社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
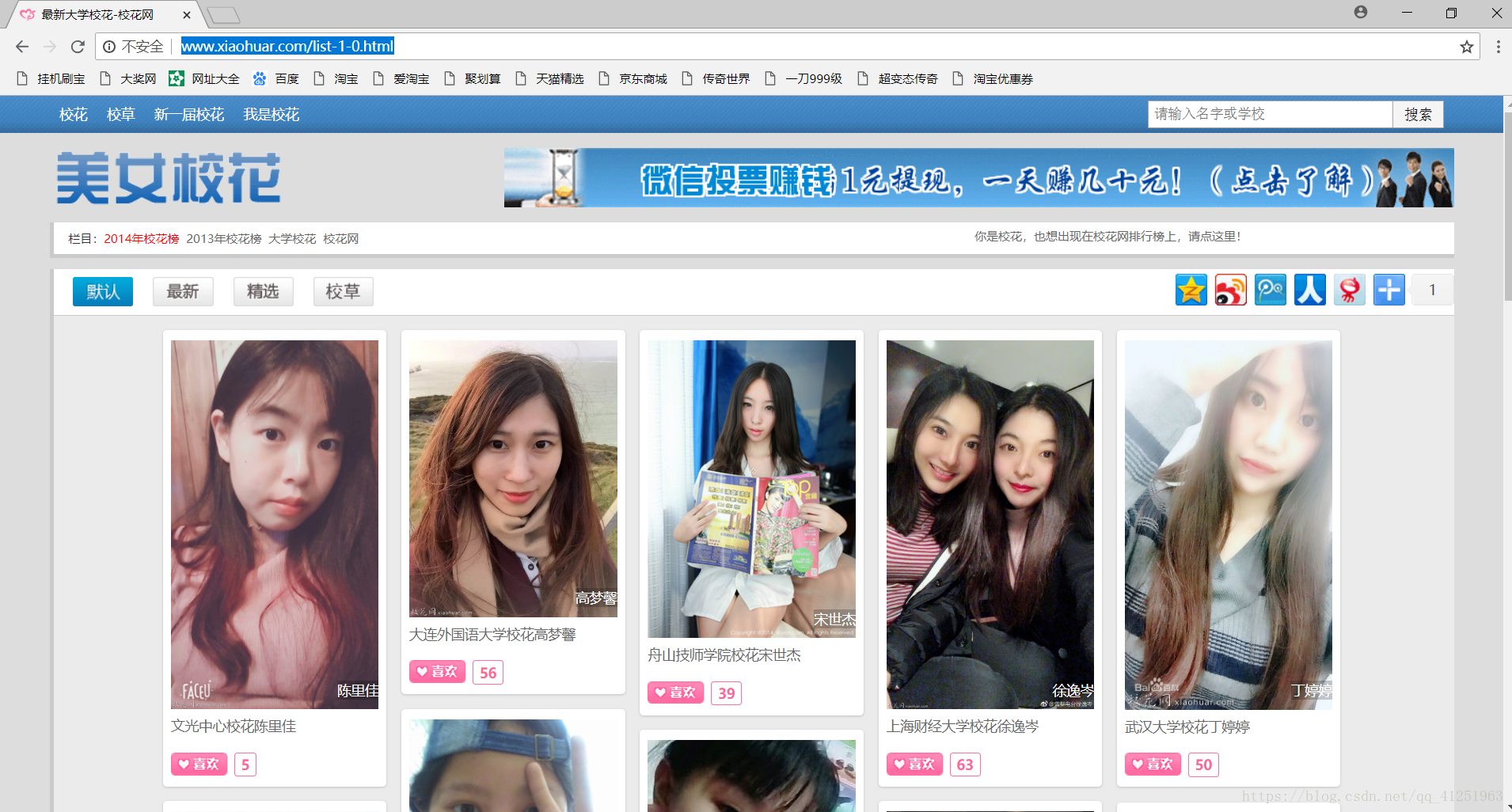
校花网http://www.xiaohuar.com/list-1-0.html
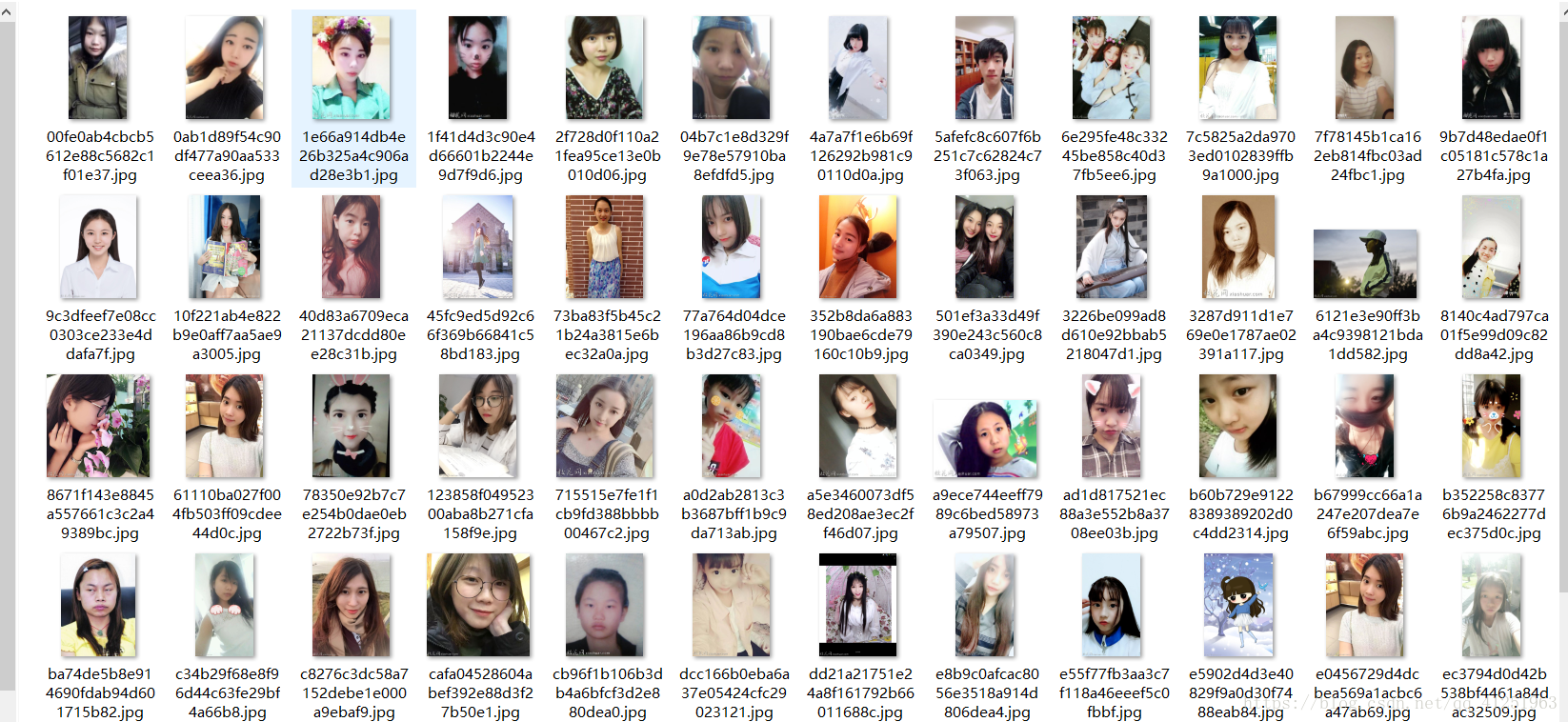
1.进入网站,我们会发现许多图片,这些图片就是我们要爬取的内容。
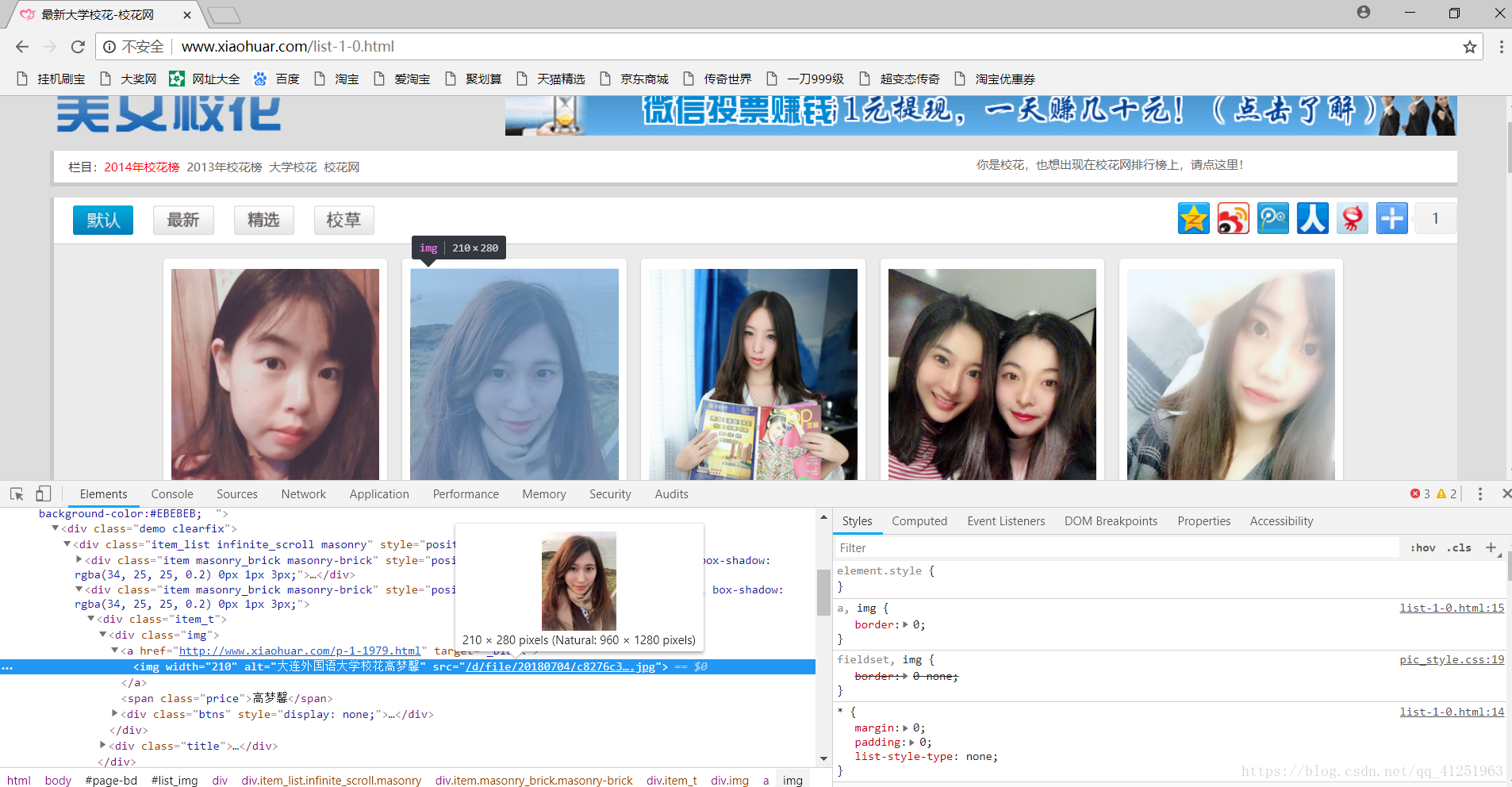
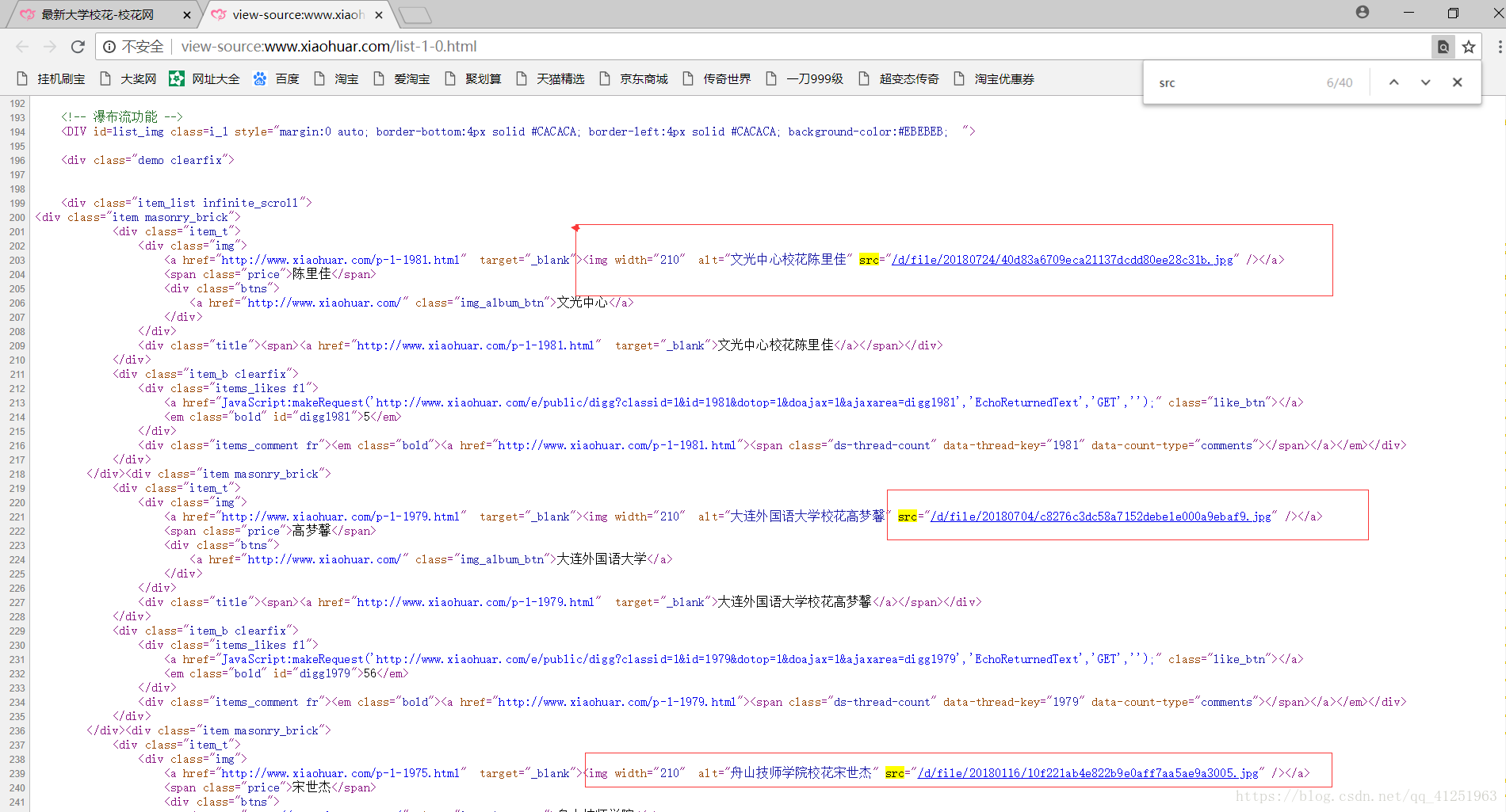
2.对网页进行分析,按F12打开开发着工具(本文使用谷歌浏览器)。我们发现每个图片都对应着一个路径。
