
(1)解析cmdline传参和其他传参
(2)这里的解析意思是把cmdline的细节设置信息给解析出来。譬如cmdline:console=ttySAC2,115200 root=/dev/mmcblk0p2 rw init=/linuxrc rootfstype=ext3,则解析出的内容就是就是一个字符串数组,数组中依次存放了一个设置项目信息。
console=ttySAC2,115200 一个
root=/dev/mmcblk0p2 rw 一个
init=/linuxrc 一个
rootfstype=ext3 一个
(3)这里只是进行了解析,并没有去处理。也就是说只是把长字符串解析成了短字符串,最多和内核里控制这个相应功能的变量挂钩了,但是并没有去执行。执行的代码在各自模块初始化的代码部分。
4.8、杂碎
(1)trap_init 设置异常向量表
(2)mm_init 内存管理模块初始化
(3)sched_init 内核调度系统初始化
(4)early_irq_init&init_IRQ 中断初始化
(5)console_init 控制台初始化
总结:start_kernel函数中调用了很多的xx_init函数,全都是内核工作需要的模块的初始化函数。这些初始化之后内核就具有了一个基本的可以工作的条件了。
如果把内核比喻成一个复杂机器,那么start_kernel函数就是把这个机器的众多零部件组装在一起形成这个机器,让他具有可以工作的基本条件。
4.9、rest_init
(1)这个函数之前内核的基本组装已经完成。
(2)剩下的一些工作就比较重要了,放在了一个单独的函数中,叫rest_init。
总结:start_kernel函数做的主要工作:打印了一些信息、内核工作需要的模块的初始化被依次调用(譬如内存管理、调度系统、异常处理···)、我们需要重点了解的就是setup_arch中做的2件事情:机器码架构的查找并且执行架构相关的硬件的初始化、uboot给内核的传参cmdline。
5、进入cpu_idle()内核启动完毕
(1)rest_init中调用kernel_thread函数启动了2个内核线程,分别是:kernel_init和kthreadd
(2)调用schedule函数开启了内核的调度系统,从此linux系统开始转起来了。
(3)rest_init最终调用cpu_idle函数结束了整个内核的启动。也就是说linux内核最终结束了一个函数cpu_idle。这个函数里面肯定是死循环。
(4)简单来说,linux内核最终的状态是:有事干的时候去执行有意义的工作(执行各个进程任务),实在没活干的时候就去死循环(实际上死循环也可以看成是一个任务)。
(5)之前已经启动了内核调度系统,调度系统会负责考评系统中所有的进程,这些进程里面只有有哪个需要被运行,调度系统就会终止cpu_idle死循环进程(空闲进程)转而去执行有意义的干活的进程。这样操作系统就转起来了。
6、什么是内核线程
(1)进程和线程。简单来理解,一个运行的程序就是一个进程。所以进程就是任务、进程就是一个独立的程序。独立的意思就是这个程序和别的程序是分开的,这个程序可以被内核单独调用执行或者暂停。
(2)在linux系统中,线程和进程非常相似,几乎可以看成是一样的。实际上我们当前讲课用到的进程和线程的概念就是一样的。
(3)进程/线程就是一个独立的程序。应用层运行一个程序就构成一个用户进程/线程,那么内核中运行一个函数(函数其实就是一个程序)就构成了一个内核进程/线程。
(4)所以我们kernel_thead函数运行一个函数,其实就是把这个函数变成了一个内核线程去运行起来,然后他可以被内核调度系统去调度。说白了就是去调度器注册了一下,以后人家调度的时候会考虑你。
7、linux的进程0、进程1、进程2
(1)截至目前为止,我们一共涉及到3个内核进程/线程。
(2)操作系统是用一个数字来表示/记录一个进程/线程的,这个数字就被称为这个进程的进程号。这个号码是从0开始分配的。因此这里涉及到的三个进程分别是linux系统的进程0、进程1、进程2.
