社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
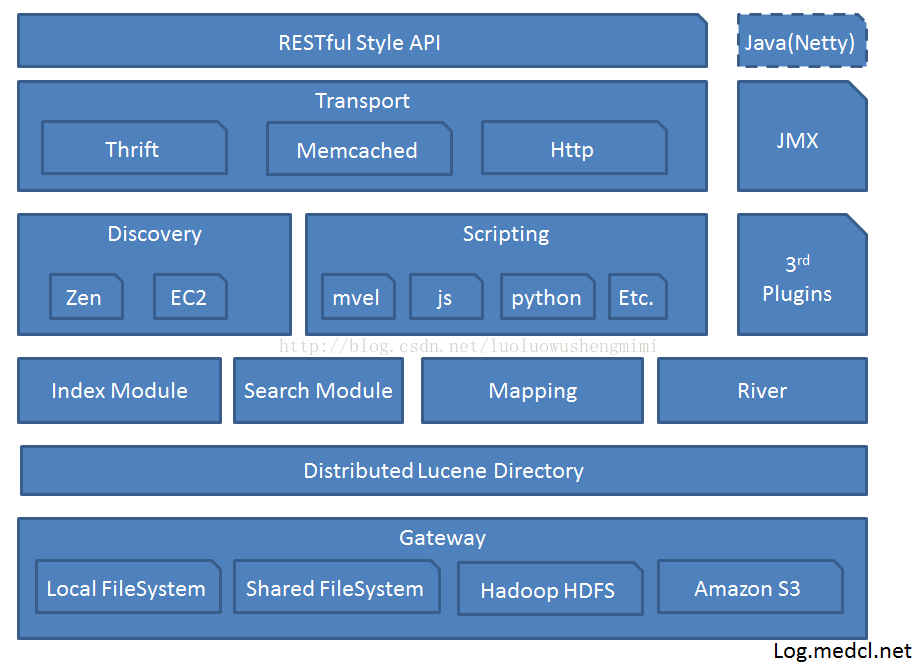
ElasticSearch 是一个基于Lucene构建的开源、分布式,RESTful搜索引擎。它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索的存储库)。ElasticSearch为应用程序提供搜索算法和相关的基础架构,用户只需要将应用程序中的数据上载到ElasticSearch数据存储中,就可以通过RESTful URL与其交互。ElasticSearch的架构明显不同于它之前的其他搜索引擎架构,因为它是通过水平伸缩的方式来构建的。不同于Solr,它在设计之初的目标就是构建分布式平台,这使得它能够和云技术以及大数据技术的崛起完美吻合。ElasticSearch构建在更稳定的开源搜索引擎Lucene之上,它的工作方式与无模式的JSON文档数据非常类似。
ElasticSearch的关键特征
在所有的ElasticSearch的介绍中都不可避免的提到了它是一种具有RESTful特点的搜索引擎。那么什么是RESTful呢?REST(Representational State Transfer表述性状态转移)是一种针对网络应用的设计和开发方式,可以降低开发的复杂性并提高系统的可伸缩性。REST有一些设计概念和准则,凡是遵循这些准则所开发的应用即具备RESTful风格。在REST风格结构中,所有的请求都必须在一个由URL制定的具体地址的对象上进行。例如,如果用/schools/代表一系列学校的话,/schools/1就代表id为1的那所学校,依次类推。这种设计风格为用户提供了一种简单便捷的操作方式,用户可以通过curl等RESTful API与ElasticSearch进行交互,避免了管理XML配置文件的麻烦。下面将简单介绍
一下通过curl工具对ElasticSearch进行CRUD(增删改查)操作。
l 索引构建
为了对一个JSON对象进行索引创建,需要向REST API提交PUT请求,在请求中指定由索引名称,type名称和ID组成的URL。即
http://localhost:9200/<index>/<type>/[<id>]
例如:curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year":1972
}'
l 通过ID获得索引数据
向已经构建的索引发送GET请求,即http://localhost:9200/<index>/<type>/<id>
例如:curl -XGET "http://localhost:9200/movies/movie/1" -d'’
l 删除文档
通过ID指定的索引删除单个文档。URL和索引创建、获取时相同。
例如:curl -XDELETE "http://localhost:9200/movies/movie/1" -d'’
由于ElasticSearch是专门为分布式环境设计的,所以怎么去对所有节点的索引信息进行持久化是个问题。当然,除了索引信息以外,还有集群信息,mapping和事务日志等都需要进行持久化。当你的节点出现故障或者集群重启的时候,这些信息就变得非常重要。ElasticSearch中有一个专门的gateway模块负责元信息的持久化存储。(Solr里边是不是通过Zookeeper在管理这部分?)
