社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Threading用于提供线程相关的操作。线程是应用程序中工作的最小单元,它被包含在进程之中,是进程中的实际运作单位。
当不同的线程需要操作共享数据时,当两个或以上对共享内存的操作发生在并发线程中,并且至少有一个可以改变数据,又没有同步机制的条件下,就会产生竞争条件,可能会导致执行无效代码、bug、或异常行为。
需要通过某些机制控制共享数据的读写,确保同一个时刻只能有一个线程能写数据。Threading模块有一系列同步原语控制实现线程共享数据的同步。
threading模块提供的可直接调用函数:
| 方法名 | 详细说明 |
|---|---|
| threading.active_count() | 返回当前处于激活状态的Thread对象个数,返回的个数等于threading.enumerate()返回的list的长度 |
| threading.current_thread() | 返回当前的Thread对象,相当于调用者的线程 |
| threading.get_ident() | 返回当前线程的线程identifier,这是一个非零值 |
| threading.enumerate() | 返回当前处于激活状态的Thread对象,以list形式返回,包含daemonic线程,dummy线程和main线程 |
| threading.main_thread() | 返回main线程对象,一般是Python解释器开始运行的线程 |
| threading.settrace(func) | 为所有从threading module创建的线程设置一个trace函数,该函数会在每个线程的run()方法被调用前,被传给sys.settrace() |
| threading.setprofile(func) | 为所有从threading module创建的线程设置一个profile函数,该函数会在每个线程的run()方法被调用前,被传给sys.setprofile() |
| threading.stack_size([size]) | 当创建一个新的线程时返回该线程使用的stack size,size参数可选,用来指定所创建线程的stack size,必须是0或是一个至少为32768的正整数。size未指定会默认使用0值,RuntimeError表示改变stack size不支持,ValueError表示stack size非法值。32K的stack size是目前支持最小的值,足够的stack空间主要是解释器本身需要占用。一般memory是4096 Bytes一个page,Stack size建议设置为4K Bytes的倍数 |
| threading.TIMEOUT_MAX | 阻塞函数(Lock.acquire(), RLock.acquire(), Condition.wait()等)的允许最大的超时值,如果使用的timeout参数大于这个最大值,就会发生OverflowError |
多线程的同步原语如下:
acquire() 和 release() ,来控制共享数据的读写权限。wait() 用来等待进程, notify_all() 用来通知所有等待此条件的进程。Event 对象有两个方法, set() 和 clear() ,来管理自己内部的变量。同步原语适用范围:
Lock用于对互斥操作(单一资源,全局变量)
RLock与Lock类似,区别仅在与RLock在同一个线程可以多次获取
Semaphone/BounderSemaphone用于对多个资源的申请使用, 如果BounderSemaphone(1)则==Lock()
Condition用于在等待某种事情发生
Event实际上是对Condition的一种操作简化包装,也更符合事件驱动的概念。
Barrier类是设置了一个线程数量障碍,当等待的线程到达了这个数量就会唤醒所有的等待线程。
1.多线程的基本用法
Thread类是可以单独控制和运行的线程,可以通过传递一个可调用对象给构造器,或者重写子类的run()方法来指定线程的运作。线程对象被创建,就必须通过start()方法来开始运作,此时会调用其run()方法,线程就激活了。直到run()方法终止,线程就停止。
其他线程可以调用本线程的join()方法,此时调用本线程join()方法的线程会阻塞,等待本线程执行结束退出,再继续调用线程的后续执行。
线程也可以标识为daemon线程,在Python程序退出时,daemon线程仍然保留,知道关机时才会退出。
还有一种main线程,即开始运行Python程序的线程,为非daemon线程。
还有dummy线程,这种线程是在threading module之外开启,比如通过调用的C代码创建的线程。
| 类及方法 | 详细说明 |
|---|---|
| Thread类 | class threading.Thread(group=None,target=None,name=None,args=(),kwargs={},*,daemon=None),类构造器,group表示线程组,目前不支持该功能,用于后续扩展。target是可以被run()方法调用的对象。name是线程名称。args是参数tuple,用于被target调用。kwargs是关键字参数dictionary,用于被target调用。daemon表明线程是否为daemon类别。在Thread子类重写构造器时,必须首先调用Thread.init() |
| start() | 开始线程的生命周期,该方法会安排run()方法的调用,如果调用start()多次,会发生RuntimeError |
| run() | 线程的生命周期-activity |
| join(timeout=None) | 等待直到线程终止。如果timeout非零,其值为浮点数,要判断join()是否超时,需要使用is_alive()方法看,如果在调用了join()方法后再调用同一线程的is_alive()方法,如果还是alive的,说明join()超时了。如果timeout为None,则调用者会一直阻塞直到被调用join()方法的线程终止。一个线程的join()可被多次调用 |
| getName() | 获取线程名 |
| setName() | 设置线程名 |
| ident | 线程idnetifier,线程是否已经启动,未启动会返回一个非零整数; |
| is_alive() | 判断线程是否alive,主要是看run()是否结束 |
| daemon | daemon线程标志 |
| isDaemon | 判断是否daemon线程 |
| setDaemon | 设置为daemon线程 |
用法一:
创建一个threading.Thread对象,在它的初始化函数(__init__)中将可调用对象作为参数传入,然后使用start()方法启动线程。
import threading
import time
def music(data):
print("bengin listen music: {}".format(time.ctime()))
time.sleep(1)
print(str(data))
print("music end: {}".format(time.ctime()))
def movie(data):
print("bengin look movie: {}".format(time.ctime()))
time.sleep(3)
print(str(data))
print("movie end: {}".format(time.ctime()))
th1 = threading.Thread(target=music, args=("love.mp3",)) ##创建线程
th1.start() ##启动线程
th2 = threading.Thread(target=movie, args=("Anit.avi",))
th2.start()
#输出如下:
bengin listen music: Thu Oct 11 21:35:40 2018
bengin look movie: Thu Oct 11 21:35:40 2018
love.mp3
music end: Thu Oct 11 21:35:41 2018
Anit.avi
movie end: Thu Oct 11 21:35:43 2018从以上输出可以看到,两个线程各自独立运行之后分别结束。彼此互补干扰。
用法二:
通过继承Thread类,重写它的run方法。
import threading
import time
class MultipleThreading(threading.Thread):
def __init__(self, func, args=(), kwargs=None):
threading.Thread.__init__(self)
self.func = func
self.args = args
if kwargs is None:
kwargs = {}
self.kwargs = kwargs
def run(self): ##重写run()方法
print('func_name is: {}'.format(self.func.__name__))
return self.func(*self.args, **self.kwargs)
