社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
嗷,有段时间(半个月)没写了…上篇博文是说打算写一篇破解bilibili滑块验证码,基本思路都实现了,后来竟然卡在获取不到bilibili的验证码原图(为我的睿智窒息)。一晃而过半个月,补了点前端三大语言基础,趁热打铁,先写一篇爬虫js逆向吧,至于滑块验证码破解待续…
js逆向是做爬虫必要掌握的进阶技巧,如常见post方式data被加密,找出被加密键对值。但是我们掌握js逆向,并不需要对JavaScript有深度了解,只要了解一点(甚至不知道都关系不大),因为主要在于js逆向的思维和逆向过程对js代码很多时候处理只要扣代码执行即可。这里,以简单js逆向百度翻译爬虫为例。
一个简单测试
首先,测试一个简单的百度翻译用例。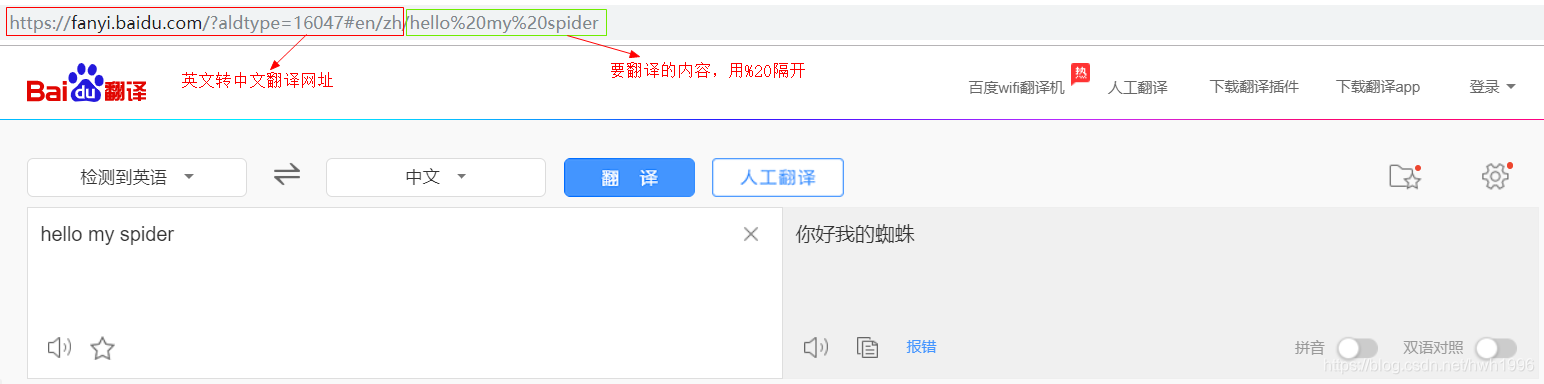
我们知道get方式,url要包含请求的参数数据(在URL中可看到),那么我们简单的get方式可以可以获取到结果吗?返回的又是什么呢?
import requests
# 0.尝试构建URL访问---可行
url = "https://fanyi.baidu.com/?aldtype=16047#en/zh/hello%20my%20spider"
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0"}
response = requests.get(url, headers=headers)
print(response.text)
打印出来是翻译后的网页源码:
当然,我们可以用正则分析出翻译的结果,然后打印出结果。但是这种方式有诸多不便。
%word1%word2..构造URL显然是难以接受的。cn/zh—>zh/cn等,过于复杂。那么,有没有更好的方式呢?