分面是指事物的多维度属性。例如一本书包含主题、作者、年代等方面。而分面搜索是指通过事物的这些属性不断筛选、过滤搜索结果的方法。当然这点在Lucene中已经得到了实现,所以Solr也支持faceted searching。至于precolating特性则是ElasticSearch设计中的一大亮点。Precolator(过滤器)允许你在ElasticSearch中执行与上文档、建立索引、执行查询这样的常规操作恰恰相反的过程。通过Precolate API,可以在索引上注册许多查询,然后向指定的文档发送prelocate请求,返回匹配该文档的注册查询。举个简单的例子,假设我们想获取所有包含了”elasticsearch”这个词的tweet,则可以在索引上注册一个query语句,在每一条tweet上过滤用户注册的查询,可以获得匹配每条tweet的那些查询。下面是一个简单的示例:
首先,建立一个索引:
curl –XPUT localhost:9200/test
接着,注册一个对test索引的precolator 查询,制定的名称为kuku
curl –XPUTlocalhost:9200/_precolator/test/kuku –d’{
“query”:{
“term”:{
“field1”:”value1”
}
}
}’
现在,可以过滤一个文本看看哪些查询跟它是匹配的
crul –XGETlocalhost:9200/test/type/_precolate –d’{
“doc”:{
“filed1”:”value1”
}
}’
得到的返回结构如下
{“ok”: true, “matches”: [“kuku”]}
ElasticSearch不同于Solr,从设计之初就是面向分布式的应用环境,因此具备很多便于搭建分布式应用的特点。例如索引可以被划分为多个分片,每个分片可以有多个副本,每一个节点可以持有一个或多个分片,自动实现负载均衡和分片副本的路由。另外,ElasticSearch具有self-contained的特点,不必使用Tomcat等servlet容器。ElasticSearch的集群是自发现、自管理的(通过内置的Zen discovery模块实现),配置十分简单,只要在config/elasticsearch.yml中配置相同的cluster.name即可。
ElasticSearch有一个叫做river的插件式模块,可以将外部数据源中的数据导入elasticsearch并在上面建立索引。River在集群上是单例模式的,它被自动分配到一个节点上,当这个节点挂掉后,river会被自动分配到另外的一个节点上。目前支持的数据源包括:Wikipedia, MongoDB, CouchDB, RabbitMQ, RSS, Sofa, JDBC, FileSystem,Dropbox等。River有一些指定的规范,依照这些规范可以开发适合于自己的应用数据的插件。