def music(data):
print("bengin listen music: {}".format(time.ctime()))
time.sleep(2)
print(str(data))
print("music end: {}".format(time.ctime()))
def movie(data):
print("bengin look movie: {}".format(time.ctime()))
time.sleep(5)
print(str(data))
print("movie end: {}".format(time.ctime()))
th1 = MultipleThreading(music, ("love.mp3",))
th2 = MultipleThreading(movie, ("Anit.avi",))
th1.start()
th2.start()threading.Thread的其他实例方法:
(1)join()方法
join()方法会阻塞主线程,当启动线程之后,只有线程全部结束,主线程才会继续执行。
没使用join()方法时:
import threading
import time
def music(data):
print("bengin listen music: {}".format(time.ctime()))
time.sleep(2)
print(str(data))
print("music end: {}".format(time.ctime()))
def movie(data):
print("bengin look movie: {}".format(time.ctime()))
time.sleep(5)
print(str(data))
print("movie end: {}".format(time.ctime()))
thread_list = []
th1 = threading.Thread(target=music, args=("love.mp3",))
th2 = threading.Thread(target=movie, args=("Anit.avi",))
th1.start()
time.sleep(1)
th2.start()
print("main thread continue: {}".format(time.ctime()))
##输出如下:
bengin listen music: Thu Oct 11 22:26:51 2018
bengin look movie: Thu Oct 11 22:26:52 2018
main thread continue: Thu Oct 11 22:26:52 2018 ##没有使用join方法时,线程执行不会block主线程
love.mp3
music end: Thu Oct 11 22:26:53 2018
Anit.avi
movie end: Thu Oct 11 22:26:57 2018
使用join()方法,线程会阻塞主线程
import threading
import time
def music(data):
print("bengin listen music: {}".format(time.ctime()))
time.sleep(2)
print(str(data))
print("music end: {}".format(time.ctime()))
def movie(data):
print("bengin look movie: {}".format(time.ctime()))
time.sleep(5)
print(str(data))
print("movie end: {}".format(time.ctime()))
thread_list = []
th1 = threading.Thread(target=music, args=("love.mp3",))
th2 = threading.Thread(target=movie, args=("Anit.avi",))
thread_list.append(th1)
thread_list.append(th2)
for th in thread_list:
th.start()
th.join()
print("main thread continue: {}".format(time.ctime()))
##输出如下:
bengin listen music: Thu Oct 11 22:31:33 2018
love.mp3
music end: Thu Oct 11 22:31:35 2018
bengin look movie: Thu Oct 11 22:31:35 2018
Anit.avi
movie end: Thu Oct 11 22:31:40 2018
main thread continue: Thu Oct 11 22:31:40 2018 ##线程全部结束之后才能继续主线程
(2)setDaemon()方法
使用setDaemon()方法设置线程为守护线程,就是子线程,跟着主线程一起退出。
注意:setDaemon()方法一定在start之前设置,否则会报错。import threading
import time
def music(data):
print("bengin listen music: {}".format(time.ctime()))
time.sleep(2)
print(str(data))
print("music end: {}".format(time.ctime()))
def movie(data):
print("bengin look movie: {}".format(time.ctime()))
time.sleep(5)
print(str(data))
print("movie end: {}".format(time.ctime()))
thread_list = []
th1 = threading.Thread(target=music, args=("love.mp3",))
th2 = threading.Thread(target=movie, args=("Anit.avi",))
thread_list.append(th1)
thread_list.append(th2)
for th in thread_list:
th.setDaemon(True)
th.start()
print("main thread continue: {}".format(time.ctime()))
##输出:
bengin listen music: Thu Oct 11 22:36:13 2018
bengin look movie: Thu Oct 11 22:36:13 2018
main thread continue: Thu Oct 11 22:36:13 2018 ##线程任务还没完成,但是会随着主线程结束而同时结束2, 多线程Lock/RLock数据同步
竞争条件最简单的解决方法是使用锁。锁的操作非常简单,当一个线程需要访问部分共享内存时,它必须先获得锁才能访问。此线程对这部分共享资源使用完成之后,该线程必须释放锁,然后其他线程就可以拿到这个锁并访问这部分资源了。
Python线程同步有两种锁,lock和Rlock。两种锁有细微的区别。
Rlock,其实叫做“Reentrant Lock”,就是可以重复进入的锁,也叫做“递归锁”。这种锁对比Lock有是三个特点:1. 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;2. 同一线程可以多次拿到该锁,即可以acquire多次;3. acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked)。
lock.aquire()是请求锁,当当前的锁事锁定状态的时候,则lock.aquire()则会阻塞等待锁释放。
因此如果我们写了两个lock.aquire()则会产生死锁。第二个lock.aquire()会永远等待在那里。
使用RLock则不会有这种情况。RLock一个门支持多个锁,上多少把锁,就得释放多少次。
锁的状态:
acquire() 和 release()需要遵循以下规则:
acquire() 将状态改为lockedacquire() 会被block直到另一线程调用 release() 释放锁release() 将导致 RuntimError 异常release() 将状态改为unlocked(1)使用lock进行线程同步
当需要使用资源的时候,调用 acquire() 拿到锁(如果锁暂时不可用,会一直等待直到拿到),最后调用 release():
import threading,time
shared_data = 0
shared_lock = threading.Lock()
CNT = 10
def increase_data_with_lock():
global shared_data
shared_lock.acquire()
for i in range(CNT):
shared_data = shared_data + 1
time.sleep(0.1)
print("increase_data, current: {}".format(shared_data))
