社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
整型:byte,short,int,long
浮点型:float,double
字符型:char
布尔型:boolean
数组
类
接口
Java 程序在执行子类的构造方法之前,如果没有用 super()来调用父类特 定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中 只定义了有参数的构造方法,而在子类的构造方法中又没有用 super()来 调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类 中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做 事且没有参数的构造方法。
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象 实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象 (一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指 向它(可以用n条绳子系住一个气球)。
final关键字主要用在三个地方:变量、方法、类。
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化 之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让 其指向另一个对象。
当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方 法都会被隐式地指定为final方法。
使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修 改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方 法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何 性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。 类中所有的private方法都隐式地指定为final。
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一 个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于 TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服 务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数 据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服 务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务 器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受 到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由 于服务器收不到确认,就知道客户端并没有请求连接。
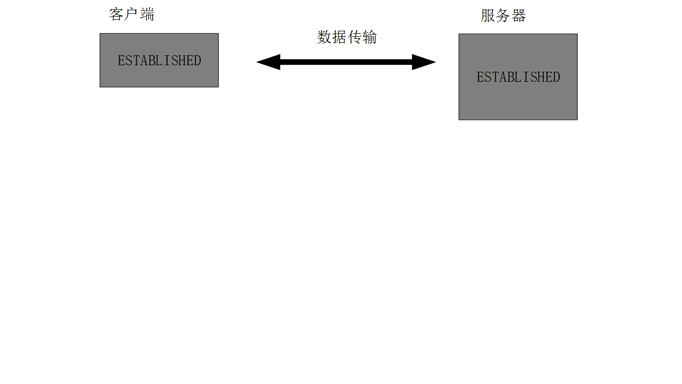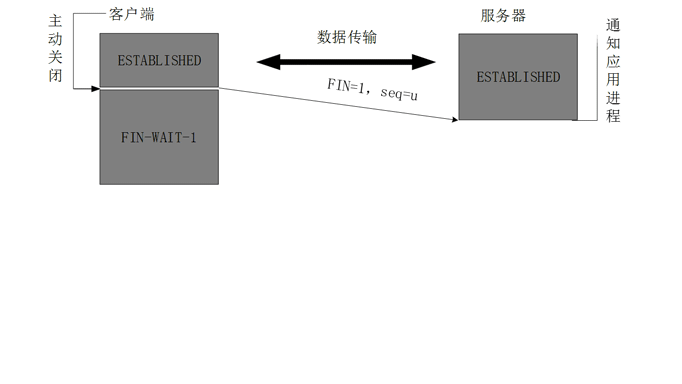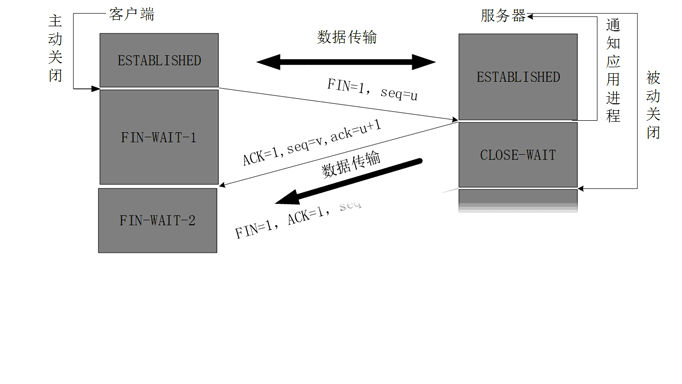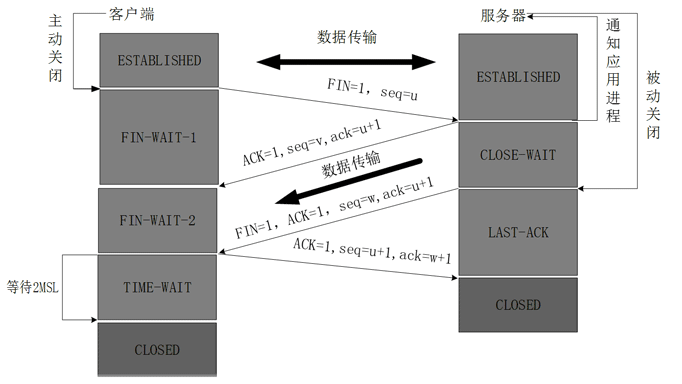
###为什么在四次挥手客户端最后还要等待2MSL?