(3)在linux命令行下,使用ps命令可以查看当前linux系统中运行的进程情况。
(4)我们在ubuntu下ps -aux可以看到当前系统运行的所有进程,可以看出进程号是从1开始的。为什么不从0开始,因为进程0不是一个用户进程,而属于内核进程。
(5)三个进程
进程0:进程0其实就是刚才讲过的idle进程,叫空闲进程,也就是死循环。
进程1:kernel_init函数就是进程1,这个进程被称为init进程。
进程2:kthreadd函数就是进程2,这个进程是linux内核的守护进程。这个进程是用来保证linux内核自己本身能正常工作的。
总结1:本节课的重点在于理解linux内核启动后达到的一个稳定状态。注意去对比内核启动后的稳定状态和uboot启动后的稳定状态的区别。
总结2:本节课的第二个重点就是初步理解进程/线程的概念。
总结3:你得明白每个进程有个进程号,进程号从0开始依次分配的。明白进程0是idle进程(idle进程是干嘛的);进程2是ktheadd进程(基本明白干嘛的就行)
总结4:分析到此,发现后续的料都在进程1.所以后面课程会重点从进程1出发,分析之后发生的事情。
8、init进程详解(进程1)
8.1、init进程完成了从内核态向用户态的转变
(1)一个进程2种状态。init进程刚开始运行的时候是内核态,它属于一个内核线程,然后他自己运行了一个用户态下面的程序后把自己强行转成了用户态。因为init进程自身完成了从内核态到用户态的过度,因此后续的其他进程都可以工作在用户态下面了。
(2)内核态下做了什么?重点就做了一件事情,就是挂载根文件系统并试图找到用户态下的那个init程序。init进程要把自己转成用户态就必须运行一个用户态的应用程序(这个应用程序名字一般也叫init),要运行这个应用程序就必须得找到这个应用程序,要找到它就必须得挂载根文件系统,因为所有的应用程序都在文件系统中。
内核源代码中的所有函数都是内核态下面的,执行任何一个都不能脱离内核态。应用程序必须不属于内核源代码,这样才能保证自己是用户态。也就是说我们这里执行的这个init程序和内核不在一起,他是另外提供的。提供这个init程序的那个人就是根文件系统。
(3)用户态下做了什么?init进程大部分有意义的工作都是在用户态下进行的。init进程对我们操作系统的意义在于:其他所有的用户进程都直接或者间接派生自init进程。
(4)如何从内核态跳跃到用户态?还能回来不?
init进程在内核态下面时,通过一个函数kernel_execve来执行一个用户空间编译连接的应用程序就跳跃到用户态了。注意这个跳跃过程中进程号是没有改变的,所以一直是进程1.这个跳跃过程是单向的,也就是说一旦执行了init程序转到了用户态下整个操作系统就算真正的运转起来了,以后只能在用户态下工作了,用户态下想要进入内核态只有走API这一条路了。
8.2、init进程构建了用户交互界面
(1)init进程是其他用户进程的老祖宗。linux系统中一个进程的创建是通过其父进程创建出来的。根据这个理论只要有一个父进程就能生出一堆子孙进程了。
(2)init启动了login进程、命令行进程、shell进程
(3)shell进程启动了其他用户进程。命令行和shell一旦工作了,用户就可以在命令行下通过./xx的方式来执行其他应用程序,每一个应用程序的运行就是一个进程。
总结:本节的主要目的是让大家认识到init进程如何一步步发展成为我们平时看到的那种操作系统的样子。
8.3、打开控制台
(1)linux系统中每个进程都有自己的一个文件描述符表,表中存储的是本进程打开的文件。
(2)linux系统中有一个设计理念:一切届是文件。所以设备也是以文件的方式来访问的。我们要访问一个设备,就要去打开这个设备对应的文件描述符。譬如/dev/fb0这个设备文件就代表LCD显示器设备,/dev/buzzer代表蜂鸣器设备,/dev/console代表控制台设备。
(3)这里我们打开了/dev/console文件,并且复制了2次文件描述符,一共得到了3个文件描述符。这三个文件描述符分别是0、1、2.这三个文件描述符就是所谓的:标准输入、标准输出、标准错误。
(4)进程1打开了三个标准输出输出错误文件,因此后续的进程1衍生出来的所有的进程默认都具有这3个三件描述符。
8.4、挂载根文件系统
(1)prepare_namespace函数中挂载根文件系统
(2)根文件系统在哪里?根文件系统的文件系统类型是什么? uboot通过传参来告诉内核这些信息。
uboot传参中的root=/dev/mmcblk0p2 rw 这一句就是告诉内核根文件系统在哪里
uboot传参中的rootfstype=ext3这一句就是告诉内核rootfs的类型。
(3)如果内核挂载根文件系统成功,则会打印出:VFS: Mounted root (ext3 filesystem) on device 179:2.