shared_lock.release()
def decrease_data_with_lock():
global shared_data
shared_lock.acquire()
for i in range(CNT):
shared_data = shared_data - 1
time.sleep(0.2)
print("decrease_data, current: {}".format(shared_data))
shared_lock.release()
thread_1 = threading.Thread(target=increase_data_with_lock)
thread_2 = threading.Thread(target=decrease_data_with_lock)
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print("result is: {}".format(shared_data))
##输出结果
increase_data, current: 1
increase_data, current: 2
increase_data, current: 3
decrease_data, current: 2
decrease_data, current: 1
decrease_data, current: 0
result with lock is: 0(2)使用RLock同步线程资源
如果你想让只有拿到锁的线程才能释放该锁,那么应该使用 RLock() 对象。和 Lock() 对象一样, RLock() 对象有两个方法: acquire() 和 release() 。当你需要在类外面保证线程安全,又要在类内使用同样方法的时候 RLock() 就很实用了。
RLock也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的琐。
有Lock了为什么还需要RLock呢?可重入锁最大的作用是在需要重复获得锁的情况下(如:递归调用)避免死锁。
RLock对象是Lock对象的一个变种,但是它是一种可重入的Lock,其内部维护着一个Lock对象,还有一个计数器。
import threading
class Box(object):
lock = threading.RLock()
def __init__(self):
self.total_items = 0
def execute(self, n):
self.lock.acquire()
self.total_items += n
self.lock.release()
def add(self):
self.lock.acquire()
self.execute(1)
# self.lock.release()
def remove(self):
self.lock.acquire()
self.execute(-1)
# self.lock.release()
def adder(box, items):
while items > 0:
box.add()
items -= 1
def remover(box, items):
while items > 0:
box.remove()
items -= 1
if __name__ == "__main__":
items = 5
print("putting %s items in the box " % items)
box = Box()
t1 = threading.Thread(target=adder, args=(box, items))
t2 = threading.Thread(target=remover, args=(box, items))
t1.start()
t2.start()
t1.join()
t2.join()
print("%s items still remain in the box " % box.total_items)
##输出:
putting 5 items in the box
0 items still remain in the box 以上例子用如果使用Lock(), 应为不能不能多次acquire(), 程序将会死锁不能正常运行。
必须使用RLock场景:
场景一:线程安全的访问一个class,在一个class 中的某个需要获取锁的方法类中访问了又访问了该类的其他需要获取锁方法。
示例如下:
import threading
class Box(object):
def __init__(self):
self.a = 1
self.b = 1
self.total_items = self.a + self.b
self.lock = threading.RLock()
def add_a(self):
with self.lock:
self.a +=1
return self.a
def add_b(self):
with self.lock:
self.b += self.a + self.b
return self.b
def add_a_with_b(self):
with self.lock:
aa = self.add_a()
bb = self.add_b()
return aa+bb
def additional(box):
box.add_a_with_b()
if __name__ == "__main__":
box = Box()
t = threading.Thread(target=additional, args=(box, ))
t.start()
print("%s items still remain in the box " % box.total_items)场景二:递归函数中需要获取锁时
lock = threading.RLock()
def factorial(n):
with lock:
if n == 0 or n == 1:
return 1
else:
data = n * factorial(n-1)
print(data)
return data
if __name__ == "__main__":
t = threading.Thread(target=factorial, args=(5, ))
t.start()
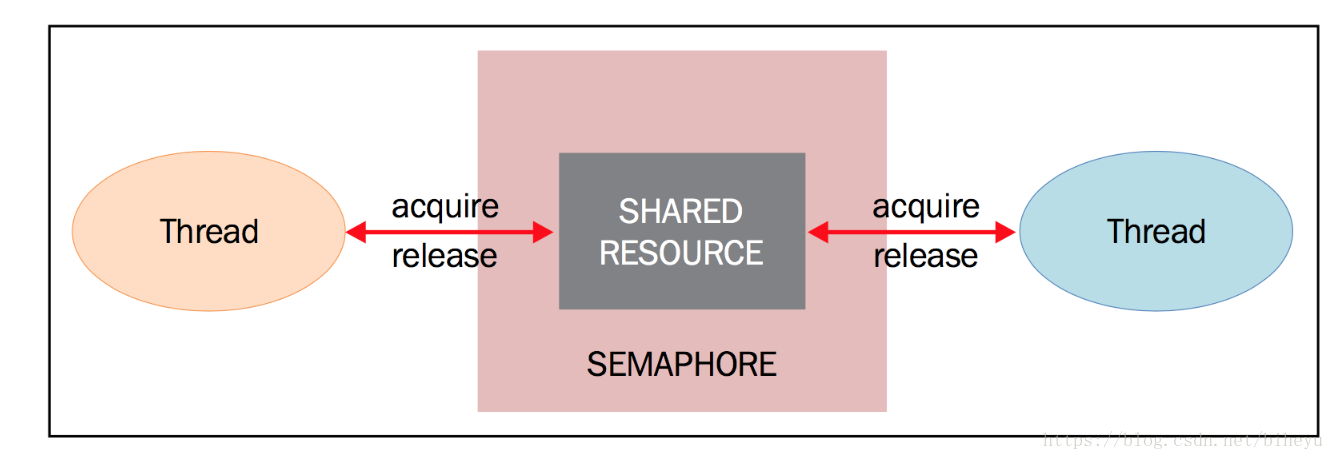
t.join()3,多线程使用 Semaphore(信号量)同步数据
Semaphore是信号量的意思。Semaphore跟Lock类似,但是Semaphore可以允许指定最多多少个进程访问资源。就像该资源有多个门,每个门一把锁。一个进程访问了资源,锁了门,还有其他门可以使用。但是如果所有门都被使用了,那么就得等待有进程出来释放锁才可以。
在Python中存在两种Semphore,一种就是纯粹的Semphore,还有一种就是BoundedSemaphore。
Semphore和BoundedSemaphore主要区别:
Semaphore跟Lock主要区别:
信号量的操作有两个函数,即 acquire() 和 release() ,解释如下:
acquire() ,此操作减少信号量的内部变量, 如果此变量的值非负,那么分配该资源的权限。如果是负值,那么线程被挂起,直到有其他的线程释放资源。release() 释放。这样,信号量的内部变量增加,在信号量等待队列中排在最前面的线程会拿到共享资源的权限。信号量死锁:
虽然表面上看信号量机制没什么明显的问题,如果信号量的等待和通知操作都是原子的,确实没什么问题。但如果不是,或者两个操作有一个终止了,就会导致糟糕的情况。
举个例子,假设有两个并发的线程,都在等待一个信号量,目前信号量的内部值为1。假设第线程A将信号量的值从1减到0,这时候控制权切换到了线程B,线程B将信号量的值从0减到-1,并且在这里被挂起等待,这时控制权回到线程A,信号量已经成为了负值,于是第一个线程也在等待。这样的话,尽管当时的信号量是可以让线程访问资源的,但是因为非原子操作导致了所有的线程都在等待状态。
import threading
import random
semaphore = threading.Semaphore(0) ##信号量个数,默认值为1。
def producer():
global item
item = random.randrange(1, 1000)
semaphore.release() ## 信号量的 release() 可以提高计数器然后通知其他的线程, 信号量个数增加+1
print("producer notify : produced item number %s" % item)
def consumer():
print("consumer is waiting....")
global item
semaphore.acquire(timeout=3) ##信号量个数减1
# 如果信号量的计数器到了0,就会阻塞 acquire() 方法,
# 直到得到另一个线程的通知。如果信号量的计数器大于0,就会对这个值-1然后分配资源。
print("consume notify : consume item number %s" % item)
if __name__ == "__main__":