MSL(Maximum Segment Lifetime),TCP允许不同的实现可以设置不同 的MSL值。
第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报 文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开 了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于 是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重 传的报文,接着给出回应报文,并且会重启2MSL计时器。
第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现 在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可 以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连 接中不会出现旧连接的请求报文。
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文 后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
抽象类是关键字abstract修饰的类,既为抽象类,抽象抽象即不能被实例化。而不能被实例化就无用处,所以抽象类只能作为基类(父类),即被继承的类。抽象类中可以包含抽象方法也可以不包含,但具有抽象方法的类一定是抽象类。 抽象类的使用原则如下:
(1)被继承性:抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public;
(2)抽象性:抽象类不能直接实例化,需要依靠子类采用向上转型的方式处理;
(3)抽象类必须有子类,使用extends继承,一个子类只能继承一个抽象类;
(4)子类(如果不是抽象类)则必须覆写抽象类之中的全部抽象方法(如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
一个接口可以有多个方法。 接口文件保存在 .java 结尾的文件中,文件名使用接口名。 接口的字节码文件保存在 .class 结尾的文件中。 接口相应的字节码文件必须在与包名称相匹配的目录结构中。
接口不能用于实例化对象。 接口没有构造方法。 接口中所有的方法必须是抽象方法。 接口不能包含成员变量,除了 static 和 final 变量。 接口不是被类继承了,而是要被类实现。 接口支持多继承。
接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。
接口中可以含有变量,但是接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。
接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。


被static修饰的内部类可以直接作为一个普通类来使用,而不需实例一个外部类
在C/C++中static是可以作用域局部变量的,但是在Java中切记:static是不允许用来修饰局部变量。不要问为什么,这是Java语法的规定。
public class Test extends Base{ static{
System.out.println("test static");
}
public Test(){
System.out.println("test constructor");
}
` public static void main(String[] args) {
new Test();
}
}`
class Base{
static{
System.out.println("base static");
}
public Base(){
System.out.println("base constructor");
} `}` 输出:
`base static
test static
base constructor
test constructor ` 先来想一下这段代码具体的执行过程,在执行开始,先要寻找到main方法,因为main方法是程序的入口,但是在执行main方法之前,必须先加载Test类,而在加载Test类的时候发现Test类继承自Base类,因此会转去先加载Base类,在加载Base类的时候,发现有static块,便执行了static块。在Base类加载完成之后,便继续加载Test类,然后发现Test类中也有static块,便执行static块。在加载完所需的类之后,便开始执行main方法。在main方法中执行new Test()的时候会先调用父类的构造器,然后再调用自身的构造器。因此,便出现了上面的输出结果。
static块可以出现类中的任何地方(只要不是方法内部,记住,任何方法内部都不行),并且执行是按照static块的顺序执行的。
这段代码的输出结果是什么?
` public class Test {
Person person = new Person(“Test”);
`
` static{
System.out.println(“test static”);
}
`
public Test() {
` System.out.println(“test constructor”); `
} `
public static void main(String[] args) {
new MyClass();
}
}
class Person{
` static{
System.out.println(“person static”);
}
public Person(String str) { `
` System.out.println(“person “+str);
}
} `
class MyClass extends Test {
` Person person = new Person(“MyClass”); `
` static{
System.out.println(“myclass static”);
}`
public MyClass() {
System.out.println("myclass constructor");
} ` } ` 输出: ` test static ` ` myclass static ` ` person static ` ` person Test` ` test constructor` ` person MyClass` ` myclass constructor` ##### 思路: 首先加载Test类,因此会执行Test类中的static块。接着执行new MyClass(),而MyClass类还没有被加载,因此需要加载MyClass类。在加载MyClass类的时候,发现MyClass类继承自Test类,但是由于Test类已经被加载了,所以只需要加载MyClass类,那么就会执行MyClass类的中的static块。在加载完之后,就通过构造器来生成对象。而在生成对象的时候,***必须先初始化父类的成员变量***,因此会执行Test中的Person person = new Person(),而Person类还没有被加载过,因此会先加载Person类并执行Person类中的static块,接着执行父类的构造器,完成了父类的初始化,然后就来初始化自身了,因此会接着执行MyClass中的Person person = new Person(),最后执行MyClass的构造器。