思考更好的方式
不管如何,翻译过程,网站肯定要发送请求,我们可以通过抓包分析,来观察请求进而构造出合适的get或post请求。
正如前所言,登陆时一般是post方式(加密更加安全),要模拟登陆常需要js逆向破解post方式加密的表单数据。这里百度翻译也有其特殊性,因为构造URL过于复杂,让我们不得不观察下它翻译时XHR请求,有没有更好的方式构造。比如,是post方式,其表单项直接含有要翻译内容,构造其它表单项模拟发送请求就可以得到翻译结果。
QWER一套连招进行常规抓包操作: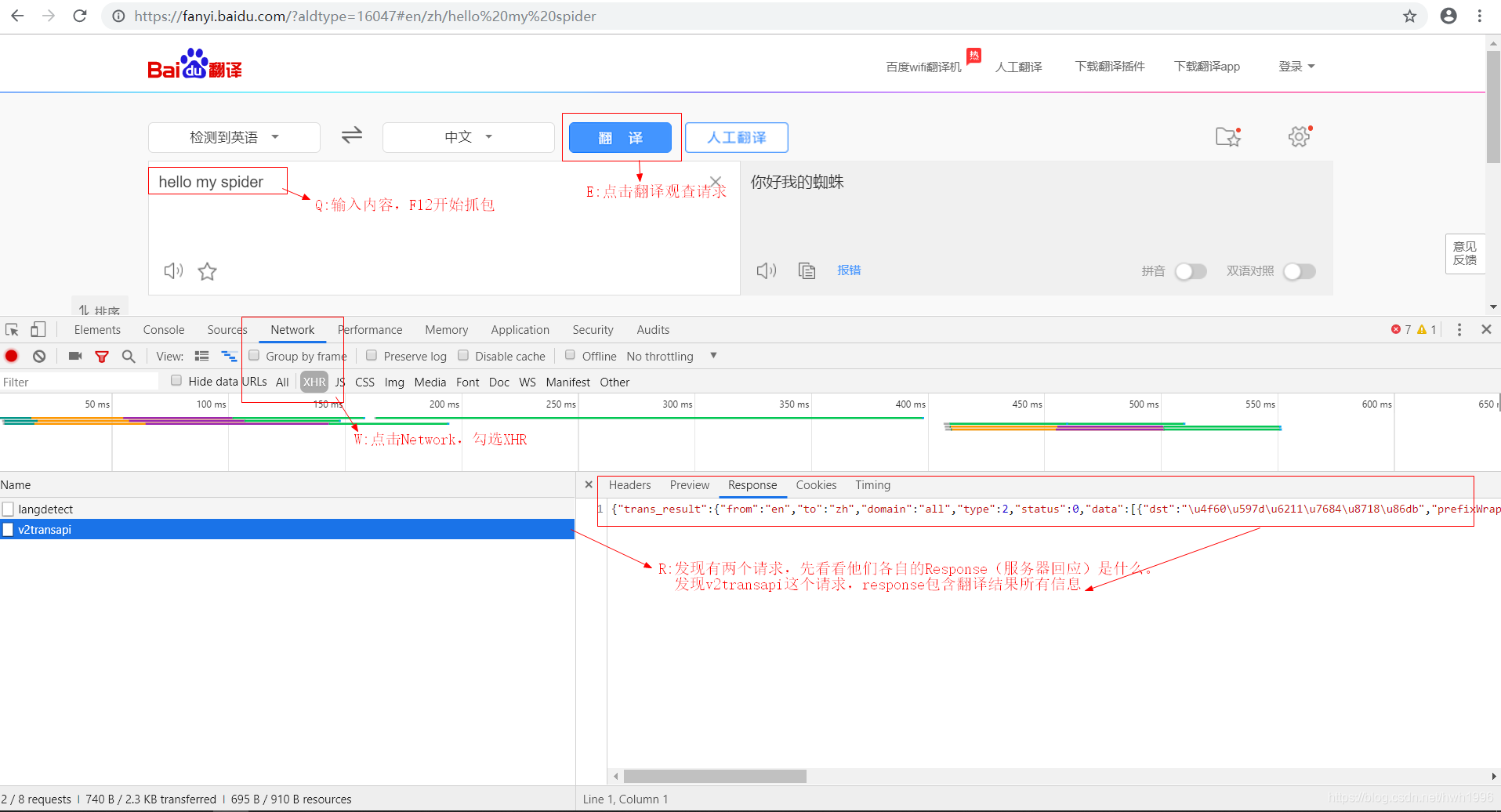
根据上图,不难得知v2transapi这个请求可以得到我们所要的翻译结果,如果对json有所了解的同学,马上就会知道这是json数据格式。当然我们可以选中preview更好的查看返回json格式结果。
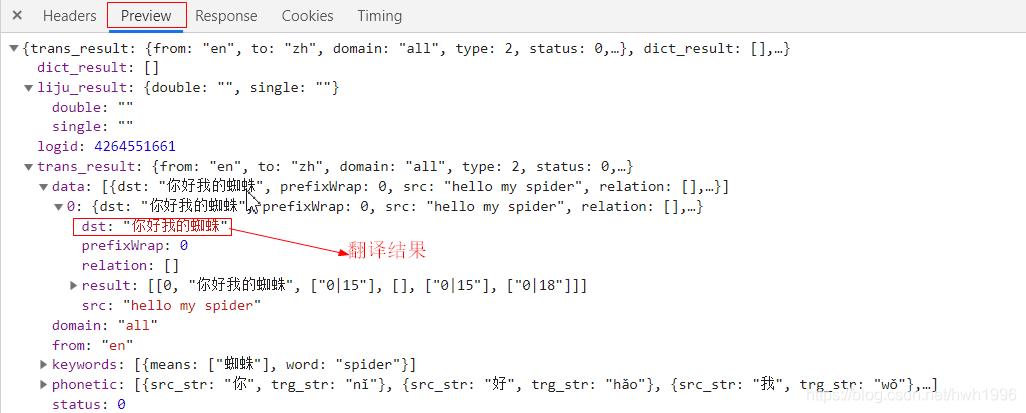
到这里我们便基本已经锁定是哪个请求,也知道返回的结果格式了(方便后面提取数据)。接下来,我们便开始分析它的Headers构造请求。
要构造请求,要分析:请求的URL;是get/post请求;如果是post请求,其表单(data)如何构造?现在,让我们逐步开始分析。
分析URL & 请求方式
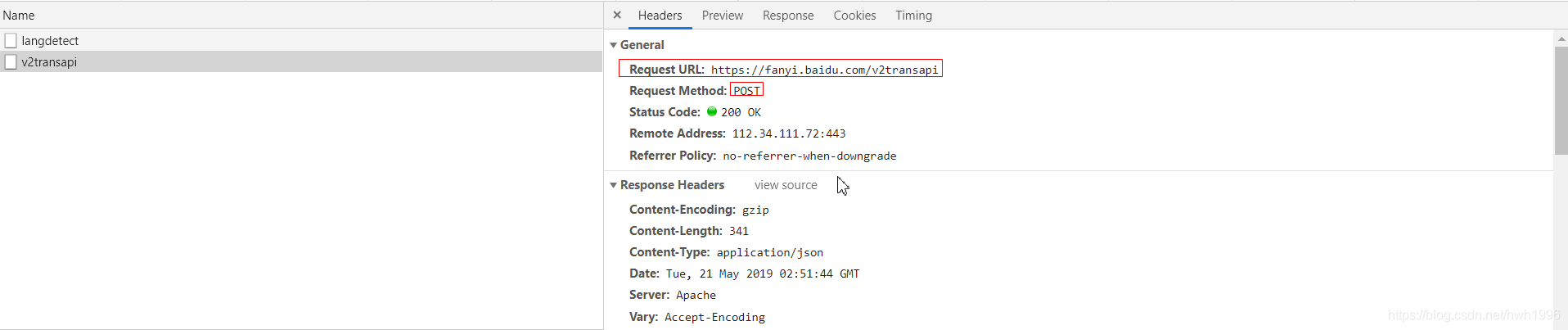
不难得出:
请求方式:POST
伪装成浏览器
经过测试,我们不仅要设置User-Agent值还需设置cookie进行身份验证。
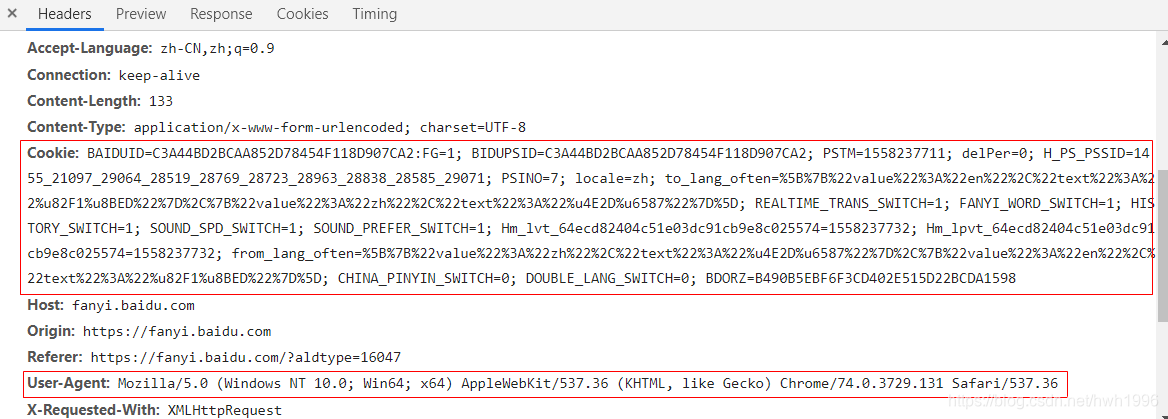
记录上图框选的数据用来构造headers。
分析表单–Form Data
因为是POST方式,自然需要构造表单数据(data),我们将滑轮滚到最下方,可以看到有一栏数据叫做Form Date:
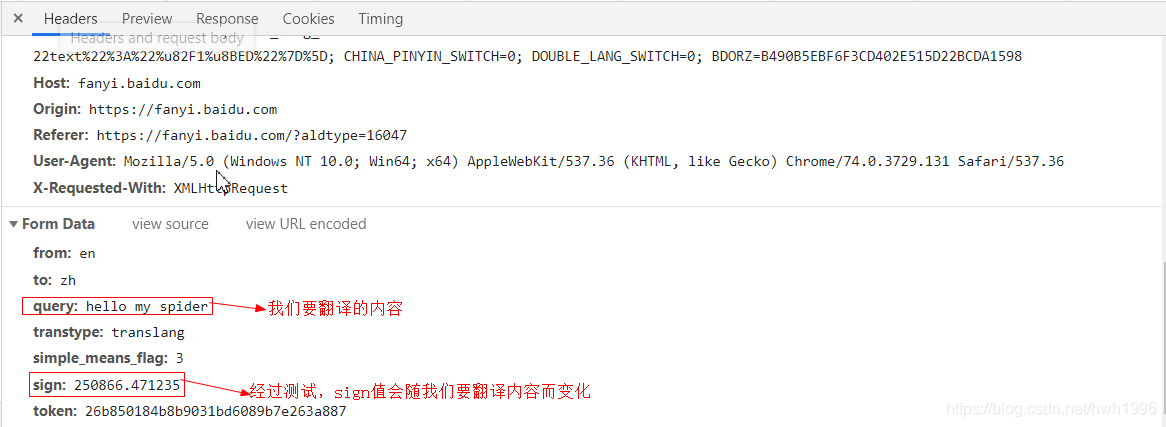
如上图所示,Form Date中只有两项是会变化的:
至此,我们便可以初步构造出表单date了以及URL& headers,代码见下:
import requests
import json
import jsonpath
import execjs
# 1.js逆向撸,注意要带上cookie
url = "https://fanyi.baidu.com/v2transapi"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Cookie": "BAIDUID=C3A44BD2BCAA852D78454F118D907CA2:FG=1; BIDUPSID=C3A44BD2BCAA852D78454F118D907CA2; PSTM=1558237711; delPer=0; H_PS_PSSID=1455_21097_29064_28519_28769_28723_28963_28838_28585_29071; PSINO=7; locale=zh; to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1558237732; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1558237732; from_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; CHINA_PINYIN_SWITCH=0; DOUBLE_LANG_SWITCH=0"
}
data = {
"from": "en",
"to": "zh",
"query": "", # query 即我们要翻译的的内容