for i in range(3):
th1 = threading.Thread(target=producer)
th2 = threading.Thread(target=consumer)
th1.start()
th2.start()
th1.join()
th2.join()
print("teminated")
##输出如下:
producer notify : produced item number 156
consumer is waiting....
consume notify : consume item number 156
producer notify : produced item number 452
consumer is waiting....
consume notify : consume item number 452
producer notify : produced item number 424
consumer is waiting....
consume notify : consume item number 424
teminatedBoundedSemaphore简单用法示例:import threading
semaphore = threading.BoundedSemaphore(1)
def func(num):
semaphore.acquire()
print("the number is: {}".format(num))
semaphore.release()
# 再次释放信号量,信号量加一,这是超过限定的信号量数目,这时会报错ValueError: Semaphore released too many times
semaphore.release()
if __name__ == "__main__":
num = 12
th1 = threading.Thread(target=func, args=(num,))
th1.start()
th1.join()Semaphore可以用来限制资源并发访问数,常见使用场景如下:
场景:主要用途,用来控制线程的并发量,或者连接池,线程池,MySQL的连接数
import threading
import time
def showfun(n):
print("%s start -- %d"%(time.ctime(),n))
time.sleep(2)
print ("%s end -- %d" % (time.ctime(), n))
semaphore.release()
if __name__ == "__main__":
max_conn = 2
semaphore = threading.BoundedSemaphore(max_conn)
thread_list = []
for i in range(4):
semaphore.acquire()
th = threading.Thread(target=showfun, args=(i, ))
thread_list.append(th)
print(threading.active_count())
th.start()
##输出:
1
Sun Oct 14 20:47:44 2018 start -- 0
2
Sun Oct 14 20:47:44 2018 start -- 1
Sun Oct 14 20:47:46 2018 end -- 0
Sun Oct 14 20:47:46 2018 end -- 1
1
Sun Oct 14 20:47:46 2018 start -- 2
2
Sun Oct 14 20:47:46 2018 start -- 3
Sun Oct 14 20:47:48 2018 end -- 2
Sun Oct 14 20:47:48 2018 end -- 3最大线程数限制为2,从输出可以看到0/1结束之后2/3才能获取资源执行, active线程数最大为2个。
4,使用条件condition控制线程数据同步
condition指的是应用程序状态的改变。这是另一种同步机制,其中某些线程在等待某一条件发生,其他的线程会在该条件发生的时候进行通知。一旦条件发生,线程会拿到共享资源的唯一权限。
Condition(条件变量)通常与一个锁关联。需要在多个Contidion中共享一个锁时,可以传递一个Lock/RLock实例给构造方法,否则它将自己生成一个RLock实例。
可以认为,除了Lock带有的锁定池外,Condition还包含一个等待池,池中的线程处于状态图中的等待阻塞状态,直到另一个线程调用notify()/notifyAll()通知;得到通知后线程进入锁定池等待锁定。
Condition方法:
| 类与方法 | 详细说明 |
|---|---|
| threading.Condition | class threading.Condition(lock=None),用于实现条件变量对象,允许多个线程wait一个条件变量,直到被一个线程notify。如果lock参数非None,必须是从外部传入的Lock或RLock。如果lock参数是None,会新建一个RLock |
| acquire(*args) | acquire上面提到的传入的或新建的lock |
| release() | release上面提到的传入的或新建的lock |
| wait(timeout=None) | 等待notify或到timeout发生,其实就是相当于acquire()一个lock,然后等待有人将其release()。线程挂起,直到收到一个notify通知或者超时(可选的,浮点数,单位是秒s)才会被唤醒继续运行。wait()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。 |
| wait_for(predicate, timeout=None) | 等待直到condition为True,predicate是可调用的且其结果是boolean值 |
| notify(n=1) | 默认唤醒一个等待condition的线程。这个方法可以唤醒最多n个等待condition的线程。通知其他线程,那些挂起的线程接到这个通知之后会开始运行,默认是通知一个正等待该condition的线程,最多则唤醒n个等待的线程。notify()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。notify()不会主动释放Lock。 |
| notify_all() | 唤醒所有等待condition的线程。如果wait状态线程比较多,notifyAll的作用就是通知所有线程 |
例子如下:
from threading import Thread, Condition
import random
items = []
cond = Condition()
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
def produce(self):
global cond
global items
cond.acquire()
if len(items) >= 2:
print("items is 2, wait consume")
cond.notify() ##当items数量不小于2时,通知consumer消费,线程阻塞
cond.wait()
data = random.randrange(1, 1000)
items.append(data)
print("produce data is: {}".format(data))
print("increase items lenth to: {}".format(len(items)))
cond.release()
def run(self):
for i in range(5):
self.produce()
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
def consume(self):
global cond
global items
cond.acquire()
if len(items) <= 0: ##当items数量小于等于0时,通知producer产生数据,线程阻塞
print("items is 0, wait producer")
cond.notify()
cond.wait()
data = items.pop()
print("consume data is: {}".format(data))
print("decrease items lenth to: {}".format(len(items)))
cond.release()
def run(self):
for i in range(5):
self.consume()
if __name__ == "__main__":
producer = Producer()
consumer = Consumer()
producer.start()
consumer.start()
producer.join()
consumer.join()
##输出如下:
produce data is: 558
increase items lenth to: 1
produce data is: 889
increase items lenth to: 2