final变量(常量) 用final修饰的成员变量表示常量,值一旦给定就无法改变! final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。 从下面的例子中可以看出,一旦给final变量初值后,值就不能再改变了。 另外,final变量定义的时候,可以先声明,而不给初值,这中变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。但是,final空白在final关键字final的使用上提供了更大的灵活性,为此,一个类中的final数据成员就可以实现依对象而有所不同,却有保持其恒定不变的特征。
static和final一块用表示什么 static final用来修饰成员变量和成员方法,可简单理解为“全局常量”! 对于变量,表示一旦给值就不可修改,并且通过类名可以访问。 对于方法,表示不可覆盖,并且可以通过类名直接访问。
** 特别要注意一个问题: **
对于被static和final修饰过的实例常量,实例本身不能再改变了,但**对于一些容器类型(比如,ArrayList、HashMap)的实例变量,不可以改变容器变量本身,但可以修改容器中存放的对象,**这一点在编程中用到很多。
Java关键字this只能用于方法方法体内。当一个对象创建后,
Java虚拟机(JVM)就会给这个对象分配一个引用自身的指针,这个指针的名字就是this。因此,this只能在类中的非静态方法中使用,静态方法和静态的代码块中绝对不能出现this,这在“Java关键字static、final使用总结”一文中给出了明确解释。并且this只和特定的对象关联,而不和类关联,同一个类的不同对象有不同的this。
super关键和this作用类似,是被屏蔽的成员变量或者成员方法 或变为可见,或者说用来引用被屏蔽的成员变量和成员成员方法。 不过super是用在子类中,目的是访问直接父类中被屏蔽的成员,注意是直接父类(就是类之上最近的超类)。
匿名内部类也就是没有名字的内部类
正因为没有名字,所以匿名内部类只能使用一次,它通常用来简化代码编写
但使用匿名内部类还有个前提条件:必须继承一个父类或实现一个接口
abstract class Person {
public abstract void eat();}public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}} 可以看到,我们直接将抽象类Person中的方法在大括号中实现了
这样便可以省略一个类的书写
并且,匿名内部类还能用于接口上
interface Person {
public void eat();}public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}} 由上面的例子可以看出,只要一个类是抽象的或是一个接口,那么其子类中的方法都可以使用匿名内部类来实现
最常用的情况就是在多线程的实现上,因为要实现多线程必须继承Thread类或是继承Runnable接口
public class Demo {
public static void main(String[] args) {
Thread t = new Thread() {
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.print(i + " ");
}
}
};
t.start();
}} #### Runnable接口的匿名内部类实现
public class Demo {
public static void main(String[] args) {
Runnable r = new Runnable() {
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.print(i + " ");
}
}
};
Thread t = new Thread(r);
t.start();
}}
转载自:https://blog.csdn.net/FateRuler/article/details/81158510
它是最基础的收集算法。 原理:分为标记和清除两个阶段:首先标记出所有的需要回收的对象,在标记完成以后统一回收所有被标记的对象。 特点:(1)效率问题,标记和清除的效率都不高;(2)空间的问题,标记清除以后会产生大量不连续的空间碎片,空间碎片太多可能会导致程序运行过程需要分配较大的对象时候,无法找到足够连续内存而不得不提前触发一次垃圾收集。 地方 :适合在老年代进行垃圾回收,比如CMS收集器就是采用该算法进行回收的。
原理:分为标记和整理两个阶段:首先标记出所有需要回收的对象,让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。 特点:不会产生空间碎片,但是整理会花一定的时间。 地方:适合老年代进行垃圾收集,parallel Old(针对parallel scanvange gc的) gc和Serial old收集器就是采用该算法进行回收的。
原理:它先将可用的内存按容量划分为大小相同的两块,每次只是用其中的一块。当这块内存用完了,就将还存活着的对象复制到另一块上面,然后把已经使用过的内存空间一次清理掉。 特点:没有内存碎片,只要移动堆顶指针,按顺序分配内存即可。代价是将内存缩小位原来的一半。 地方:适合新生代区进行垃圾回收。serial new,parallel new和parallel scanvage 收集器,就是采用该算法进行回收的。
由于新生代都是朝生夕死的,所以不需要1:1划分内存空间,可以将内存划分为一块较大的Eden和两块较小的Suvivor空间。每次使用Eden和其中一块Survivor。当回收的时候,将Eden和Survivor中还活着的对象一次性地复制到另一块Survivor空间上,最后清理掉Eden和刚才使用过的Suevivor空间。其中Eden和Suevivor的大小比例是8:1。缺点是需要老年代进行分配担保,如果第二块的Survovor空间不够的时候,需要对老年代进行垃圾回收,然后存储新生代的对象,这些新生代当然会直接进入来老年代。
优化收集方法的思路 分代收集算法 原理:根据对象存活的周期的不同将内存划分为几块,然后再选择合适的收集算法。 一般是把java堆分成新生代和老年代,这样就可以根据各个年待的特点采用最适合的收集算法。在新生代中,每次垃圾收集都会有大量的对象死去,只有少量存活,所以选用复制算法。老年代因为对象存活率高,没有额外空间对他进行分配担保,所以一般采用标记整理或者标记清除算法进行回收。
对于以上两种标记算法存在争议,在深入了解JVM最佳实践第二版中,是写的标记需要回收的对象,我也没太深入思考,直到有人提出来,我也去查了一下和想了一下。我个人现在偏向,标记存活的对象。 标记算法的大概流程:通过引用链给所有存活的对象做个标记,然后回收所有没有标记的对象 和 清除存活对象的标记,等待下一次GC
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