"transtype": "translang",
"simple_means_flag": "3",
"sign": "", # sign 是变化的需要我们执行js代码得到
"token": "26b850184b8b9031bd6089b7e263a887" # token没有变化
}
最后,便是最重要的js逆向分析构造出sign值。
要分析sign值,当然要找到生成sign值的js文件。我们肯定不是盲目搜索,首先要确定搜索的关键词。
分析关键词—定位js文件
确定关键词,有两个方向:
从请求的URL出发。如我们此次请求的URL是:
那么我们可以确定关键词为v2transapi,进行搜索。
根据要分析的值,确定关键词为sign。
我们根据第一种方式确定的关键词v2transapi,ctrl+shift+f 打开搜索框进行搜索:

wawo~~只有一个,那么点进去看看是啥,并进行初步逆向:
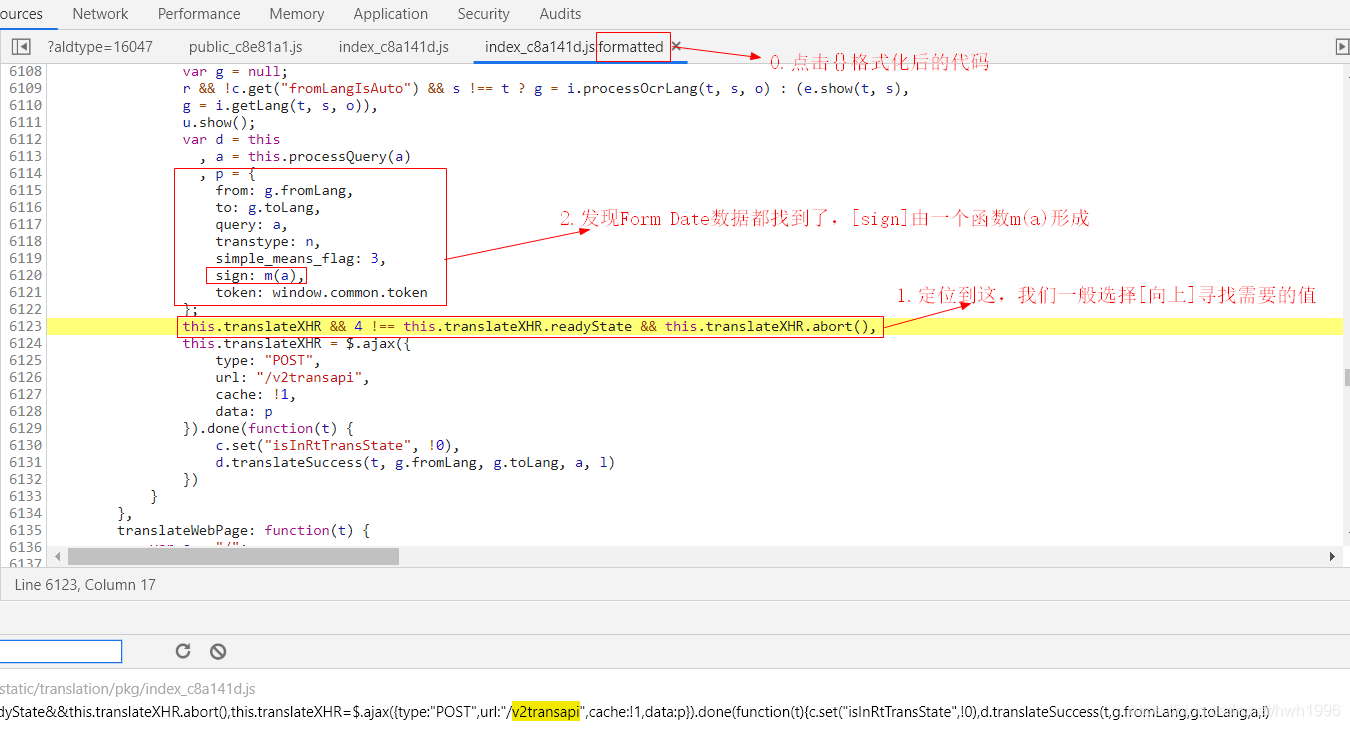
根据上图,大家能很快发现sign值是函数m(a)形成,a是参数。为了观察参数a究竟是什么 & 进入到m函数,我们开始进行一项逆向基本操作:打断点。
打断点—跟踪函数
下面这张图,展示了如何打上断点,跟踪生成sign的函数m:
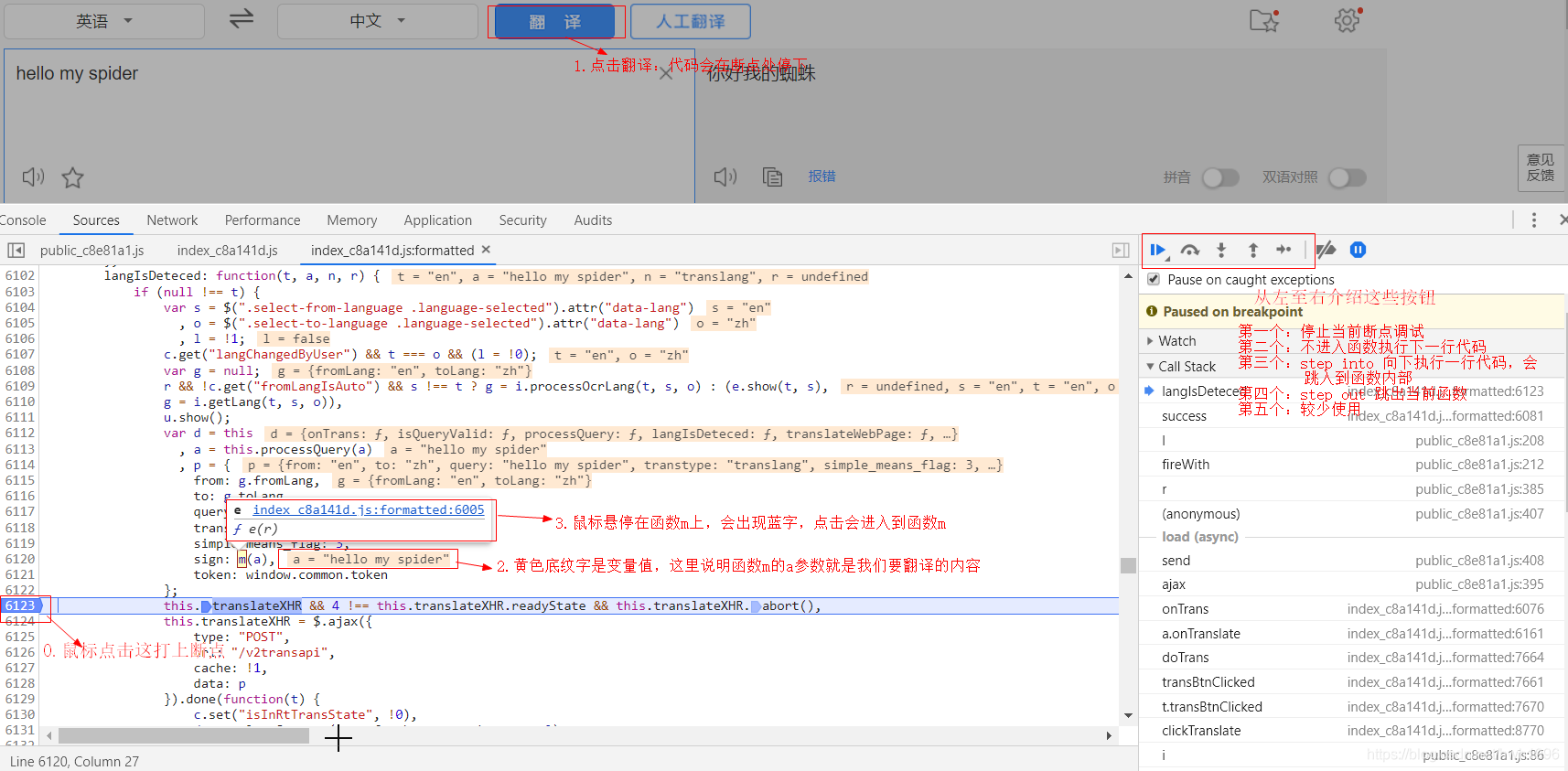
按照上面步骤,我们进行跳入到函数m中。
扣代码–生成sign
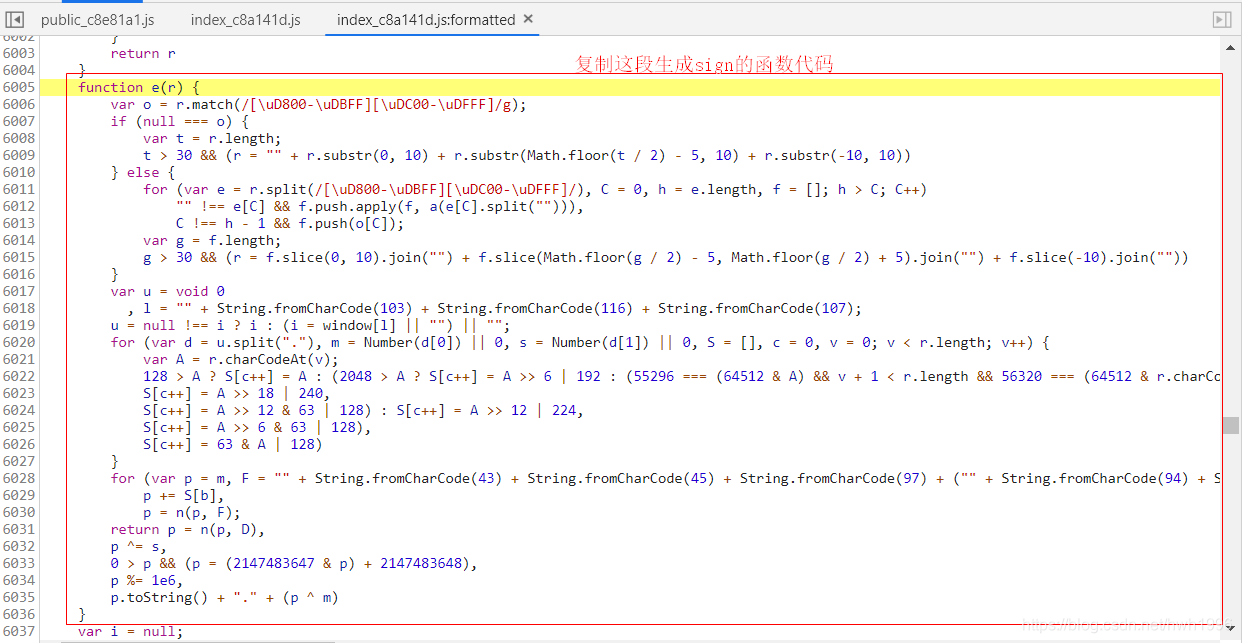
复制上面代码后,我们新建一个js文件,可名为:baidu_translate,粘贴上述代码。我用的是VScode + Code Runner扩展插件,来执行js代码。
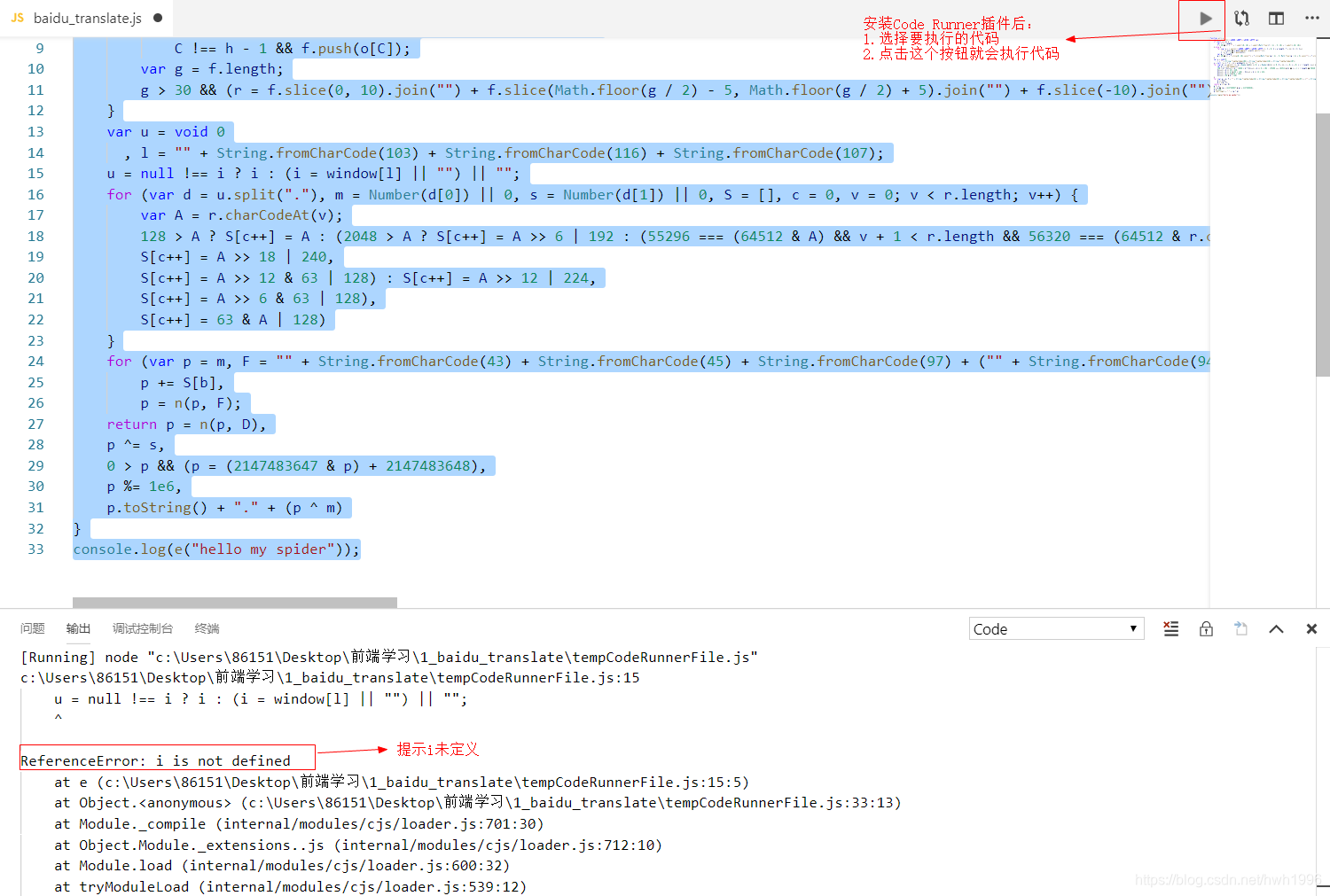