items is 2, wait consume
consume data is: 889
decrease items lenth to: 1
consume data is: 558
decrease items lenth to: 0
items is 0, wait producer
produce data is: 47
increase items lenth to: 1
produce data is: 74
increase items lenth to: 2
items is 2, wait consume
......5, 使用事件Event控制线程同步
Event是线程通信最为简单的机制,一个线程抛出一个信号,另外线程等待这个信号。
事件是线程之间用于通讯的对象。有的线程等待信号,有的线程发出信号。基本上事件对象都会维护一个内部变量,可以通过 set() 方法设置为 true ,也可以通过 clear() 方法设置为 false。 wait() 方法将会阻塞线程,直到内部变量为 true 。
Event(事件)处理的机制:全局定义了一个内置标志Flag,如果Flag值为 False,那么当程序执行 event.wait方法时就会阻塞,如果Flag值为True,那么event.wait 方法时便不再阻塞。
Event其实就是一个简化版的 Condition。Event没有锁,无法使线程进入同步阻塞状态。当多个线程监听某一个触发条件时,如果全部线程都依赖这个触发条件,可以使用Event;如果需要精确控制某些线程被触发,则需要使用Condition。
Event()方法如下:
| 类与方法 | 详细说明 |
|---|---|
| Event | class threading.Event。管理一个内部flag(True or False) |
| is_set() | 判断内部flag是否True |
| set() | 将内部flag设置为True,并通知所有处于等待阻塞状态的线程恢复运行状态。 |
| clear() | 将内部flag设置为False |
| wait(timeout=None) | 阻塞直到内部flag为True,或者timeout时间到。如果标志为True将立即返回,否则阻塞线程至等待阻塞状态,等待其他线程调用set()。 |
示例:交通灯控制车辆,绿灯行红灯停
from threading import Thread, Event
import time
class TrafficLight(Thread):
def __init__(self, event, green_cnt, red_cnt):
super(TrafficLight, self).__init__()
self.event = event
self.green_cnt = green_cnt
self.red_cnt = red_cnt
self.interval = self.green_cnt + self.red_cnt
def run(self):
count = 0
self.event.set() ##绿灯亮
while True:
if count <= self.green_cnt:
self.event.set() ##绿灯亮
print("绿灯亮了 {}s,请通行".format(count))
elif self.green_cnt < count <= self.interval:
self.event.clear() ##红灯亮
print("红灯亮 {}s,车辆禁止通行".format(count))
elif count > self.interval:
self.event.set() ##绿灯亮
count = 0
print("绿灯亮了 {}s,请通行".format(count))
time.sleep(1)
count = count + 1
class Car(Thread):
def __init__(self, event, car_name):
super(Car, self).__init__()
self.event = event
self.car_name = car_name
def run(self):
while True:
if self.event.is_set(): # 有标志位,代表是绿灯
print("{} is runnning".format(self.car_name))
time.sleep(1)
else: # 如果不是绿灯就代表红灯
self.event.wait() ##阻塞,直到event被set才继续执行
print("{} is waiting".format(self.car_name))
if __name__ == "__main__":
event = Event()
thread_list = []
car_list = ["BMW", "Ford", "BenZ"]
thread_light = TrafficLight(event, 1, 2)
thread_list.append(thread_light)
for car_name in car_list:
car_th = Car(event, car_name) ##所有的车收到event事件同时开始执行/阻塞
thread_list.append(car_th)
for th in thread_list:
th.start()
for th in thread_list:
th.join()
##输出如下:
绿灯亮了 0s,请通行
BMW is runnning
Ford is runnning
BenZ is runnning
BMW is runnning
Ford is runnning
绿灯亮了 1s,请通行
BenZ is runnning
BMW is runnning
红灯亮 2s,车辆禁止通行
红灯亮 3s,车辆禁止通行6, 使用栅栏Barrier控制数据同步
Barrier常用来实现这样的线程同步,多个线程运行到某个时间点以后每个线程都需要等着其他线程都准备好以后再同时进行下一步工作。类似于赛马时需要先用栅栏拦住,每个试图穿过栅栏的选手都需要明确说明自己准备好了,当所有选手都表示准备好以后,栅栏打开,所有选手同时冲出栅栏。
Barriers是个简单的同步原语,可以用户多个线程之间的相互等待。每个线程都调用wait()方法,然后阻塞,直到所有线程调用了wait(),然后所有线程同时开始运行。
| 类和方法 | 详细说明 |
|---|---|
| Barrier构造函数 | class threading.Barrier(parties, action=None, timeout=None)
|
| wait(timeout=None) | 表示线程就位,返回值是一个0到parties-1之间的整数, 每条线程都不一样,这个值可以用作挑选一条线程做些清扫工作,另外如果你在 构造函数里设置了action的话,其中一个线程在释放之前将会调用它。如果调用 出错的话,会让栅栏进入broken状态,超时同样也会进入broken状态,如果栅栏 在处于broke状态的时候调用reset函数,会抛出一个BrokenBarrierError异常。 |
| reset() | 本方法将栅栏置为初始状态,即empty状态。所有已经在等待的线程 都会接收到BrokenBarrierError异常,注意当有其他处于unknown状态的线程时, 调用此方法将可能获取到额外的访问。因此如果一个栅栏进入了broken状态, 最好是放弃他并新建一个栅栏,而不是调用reset方法。 |
| abort() | 将栅栏置为broken状态。本方法将使所有正在等待或将要调用 wait()方法的线程收到BrokenBarrierError异常。本方法的使用情景为,比如: 有一条线程需要abort(),又不想给其他线程造成死锁的状态,或许设定 timeout参数要比使用本方法更可靠。 |
| parties | 将要使用本 barrier 的线程的数量 |
| n_waiting | 正在等待本 barrier 的线程的数量 |
| broken | 布尔值,表明barrier是否broken |
常用场景:
并发初始化,所有线程都必须初始化完成后,才能继续工作,例如运行前加载数据,检查,如果这些工作没完成就不能正常工作运行。例如3个线程分别做不同的数据准备工作,必须等到数据都准备好以后才能开始并发测试。
import threading
from threading import Barrier, Thread
def prepare_user_data(user):
print("user {} is ready".format(user))
def prepare_car_data(car):
print("car {} is ready".format(car))
def ready():
print("{} 数据准备好了".format(threading.current_thread().name))
class RunThreading(Thread):
def __init__(self, barries, target=None, args=(), kwargs={}):
super(RunThreading, self).__init__(target=None, args=args, kwargs=kwargs)