ElasticSearch通过river建立与各个数据源之间的连接。例如mongodb,这种连接方式多半是以第三方插件的方式,由一些开源贡献者贡献出来的插件建立与各种类型的数据管理系统以及MQ等建立river,索引数据的。本文主要研究的是MONGODB与ES的结合,用的是richardwilly98开发的river。
https://github.com/richardwilly98/elasticsearch-river-mongodb
由于ElasticSearch的MongoDBRiver必须通过监测MongoDB的一个rs.oplog表来同步索引数据,而该表只有在MongoDB的RepliSet和Sharding两种配置方式下才有,所以考虑到正常的生产模式一般都是sharding模式,所以本文在mongodb集群搭建上,选用了sharding模式,后续文章会介绍replica set模式。
| master1 | shard11 | shard32 | |
| master2 | shard12 | shard21 | |
| master3 | shard22 | shard31 |
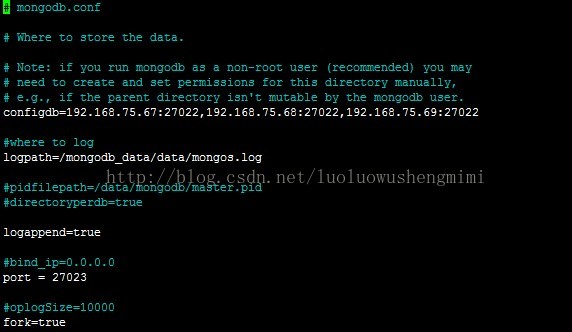
192.168.75.67 master1192.168.75.68 master2192.168.75.69 master3
master2 和master3 做同样处理2. 解压安装包# tar -zxvf mongodb-linux-x86_64-2.4.6.tgz3. 创建shard数据目录@master1:
mkdir -p /mongodb_data/data/shard11 mkdir -p /mongodb_data/data/shard32
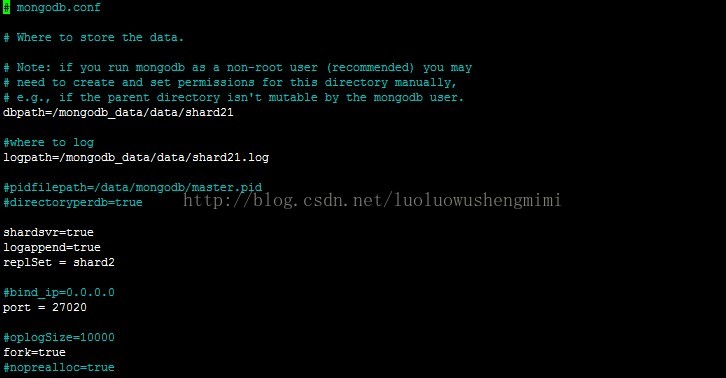
@master2:mkdir -p /mongodb_data/data/shard12 mkdir -p /mongodb_data/data/shard21
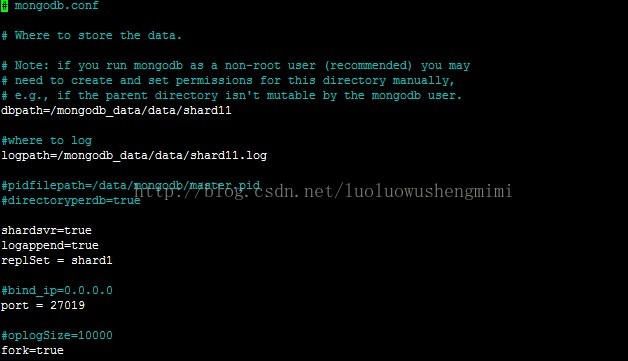
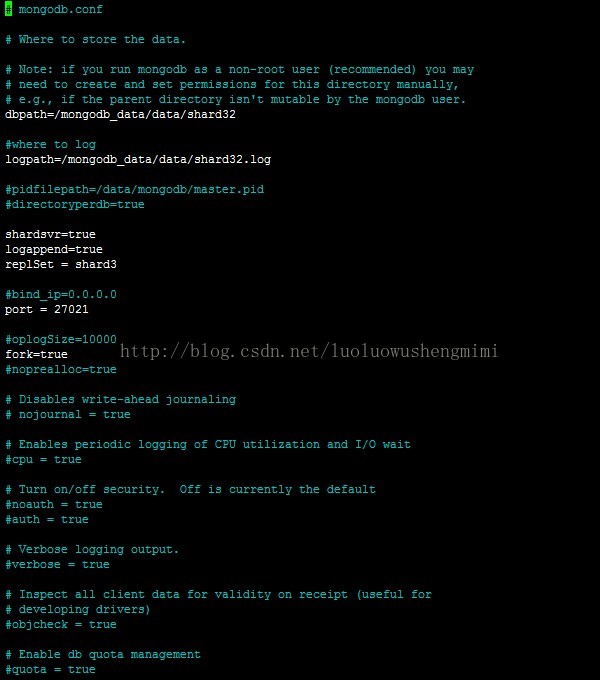
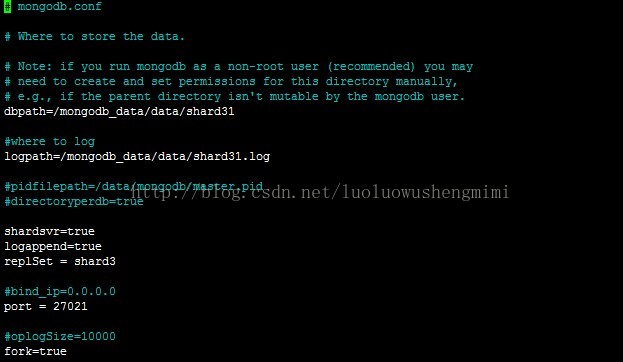
@master34. 配置replica sets、config server、配置mongosmkdir -p /mongodb_data/data/shard22 mkdir -p /mongodb_data/data/shard31@master1:配置replica sets编写文件mongodb_shard1.conf 和mongodb_shard3.conf
mongodb_shard1.conf:
mongodb_shard3.conf:
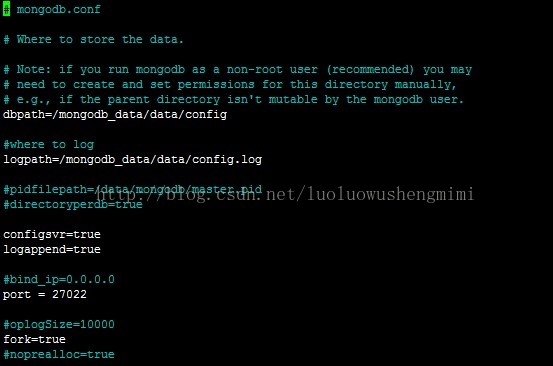
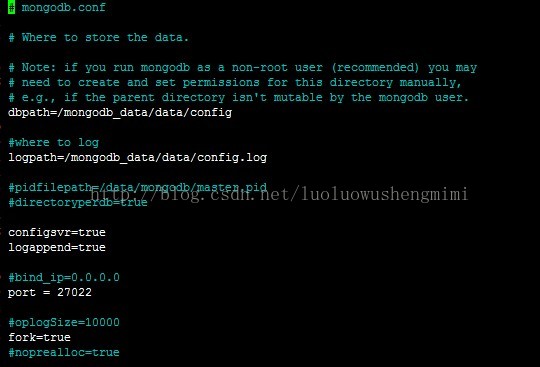
配置config server
配置mongos
@master2
配置replica sets
编写文件mongodb_shard1.conf 和mongodb_shard2.conf
mongodb_shard1.conf
mongodb_shard2.conf
配置config server
@master3
配置replica sets
编写文件mongodb_shard2.conf 和mongodb_shard3.conf
mongodb_shard2.conf
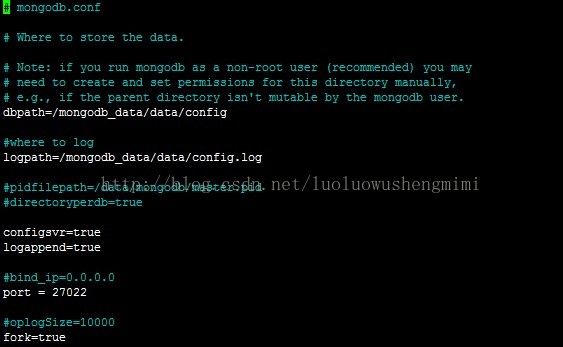
./mongod -f /etc/mongodb_shard1.conf
./mongod -f /etc/mongodb_shard3.conf
./mongod -f /etc/mongodb_shard1.conf
./mongod -f /etc/mongodb_shard2.conf
./mongod -f /etc/mongodb_shard2.conf ./mongod -f /etc/mongodb_shard3.conf
> config = {_id:'shard1',members:[ {_id: 0, host:'master1:27019'}, {_id: 1, host:'master2:27019'}] }
> rs.initiate(config)
> config = {_id:'shard2',members:[ {_id: 0, host:'master2:27020'}, {_id: 1, host:'master3:27020'}] }
> rs.initiate(config)
> config = {_id:'shard2',members:[ {_id: 0, host:'master3:27021'}, {_id: 1, host:'master1:27021'}] }
> rs.initiate(config)
./mongod -f /etc/mongodb_config.conf./mongos -f /etc/mongodb_mongos.confmongo 192.168.40.80:29023
> use admin
> db.runCommand({addshard:"shard1/master1:27019,master2:27019",name:"s1"})
> db.runCommand({addshard:"shard2/master2:27020,master3:27020",name:"s2"})