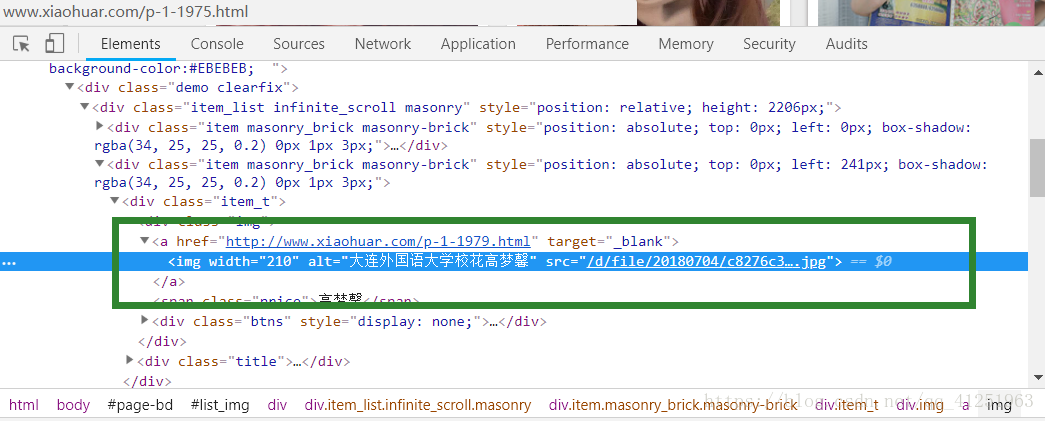
3.我们访问一下img标签的src路径。正是图片的路径,能够获取到图片。因此我们需要获取网页中img标签下的src。
4.找到网页中的src。查看一下网页源代码,谷歌查看网页源代码快捷键(ctrl+u)。所有图片的src都在源代码中,我们使用正则表达式,可以轻松获取src路径。
5.想获取多个网页的图片,就要分析网页网址的规律,打开第二页,第三页,
发现网址分别为http://www.xiaohuar.com/list-1-1.html,http://www.xiaohuar.com/list-1-2.html
,很容易发现url的规律。
6.所有内容我们都分析完了,用代码实现起来很简单。用for循环遍历所有的网址,获取每页的页面内容,从中用正则表达式提取出图片的src。再用for循环去遍历所有图片的image_url。请求image_url,获取到内容,以二进制格式写入文件。
import requests
import re
#获取网页地址
#http://www.xiaohuar.com/list-1-3.html
#http://www.xiaohuar.com/list-1-5.html
url='http://www.xiaohuar.com/list-1-%s.html'
for i in range(4):#4表示要爬取4页图片,这里可根据需求做出修改。
temp=url % i
print(temp)
#获取网页源码
response=requests.get(temp)
html=response.text
#从源码文本中匹配我们需要的url
img_urls=re.findall(r'/d/file/d+/w+.jpg',html)
for img_url in img_urls:
img_response=requests.get('http://www.xiaohuar.com%s'%img_url)
print(img_url)
#图片的二进制信息
img_data=img_response.content
girl=img_url.split('/')[-1]
with open('%s'%girl,'wb') as f:
f.write(img_data)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!