self._barries = barries
self.func = target
self.args = args
self._kwargs = kwargs
def run(self):
print("data prepare......")
data = self.func(*self.args, **self._kwargs)
self._barries.wait()
return data
if __name__ == "__main__":
data = {"Leo": "沪111111", "Bruce": "沪222222", "Frank": "沪333333"}
cnt = len(data)
print("并发测试数据准备...")
barrier = Barrier(cnt, action=ready, timeout=10)
thread_list = []
for k, v in data.items():
thread_user = RunThreading(barrier, target=prepare_user_data, args=(k,))
thread_car = RunThreading(barrier, target=prepare_car_data, args=(v,))
thread_list.append(thread_user)
thread_list.append(thread_car)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
if barrier.broken:
print("数据准备出异常了,请重新准备数据")
运行结果:
并发测试数据准备...
data prepare......
user Leo is ready
data prepare......
car 沪111111 is ready
data prepare......
user Bruce is ready
Thread-3 数据准备好了
data prepare......
car 沪222222 is ready
data prepare......
user Frank is ready
data prepare......
car 沪333333 is ready
Thread-6 数据准备好了7,使用Queue进行线程间数据通讯
线程之间如果要共享资源或数据的时候,可能变的非常复杂。Python的threading模块提供了很多同步原语,包括信号量,条件变量,事件和锁。如果可以使用这些原语的话,应该优先考虑使用这些,而不是使用queue(队列)模块。
Queue提供的一个线程安全的多生产者,多消费者队列,自带锁, 多线程并发数据交换必备。
内置三种类型的队列:
Queue:FIFO(先进先出);LifoQueue:LIFO(后进先出);PriorityQueue:优先级最小的先出;构造函数一样,都是只有一个maxsize=0,用于设置队列的容量,
如果设置的maxsize小于1,则表示队列的长度无限长。
两个异常:
相关函数
下面以生产者/消费者模型示例:
from threading import Thread
from queue import Queue
import random, time
class Producer(Thread):
def __init__(self, queue):
super(Producer, self).__init__()
self.queue = queue
def run(self):
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item) ##插入队列
print('Producer notify: item N° %d appended to queue by %s' % (item, self.name))
time.sleep(1)
class Consumer(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self):
while True:
item = self.queue.get() ##从队列中取出数据
print('Consumer notify : %d popped from queue by %s' % (item, self.name))
self.queue.task_done()
if __name__ == '__main__':
queue = Queue()
thread_list = []
t1 = Producer(queue)
t2 = Consumer(queue)
t3 = Consumer(queue)
thread_list.append(t1)
thread_list.append(t2)
thread_list.append(t3)
for th in thread_list:
th.start()
for th in thread_list:
th.join()生产者使用 Queue.put(item [,block[, timeout]]) 来往queue中插入数据。Queue是同步的,在插入数据之前内部有一个内置的锁机制。
可能发生两种情况:
block 为 True , timeout 为 None (这也是默认的选项,本例中使用默认选项),那么可能会阻塞掉,直到出现可用的位置。如果 timeout 是正整数,那么阻塞直到这个时间,就会抛出一个异常。block 为 False ,如果队列有闲置那么会立即插入,否则就立即抛出异常( timeout 将会被忽略)。本例中, put() 检查队列是否已满,然后调用 wait() 开始等待。消费者从队列中取出数据,然后用 task_done() 方法将其标为任务已处理。
消费者使用 Queue.get([block[, timeout]]) 从队列中取回数据,queue内部也会经过锁的处理。如果队列为空,消费者阻塞。
8,多线程数据隔离(Thread-Local Data)
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
这样一个场景:
依据以上需求,我们先实现第一个简单版本:
import threading
import time
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
def do_task1(std):
print("thread name: {}, get data {}".format(threading.current_thread().name, std.name))
def do_task2(std):
print("thread name: {}, get data {}".format(threading.current_thread().name, std.name))
def process_thread(name, age):
std = Student(name, age)
do_task1(std)
do_task2(std)
t1 = threading.Thread(target=process_thread, args=('Alice', 21), name='Thread-A')
t2 = threading.Thread(target=process_thread, args=('Bob', 22), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()每个函数一层一层调用都传参数std实例,代码显得很丑陋冗余。如果直接用全局变量也不行。因为对每个线程来说,Student实例都不同,不能共享。
我们可以采用一个全局字典,字典中分别报错线程以及对应的Student实例。代码实现如下:
import threading
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
####使用全局dict存放所有的Student对象,然后以thread自身作为key获得线程对应的Student对象
global_dict = {}
def process_thread(name, age):
std = Student(name, age)
global_dict[threading.currentThread()] = std # 把std放到全局变量global_dict中:
do_task1()
do_task2()
def do_task1():
std = global_dict[threading.currentThread()] # 不传入std,而是根据当前线程查找:
print("thread name: {}, get data {}".format(threading.current_thread().name, std.name))
def do_task2():
std = global_dict[threading.currentThread()] # 不传入std,而是根据当前线程查找:
print("thread name: {}, get data {}".format(threading.current_thread().name, std.age))