我们在第33行增添一段代码,尝试执行函数打印出sign值。显示i未定义错误,在浏览器js文件该函数中找到i,同上打上断点(在浏览器中,不是VScode),先观察下i会不会变化(不会变化再尝试扣下生成i的函数)。
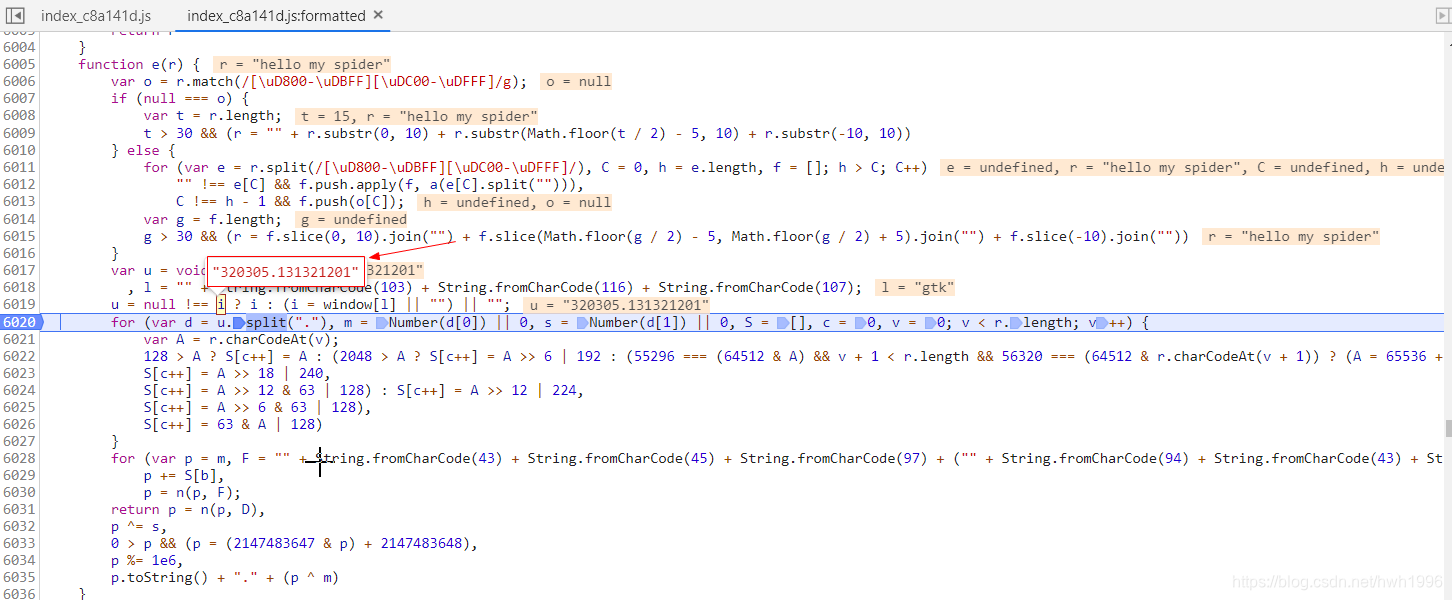
非常幸福的发现,当我们尝试改变要翻译的内容时,i值是不会变化的,且恒等于一个常数。我们就可以愉快的在VScode中复制的js代码最前面加上这段代码:
var i = "320305.131321201"
紧接着我们再尝试执行函数,又出现错误提示n未定义。故技重施,找到n,发现是一个函数,进入到函数把整个代码扣下来再复制到js代码最前面。
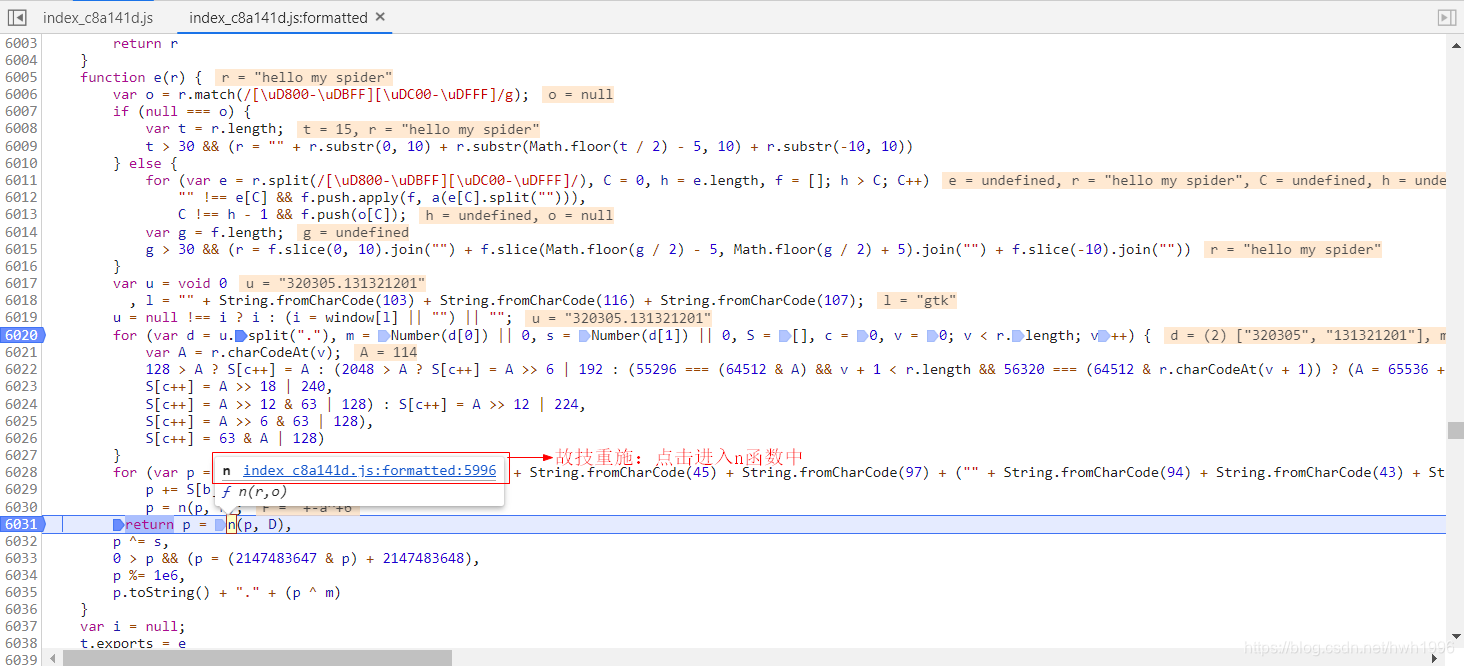

这个时候我们再执行代码看看会发生什么: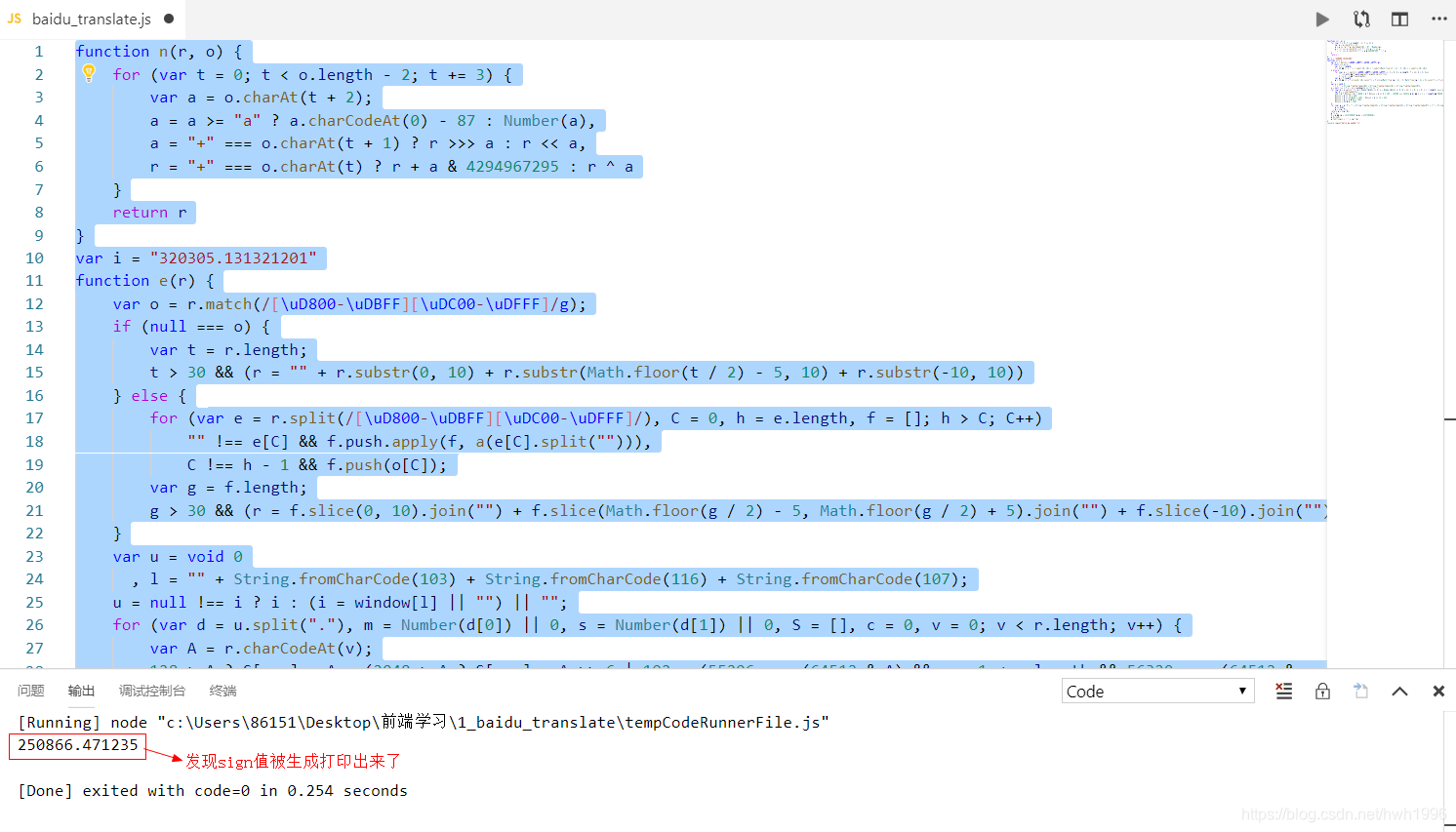
催人泪下,千出万唤使出来。那么,我们在python写的爬虫执行这个js文件baidu_translate.js取出sign值就可以构造出完整表单请求了。
python执行js代码
我们要在python中执行js代码,首先需要安装一个模块PyExecJS,同前python安装模块方法:
pip install PyExecJS
执行js代码获取sign值见下:
# 2.尝试执行js逆向得出sign值
# 读取js文件,特别注意:open(r"...",要带上r
with open(r"C:\Users\86151\Desktop\baidu_translate.js", "r", encoding="utf-8") as f:
ctx = execjs.compile(f.read())
sign = ctx.call("e", query)
