社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
9.1 聚类任务
聚类是一种!无监督!学习任务。
聚类的结果应该满足:“簇内相似度”高且“簇间相似度”低。
聚类的算法:
原型聚类(基于原型的聚类):kk均值算法(k-means)、学习向量量化化算法(LVQ)、高斯混合聚类算法.
原型聚类算法假设聚类结构能够通过一组原型刻画,是最为常用的方法.此类算法首先初始化原型,然后对原型进行迭代更新求解。
密度聚类(基于密度的聚类):DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
密度聚类假设聚类结构能够通过样本分布的紧密程度确定.此类算法从样本密度的角度出发来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇来获得最终的结果.
层次聚类:AGNES算法(AGglomerative NESting).
层次聚类在不同的层次对数据集进行划分,从而形成树形的聚类结构。数据集划分可以是‘自底向上’也可以是‘自顶向下’。
聚类算法在实际应用中非常常见,例如,对音乐CD进行聚类,以达到对音乐CD分类的目的,从而合理地给用户推荐CD;文件中单词的聚类,以将具有相同主题的文章汇合在一块。本文主要介绍以下几种常见的聚类算法,例如:层次聚类算法(Hierarchical algothrim)、k-means算法、 BFR Algorithm、 CURE Algorithm。
9.2 性能度量
聚类性能度量亦称为聚类“有效性指标”(validity index)。
与监督学习中的性能度量作用类似,
对聚类结果,我们需要通过某种性能度量来评估其好坏;
另一方面,若明确了最终要使用的性能度量,则可直接将其作为聚类过程的优化目标,
从而更好地利用符合要求的聚类结果。
9.3 距离计算
9.4 原型聚类
原型聚类-KMeans
KMeans的类表示是聚类中心点,以点xi来表示类,相似性度量同样可以采用常用的距离度量。根据类紧致性准则定义失真函数为所有样本点到该样本所在类中心的失真程度和最小。
9.5 密度聚类
基于密度的聚类,此类算法假设聚类结构能通过样本分布的紧密程度来确定。
基于密度的聚类方法的主要思想是寻找被低密度区域分离的高密度区域。
DBSCAN
小时候开玩笑,想要一个人离自己远一点,会说:“以我为圆心,5米为半径,画个圈,圈里不能有你。”这个规则的后果就是,这个人和我的距离至少有5米,他在我周围的密度就是极小。
密度距离中衡量一个点的密度,和以上有相似的逻辑。如果给定半径内包含的点多于给定的阈值,则认为这个点密度大,称为核心点。而如果这个圈内其他点在同样的规则下也是核心点,称这些点密度可达。随着范围不断扩大,不断判断出新的核心点,直到遇到给定半径内,点数小于阈值的点,我们成为边界点。噪音点是即不能被密度可达有不是核心点的点。
DBSCAN优点是允许带噪声,能发现任意形状,不需要预先给定簇数。文本中特别稀疏数据聚类效果可能不太理想。
密度最大值聚类
高局部密度点距离
知道衡量一个点密度的不同种方法后,确定一种方法,就可以得到样本每个点的局部密度。任选一个点a,设局部密度比点a高出最小量的点为点b,点b到点a的距离就是点a高局部密度点距离,记做di。
如果di很大,ρi也很大,说明这点周围环绕很多其他点,并且比他密度大的点离他距离还很远,则认为这个点是一个聚类中心。如图中点10,和点1。
如果di距离很大,ρi很小,说明他离比他密度高的点比较远,这点离群索居,局部密度还不高,则认为这样的点是噪声。如图点26,27,28。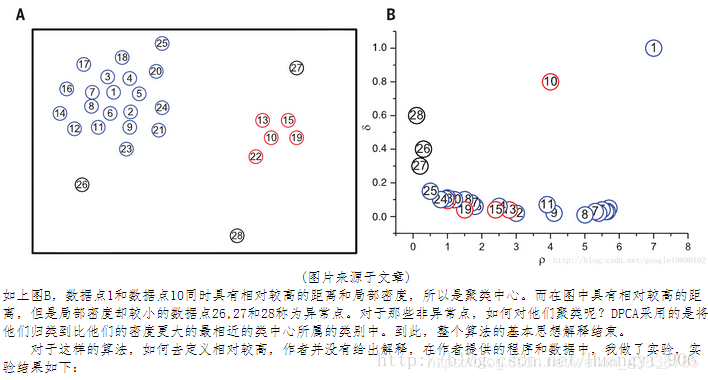
找到聚类中心后,再用其他聚类算法聚类。这个算法主要用在寻找聚类中心。
9.6 层次聚类
主流的聚类算法可以大致分成层次化聚类算法、划分式聚类算法(图论、KMean)、基于密度(DBSCAN)和网格的聚类算法和其他聚类算法。
1.1 基本概念
层次聚类(Hierarchical Clustering)是一种聚类算法,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。
聚类树的创建方法:自下而上的合并,自上而下的分裂。(这里介绍第一种)
1.2 层次聚类的合并算法
层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树。合并过程如下:
我们可以获得一个的距离矩阵 X,其中表示和的距离,称为数据点与数据点之间的距离。记每一个数据点为将距离最小的数据点进行合并,得到一个组合数据点,记为 G
数据点与组合数据点之间的距离: 当计算G 和的距离时,需要计算和G中每一个点的距离。
组合数据点与组合数据点之间的距离:主要有Single Linkage,Complete Linkage和Average Linkage 三种。这三种算法介绍如下,摘自:
Single Linkage