如果挂载根文件系统失败,则会打印:No filesystem could mount root, tried: yaffs2
(4)如果内核启动时挂载rootfs失败,则后面肯定没法执行了,肯定会死。内核中设置了启动失败休息5s自动重启的机制,因此这里会自动重启,所以有时候大家会看到反复重启的情况。
(5)如果挂载rootfs失败,可能的原因有:
最常见的错误就是uboot的bootargs设置不对。
rootfs烧录失败(fastboot烧录不容易出错,以前是手工烧录很容易出错)
rootfs本身制作失败的。(尤其是自己做的rootfs,或者别人给的第一次用)
8.5、执行用户态下的进程1程序
(1)上面一旦挂载rootfs成功,则进入rootfs中寻找应用程序的init程序,这个程序就是用户空间的进程1.找到后用run_init_process去执行他
(2)我们如果确定init程序是谁?方法是:
先从uboot传参cmdline中看有没有指定,如果有指定先执行cmdline中指定的程序。cmdline中的init=/linuxrc这个就是指定rootfs中哪个程序是init程序。这里的指定方式就表示我们rootfs的根目录下面有个名字叫linuxrc的程序,这个程序就是init程序。
如果uboot传参cmdline中没有init=xx或者cmdline中指定的这个xx执行失败,还有备用方案。第一备用:/sbin/init,第二备用:/etc/init,第三备用:/bin/init,第四备用:/bin/sh。
如果以上都不成功,则认命了,死了。
9、cmdline常用参数
9.1、格式简介
(1)格式就是由很多个项目用空格隔开依次排列,每个项目中都是项目名=项目值
(2)整个cmdline会被内核启动时解析,解析成一个一个的项目名=项目值的字符串。这些字符串又会被再次解析从而影响启动过程。
9.2、root=
(1)这个是用来指定根文件系统在哪里的
(2)一般格式是root=/dev/xxx(一般如果是nandflash上则/dev/mtdblock2,如果是inand/sd的话则/dev/mmcblk0p2)
(3)如果是nfs的rootfs,则root=/dev/nfs。
9.3、rootfstype=
(1)根文件系统的文件系统类型,一般是jffs2、yaffs2、ext3、ubi
9.4、console=
(1)控制台信息声明,譬如console=/dev/ttySAC0,115200表示控制台使用串口0,波特率是115200.
(2)正常情况下,内核启动的时候会根据console=这个项目来初始化硬件,并且重定位console到具体的一个串口上,所以这里的传参会影响后续是否能从串口终端上接收到内核的信息。
9.5、mem=
(1)mem=用来告诉内核当前系统的内存有多少
9.6、init=
(1)init=用来指定进程1的程序pathname,一般都是init=/linuxrc
9.7、常见cmdline介绍
(1)console=ttySAC2,115200 root=/dev/mmcblk0p2 rw init=/linuxrc rootfstype=ext3
第一种这种方式对应rootfs在SD/iNand/Nand/Nor等物理存储器上。这种对应产品正式出货工作时的情况。
(2)root=/dev/nfs nfsroot=192.168.1.141:/root/s3c2440/build_rootfs/aston_rootfs ip=192.168.1.10:192.168.1.141:192.168.1.1:255.255.255.0::eth0:off init=/linuxrc console=ttySAC0,115200
第二种这种方式对应rootfs在nfs上,这种对应我们实验室开发产品做调试的时候。
10、内核中架构相关代码简介
10.1、内核代码基本分为3块
(1)arch。 本目录下全是cpu架构有关的代码
(2)drivers 本目录下全是硬件的驱动
(3)其他 相同点是这些代码都和硬件无关,因此系统移植和驱动开发的时候这些代码几乎都是不用关注的。
10.2、架构相关的常用目录名及含义
(1)mach。(mach就是machine architecture)。arch/arm目录下的一个mach-xx目录就表示一类machine的定义,这类machine的共同点是都用xx这个cpu来做主芯片。(譬如mach-s5pv210这个文件夹里面都是s5pv210这个主芯片的开发板machine);mach-xx目录里面的一个mach-yy.c文件中定义了一个开发板(一个开发板对应一个机器码),这个是可以被扩展的。
(2)plat(plat是platform的缩写,含义是平台)plat在这里可以理解为SoC,也就是说这个plat目录下都是SoC里面的一些硬件(内部外设)相关的一些代码。
在内核中把SoC内部外设相关的硬件操作代码就叫做平台设备驱动。
(3)include。这个include目录中的所有代码都是架构相关的头文件。(linux内核通用的头文件在内核源码树根目录下的include目录里)
10.3、补充
(1)内核中的文件结构很庞大、很凌乱(不同版本的内核可能一个文件存放的位置是不同的),会给我们初学者带来一定的困扰。
(2)头文件目录include有好几个,譬如:
kernel/include 内核通用头文件
kernel/arch/arm/include 架构相关的头文件
kernel/arch/arm/include/asm
kernel/arch/arm/include/asm/mach
kernel/arch/arm/mach-s5pv210/include/mach
kernel/arch/arm/plat-s5p/include/plat
(3)内核中包含头文件时有一些格式
#include <linux/kernel.h> kernel/include/linux/kernel.h
#include <asm/mach/arch.h> kernel/arch/arm/include/asm/mach/arch.h
#include <asm/setup.h> kernel/arch/arm/include/asm/setup.h
#include <plat/s5pv210.h> kernel/arch/arm/plat-s5p/include/plat/s5pv210.h
(4)有些同名的头文件是有包含关系的,有时候我们需要包含某个头文件时可能并不是直接包含他,而是包含一个包含了他的头文件。