# sign成功获取,写入date
data["sign"] = sign
完成爬虫—提取json格式数据
大家看到这有还记得前面我有给大家看过构造post请求,服务器返回一个json格式结果吗?唔,不知道大家对json格式数据处理模块json & jsonpath了解吗,如果不太熟悉,请看完下面的教程(偷偷告诉大家:一点都不难):
JSON入门教程
json解析神器 jsonpath的使用
让我们先来回想一下,服务器返回的json格式:
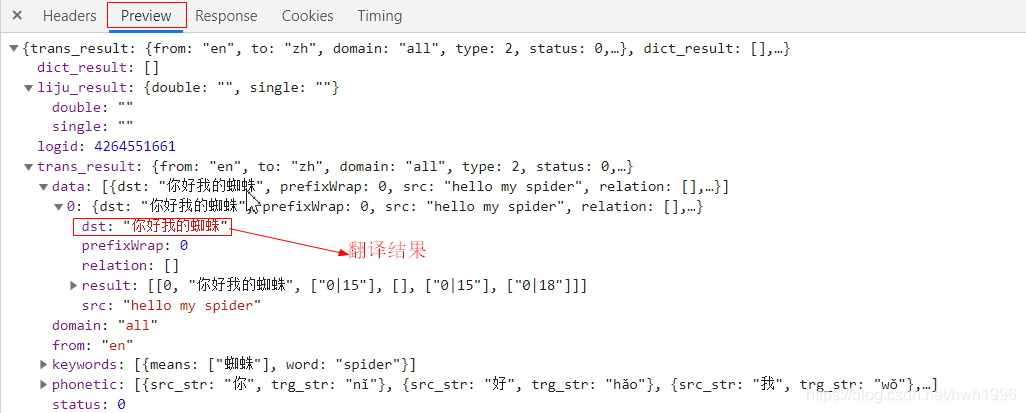
很自然可以写出下面jsopath语法匹配:
$..data.0.dst
$.. : 表示递归下降,会搜索全文匹配接下来所有符合的结果
data.0.dst : 选中date下子节点0子节点dst对应结果
完整的匹配代码:
# 3.请求翻译结果
response = requests.post(url, headers=headers, data=data)
# print(response.text)
json_date = json.loads(response.text)
result = jsonpath.jsonpath(json_date, '$..data.0.dst')
print(result[0]) # 返回结果是一个列表(虽然只有一项值)
运行结果:
由于整体代码还是比较简单明了的,所以没有进行面对对象重构,这里放上所有代码仅供参考。
import requests
import json
import jsonpath
import execjs
"""js逆向--百度翻译分析"""
"""
# 0.尝试构建URL访问---可行
url = "https://fanyi.baidu.com/?aldtype=16047#en/zh/hello%20spider"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0"