Single Linkage的计算方法是将两个组合数据点中距离最近的两个数据点间的距离作为这两个组合数据点的距离。这种方法容易受到极端值的影响。两个很相似的组合数据点可能由于其中的某个极端的数据点距离较近而组合在一起。
Complete Linkage
Complete Linkage的计算方法与Single Linkage相反,将两个组合数据点中距离最远的两个数据点间的距离作为这两个组合数据点的距离。Complete Linkage的问题也与Single Linkage相反,两个不相似的组合数据点可能由于其中的极端值距离较远而无法组合在一起。
Average Linkage
Average Linkage的计算方法是计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。这种方法计算量比较大,但结果比前两种方法更合理。
二、Python实现
可以直接使用 scipy.cluster.hierarchy.linkage !!!
如下代码实现的是将一组数进行层次聚类。
import queue
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
class clusterNode:
def __init__(self, value, id=[], left=None, right=None, distance=-1, count=-1, check=0):
'''
value: 该节点的数值,合并节点时等于原来节点值的平均值
id:节点的id,包含该节点下的所有单个元素
left和right:合并得到该节点的两个子节点
distance:两个子节点的距离
count:该节点所包含的单个元素个数
check:标识符,用于遍历时记录该节点是否被遍历过
'''
self.value = value
self.id = id
self.left = left
self.right = right
self.distance = distance
self.count = count
self.check = check
def show(self):
# 显示节点相关属性
print(self.value, ' ', self.left.id if self.left != None else None, ' ',
self.right.id if self.right != None else None, ' ', self.distance, ' ', self.count)
class hcluster:
def distance(self, x, y):
# 计算两个节点的距离,可以换成别的距离
return math.sqrt(pow((x.value - y.value), 2))
def minDist(self, dataset):
# 计算所有节点中距离最小的节点对
mindist = 1000
for i in range(len(dataset) - 1):
if dataset[i].check == 1:
# 略过合并过的节点
continue
for j in range(i + 1, len(dataset)):
if dataset[j].check == 1:
continue
dist = self.distance(dataset[i], dataset[j])
if dist < mindist:
mindist = dist
x, y = i, j
return mindist, x, y
# 返回最小距离、距离最小的两个节点的索引
def fit(self, data):
dataset = [clusterNode(value=item, id=[(chr(ord('a') + i))], count=1) for i, item in enumerate(data)]
# 将输入的数据元素转化成节点,并存入节点的列表
length = len(dataset)
Backup = copy.deepcopy(dataset)
# 备份数据
while (True):
mindist, x, y = self.minDist(dataset)
dataset[x].check = 1
dataset[y].check = 1
tmpid = copy.deepcopy(dataset[x].id)
tmpid.extend(dataset[y].id)
dataset.append(clusterNode(value=(dataset[x].value + dataset[y].value) / 2, id=tmpid,
left=dataset[x], right=dataset[y], distance=mindist,
count=dataset[x].count + dataset[y].count))
# 生成新节点
if len(tmpid) == length:
# 当新生成的节点已经包含所有元素时,退出循环,完成聚类
break
for item in dataset:
item.show()
return dataset
def show(self, dataset, num):