> db.runCommand({addshard:"shard3/master3:27021,master1:27021",name:"s3"})
1. 首先下载并且解压Elasticsearchunzip elasticsearch-0.90.5.zip
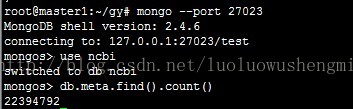
2 下载并且解压elasticsearch-servicewrapper-master.zipunzip elasticsearch-servicewrapper-master.zip3 启动elasticsearchcd elasticsearch-servicewrapper-master mv service /root/gy/elasticsearch-0.90.5/bin4 下载river插件sh elasticsearch start这里值得一提的是river的版本必须与mongodb 和ElasticSearch匹配,如果不匹配,那么river的时候不能将mongodb里面所有的数据index进入es。./plugin --install com.github.richardwilly98.elasticsearch/elasticsearch-river-mongodb/1.7.1匹配规则请见下方:
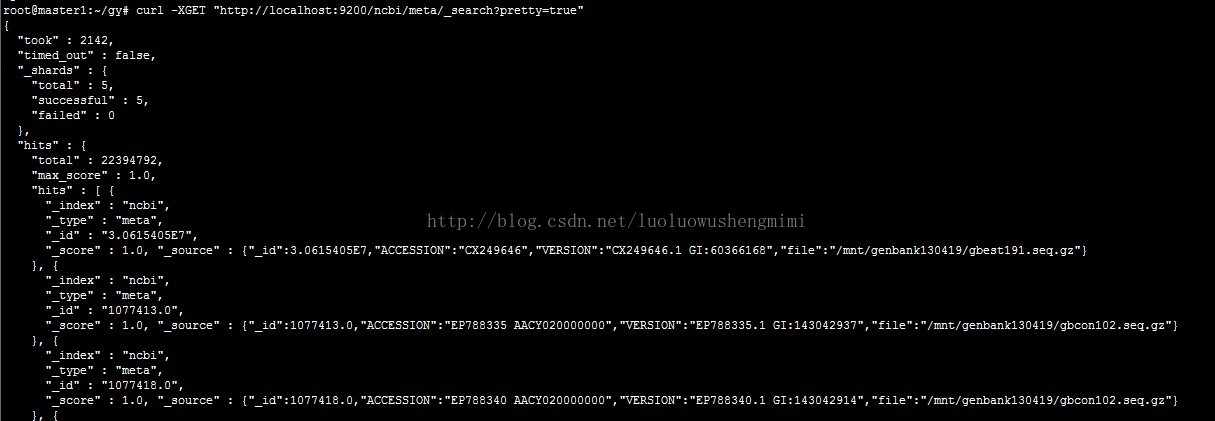
5 建立river由于本次测试使用的是mongodb sharding 集群环境,所以在river连接时,使用mongos 路由,就能够正常的把mongo集群中的所有数据都建立索引。curl -XPUT "http://localhost:9200/_river/mongodb/_meta" -d' { "type":"mongodb", "mongodb":{ "servers":[{"host":"192.168.75.67","port":27023}], "db":"ncbi", "collection":"meta", "gridfs":false, "options":{ "include_fields":["_id","VERSION","ACCESSION","file"] } }, "index":{ "name":"ncbi", "type":"meta" } }'6 测试例子连接mongo集群,meta collection数据量有22394792条数据
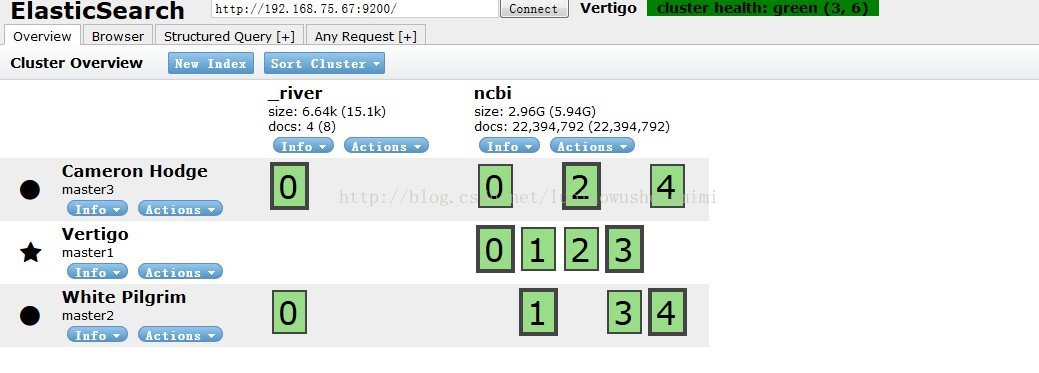
查看ES数据量最后我在master1 master2 master3上都建立了ElasticSearch,并且3太es rebalance成功,并且数据的总数任然为22394792.
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!