t1 = threading.Thread(target=process_thread, args=('Alice', 21), name='Thread-A')
t2 = threading.Thread(target=process_thread, args=('Bob', 22), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
使用global_dict字典避免了每个函数都需要传参std对象,但是Python中有一个更好的办法来解决这个问题
threading.local()实例化一个全局对象,不同线程可以往里面保存数据, 互不干扰。实现原理是该对象内部用一个大字典,保存键值为两个 弱引用对象,{线程对象,字典对象},通过current_thread()获得当前 的线程对象,作为key以此拿到对应的字典象。
代码实现:
import threading
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
local_school = threading.local()
def do_task1():
print("thread name: {}, get data {}".format(threading.current_thread().name, local_school.std.name))
def do_task2():
print("thread name: {}, get data {}".format(threading.current_thread().name, local_school.std.age))
def process_thread(name, age):
std = Student(name, age)
local_school.std = std
do_task1()
do_task2()
t1 = threading.Thread(target=process_thread, args=('Alice', 21), name='Thread-A')
t2 = threading.Thread(target=process_thread, args=('Bob', 22), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()运行结果:
thread name: Thread-A, get data Alice
thread name: Thread-A, get data 21
thread name: Thread-B, get data Bob
thread name: Thread-B, get data 22全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
常见错误:
主线程中使用threading.local定义本地变量,在子线程中访问主线程的本地变量
错误用例如下:
主线程中使用threading.local定义本地变量var,var在主线程中是独有的,子线程中就访问不到主线程的var的属性。
import threading
global_var = '123'
local_thread = threading.local()
local_thread.var = 'hello' ##主线程中定义本地属性var
print("global vars: {} {}".format(local_thread, local_thread.var))
def do_task1():
print(global_var)
print(local_thread)
print(local_thread.var) ##子线程访问不到
def do_task2():
local_thread.name = 'Bob' ##每个子线程使用全局对象local_thread,但每个线程定义的属性local_thread.name是该线程独有的。
print(global_var)
print(local_thread)
print(local_thread.name)
t1 = threading.Thread(target=do_task1)
t2 = threading.Thread(target=do_task2)
t1.start()
t2.start()运行结果:
123
<_thread._local object at 0x10412d8e0>
Bob
Exception in thread Thread-1:
Traceback (most recent call last):
AttributeError: '_thread._local' object has no attribute 'var'local_thread全局对象对主线程和子线程都是可以使用的,但是主线程定义了local_thread的属性var仅仅属于主线程所有,子线程在尝试访问属性var时,就相当于访问自己线程内的属性x,而自己线程并没有定义,就会抛出AttributeError异常:'_thread._local' object has no attribute 'var'。
9,定时器Timer
与Thread类似,只是要等待一段时间后才会开始运行,单位秒。
import threading, time
def data_ready():
print("data is ready at {}".format(time.ctime()))
if __name__ == "__main__":
th = threading.Timer(5, data_ready)
th.start()
while threading.active_count() > 1:
print("数据还没ready:{}".format(time.ctime()))
time.sleep(1)运行结果如下:
数据还没ready:Thu Oct 18 11:59:29 2018
数据还没ready:Thu Oct 18 11:59:30 2018
数据还没ready:Thu Oct 18 11:59:31 2018
数据还没ready:Thu Oct 18 11:59:32 2018
数据还没ready:Thu Oct 18 11:59:33 2018
data is ready at Thu Oct 18 11:59:34 201810,线程池
对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控,例如,整站爬虫,假设初始只有一个链接a,那么,这个时候只启动一个线程,运行之后,得到这个链接对应页面上的b,c,d,,,等等新的链接,作为新任务,这个时候,就要为这些新的链接生成新的线程,线程数量暴涨。对于任务数量不端增加的程序,固定线程数量的线程池是必要的。
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
主要函数方法如下:
| ThreadPoolExecutor(max_workers) | 构造函数,传入max_workers参数来设置线程池中最多能同时运行的线程数目。 |
| submit() | 使用 |
| map() | map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。 |
submit()和map()的主要区别:
(1)简单使用:
ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。result()方法可以获取任务的返回值,这个方法是阻塞的。import time
import threading
from concurrent.futures import ThreadPoolExecutor
def data_ready(data):
time.sleep(1)
print("{} execute {} at {}".format(threading.current_thread().getName(), data, time.ctime()))
return "value_"+str(data)
if __name__ == "__main__":
data_list = [1, 2, 3, 4, 5]
max_workers = 3 ##线程个数
with ThreadPoolExecutor(max_workers=max_workers, thread_name_prefix="demo") as executor: ##max_workers参数控制线程个数,
# thread_name_prefix参数指定线程名前缀
task_list = []
for data in data_list:
task = executor.submit(data_ready, data) ##submit每次都需要提交一个目标函数和对应的参数
task_list.append(task)
task_status = task.done() #判断task是否结束
# print(task_tag)
retry_times = 0
while task_status and retry_times < 5:
if not task_status:
print("执行还没在执行中,waiting.....")