plt.figure(1)
showqueue = queue.Queue()
# 存放节点信息的队列
showqueue.put(dataset[len(dataset) - 1])
# 存入根节点
showqueue.put(num)
# 存入根节点的中心横坐标
while not showqueue.empty():
index = showqueue.get()
# 当前绘制的节点
i = showqueue.get()
# 当前绘制节点中心的横坐标
left = i - (index.count) / 2
right = i + (index.count) / 2
if index.left != None:
x = [left, right]
y = [index.distance, index.distance]
plt.plot(x, y)
x = [left, left]
y = [index.distance, index.left.distance]
plt.plot(x, y)
showqueue.put(index.left)
showqueue.put(left)
if index.right != None:
x = [right, right]
y = [index.distance, index.right.distance]
plt.plot(x, y)
showqueue.put(index.right)
showqueue.put(right)
plt.show()
def setData(num):
# 生成num个随机数据
Data = list(np.random.randint(1, 100, size=num))
return Data
if __name__ == '__main__':
num = 20
dataset = setData(num)
h = hcluster()
resultset = h.fit(dataset)
h.show(resultset, num)
输出结果:
"C:Program FilesPython36pythonw.exe" C:/Users/88304/PycharmProjects/untitled8/.idea/svr.py
65 None None -1 1
74 None None -1 1
18 None None -1 1
72 None None -1 1
36 None None -1 1
39 None None -1 1
65 None None -1 1
49 None None -1 1
81 None None -1 1
97 None None -1 1
13 None None -1 1
60 None None -1 1
60 None None -1 1
94 None None -1 1
13 None None -1 1
27 None None -1 1
57 None None -1 1
88 None None -1 1
53 None None -1 1
12 None None -1 1
65.0 ['a'] ['g'] 0.0 2
13.0 ['k'] ['o'] 0.0 2
60.0 ['l'] ['m'] 0.0 2
12.5 ['t'] ['k', 'o'] 1.0 3
73.0 ['b'] ['d'] 2.0 2
37.5 ['e'] ['f'] 3.0 2
95.5 ['j'] ['n'] 3.0 2
58.5 ['q'] ['l', 'm'] 3.0 3
51.0 ['h'] ['s'] 4.0 2
15.25 ['c'] ['t', 'k', 'o'] 5.5 4
61.75 ['a', 'g'] ['q', 'l', 'm'] 6.5 5
84.5 ['i'] ['r'] 7.0 2
32.25 ['p'] ['e', 'f'] 10.5 3
56.375 ['h', 's'] ['a', 'g', 'q', 'l', 'm'] 10.75 7
90.0 ['j', 'n'] ['i', 'r'] 11.0 4
64.6875 ['b', 'd'] ['h', 's', 'a', 'g', 'q', 'l', 'm'] 16.625 9
23.75 ['c', 't', 'k', 'o'] ['p', 'e', 'f'] 17.0 7
77.34375 ['j', 'n', 'i', 'r'] ['b', 'd', 'h', 's', 'a', 'g', 'q', 'l', 'm'] 25.3125 13
50.546875 ['c', 't', 'k', 'o', 'p', 'e', 'f'] ['j', 'n', 'i', 'r', 'b', 'd', 'h', 's', 'a', 'g', 'q', 'l', 'm'] 53.59375 20
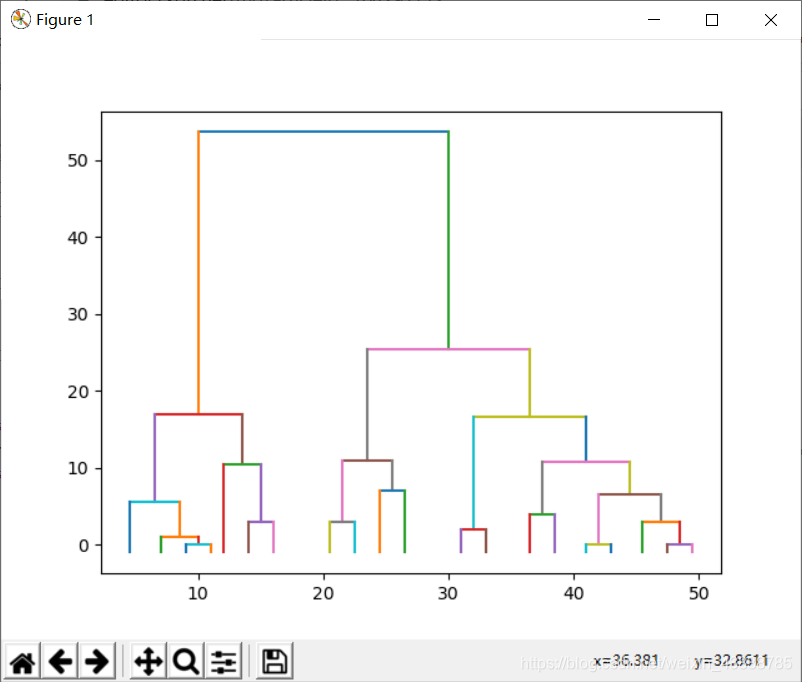
在数学建模中很有用哦》
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