}
r = requests.get(url, headers=headers)
html = r.text
print(html)
"""
# js逆向撸,注意要带上cookie
# 1.初步构建表单
url = "https://fanyi.baidu.com/v2transapi"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Cookie": "BAIDUID=C3A44BD2BCAA852D78454F118D907CA2:FG=1; BIDUPSID=C3A44BD2BCAA852D78454F118D907CA2; PSTM=1558237711; delPer=0; H_PS_PSSID=1455_21097_29064_28519_28769_28723_28963_28838_28585_29071; PSINO=7; locale=zh; to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1558237732; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1558237732; from_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; CHINA_PINYIN_SWITCH=0; DOUBLE_LANG_SWITCH=0"
}
data = {
"from": "en",
"to": "zh",
"query": "", # query 即我们要翻译的的内容
"transtype": "translang",
"simple_means_flag": "3",
"sign": "", # sign 是变化的需要我们执行js代码得到
"token": "26b850184b8b9031bd6089b7e263a887" # token没有变化
}
# 2.尝试执行js逆向得出sign值
# 设置一下我们要翻译的内容
query = "hello spider"
data["query"] = query
# 执行js代码得到我们苦求的sign值
# 读取js文件
with open(r"C:\Users\86151\Desktop\前端学习\1_baidu_translate\baidu_translate.js", "r", encoding="utf-8") as f:
ctx = execjs.compile(f.read())
sign = ctx.call("e", query)
# print(sign)
# sign成功获取,写入date
data["sign"] = sign
# 3.请求翻译结果
response = requests.post(url, headers=headers, data=data)
# print(response.text)
json_date = json.loads(response.text)
result = jsonpath.jsonpath(json_date, '$..data.0.dst')
print(result[0])
一篇简单的js逆向分析便至此告一段落了,虽然简单但是我分析的详细呀~
现在还有两个坑没有填,一是滑块验证码破解教程 二是js逆向知乎登陆(很有难度)。您觉得有帮助请点个赞支持~我一定会接着更新的(我灰太狼还会回来的!)
谢谢您的阅读,如有错误敬请指正。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