time.sleep(1)
retry_times += 1
else:
print("任务结束了,返回值是:{}".format(task.result())) ##返回执行结果
break
for task in task_list:
if task.cancel():
print("cancel成功")
else:
print("已经执行")
with ThreadPoolExecutor(max_workers=max_workers, thread_name_prefix="map_demo") as executor_map:
executor_map.map(data_ready, data_list) ##map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
执行结果:
已经执行
已经执行
已经执行
cancel成功
cancel成功 ##线程池限定线程数为3,此时demo_0/demo_1/demo_2任务已经运行,无法取消。
demo_0 execute 1 at Sun Oct 21 12:18:47 2018
demo_1 execute 2 at Sun Oct 21 12:18:47 2018
demo_2 execute 3 at Sun Oct 21 12:18:47 2018
map_demo_0 execute 1 at Sun Oct 21 12:18:48 2018
map_demo_2 execute 3 at Sun Oct 21 12:18:48 2018
map_demo_1 execute 2 at Sun Oct 21 12:18:48 2018
map_demo_0 execute 4 at Sun Oct 21 12:18:49 2018
map_demo_2 execute 5 at Sun Oct 21 12:18:49 2018(2)使用as_completed()判断线程池任务是否都完成
使用as_completed方法一次取出Pool中所有任务的结果。
示例代码:
import time
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
def data_ready(data):
time.sleep(1)
print("{} execute {} at {}".format(threading.current_thread().getName(), data, time.ctime()))
return "value_"+str(data)
if __name__ == "__main__":
data_list = [1, 2, 3, 4, 5]
max_workers = 3 ##线程个数
with ThreadPoolExecutor(max_workers=max_workers, thread_name_prefix="demo") as executor: ##max_workers参数控制线程个数,
task_list = [executor.submit(data_ready, data) for data in data_list]
for task in as_completed(task_list):
print("task success: {} at {}".format(task.result(), time.ctime()))执行结果:
demo_0 execute 1 at Sun Oct 21 17:03:55 2018
demo_1 execute 2 at Sun Oct 21 17:03:55 2018
demo_2 execute 3 at Sun Oct 21 17:03:55 2018
task success: value_3 at Sun Oct 21 17:03:55 2018
task success: value_2 at Sun Oct 21 17:03:55 2018
task success: value_1 at Sun Oct 21 17:03:55 2018
demo_1 execute 5 at Sun Oct 21 17:03:56 2018
demo_2 execute 4 at Sun Oct 21 17:03:56 2018
task success: value_5 at Sun Oct 21 17:03:56 2018
task success: value_4 at Sun Oct 21 17:03:56 2018as_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。
(3)使用wait()方法让主线程阻塞,直到满足设定的要求
wait(fs, timeout=None, return_when=ALL_COMPLETED)方法接收3个参数,等待的任务序列、超时时间以及等待条件。等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束, 才会继续其他的任务。等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
示例代码:
import time
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed, wait
def data_ready(data):
time.sleep(1)
print("{} execute {} at {}".format(threading.current_thread().getName(), data, time.ctime()))
return "value_"+str(data)
if __name__ == "__main__":
data_list = [1, 2, 3, 4, 5]
max_workers = 3 ##线程个数
with ThreadPoolExecutor(max_workers=max_workers, thread_name_prefix="demo") as executor: ##max_workers参数控制线程个数,
task_list = [executor.submit(data_ready, data) for data in data_list]
wait(task_list, return_when="ALL_COMPLETED") ##所有的任务完成以后再继续往下执行
print("all task is ready")
for task in as_completed(task_list):
print("task success: {} at {}".format(task.result(), time.ctime()))执行结果:
demo_1 execute 2 at Sun Oct 21 17:21:28 2018
demo_0 execute 1 at Sun Oct 21 17:21:28 2018
demo_2 execute 3 at Sun Oct 21 17:21:28 2018
demo_0 execute 4 at Sun Oct 21 17:21:29 2018
demo_1 execute 5 at Sun Oct 21 17:21:29 2018
all task is ready
task success: value_3 at Sun Oct 21 17:21:29 2018
task success: value_1 at Sun Oct 21 17:21:29 2018
task success: value_5 at Sun Oct 21 17:21:29 2018
task success: value_4 at Sun Oct 21 17:21:29 2018
task success: value_2 at Sun Oct 21 17:21:29 2018从执行输出可以看到,5个task全部执行完成以后,才继续了主进程的其他代码。
参考文献:
http://www.voidcn.com/article/p-azgyexlf-bpb.html
https://www.zybuluo.com/coder-pig/note/1092439
https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/chapter2/index.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!