社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
注意race 会限制 goroutine 的数量到8192,并且在分析的过程中增加额外的CPU 开销,因此建议只在测试环境中使用。
开启并运行服务之后,如果服务有多个协程同时使用同一个变量,就会打印warning 的提示:
go tool objdump -s 方法名 可执行文件
首先在主方法中引用pprof 相关包:
import (
"net/http"
_ "net/http/pprof"
)
然后通过net/http 包启动http 端口即可
编译并执行:
go build -mod=vendor -o httpserver httpserver.go
nohup ./httpserver > test.log 2>&1 &
补充:使用gin 框架可以直接使用如下的方式开启pprof:
官方示例
go func() {
router := gin.Default()
pprof.Register(router)
router.Run(":8082")
}()
首先还是先来分析正常情况, 手动执行:
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=60
最后的参数表示60s 之后,会输出 CPU 使用情况的性能报告,然后我们就可以通过top 分析哪个方法占用CPU 最多了,如下: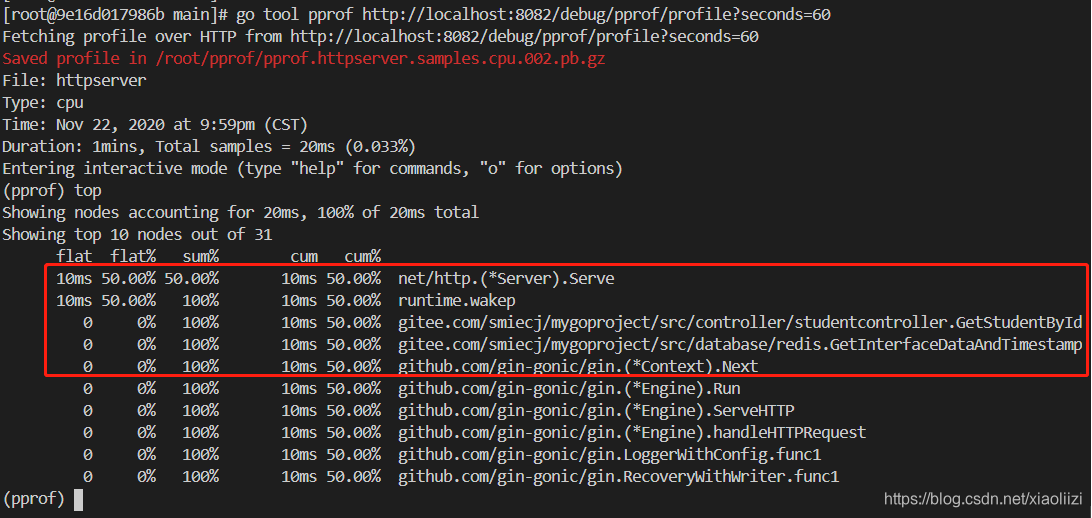
简单说明一下:在这60s 内我调用了几次 获取学生信息的接口,因此能看到占用CPU 高的前几个方法,要么是http 通信相关的包,要么是业务逻辑。Runtime.wakep 是 go程序内部负责唤醒一个新 goroutine 的方法(源码位置: runtimeproc.go)。
再说明一下几个参数的含义:
flat:方法运行的次数 * 采样频率(10ms),不包括调用的其他方法的使劲
cum:flat + 调用其他方法,整个调用链的时间
如何模拟一个比较频繁、不太正常的CPU 使用情况:我们可以模拟数组不断append,并保证基本能扩大其容量,代码如下:
intArr := make([]int, 0)
arrSize := 1000
var addCount uint64
for {
for index := 0; index < arrSize; index++ {
intArr = append(intArr, index)
}
time.Sleep(10 * time.Millisecond)
addCount++
if addCount%100 == 0 {
log.Printf("[test] 第%d次添加元素, 数组的cap: %d", addCount, cap(intArr))
}
// 测试GC:为了避免程序无限申请内存最后崩溃,设定重置点
if cap(intArr) > 10000000000 {
intArr = make([]int, 0)
}
}
然后再次查看CPU 执行情况: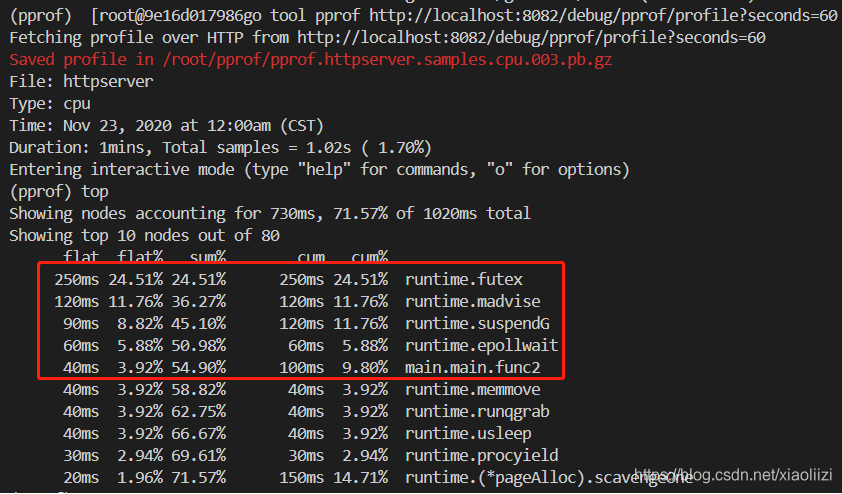
这里依然有几个和系统相关的方法:
runtime.futex:由go 程序内部调用,一般不会由业务代码主动触发,和协程状态同步、时钟同步(参考博客)可能有关系,这里暂时不用管这个。
runtime.madvise: 释放内存操作,可能和GC有关。详细可参考 go 源码 go/src/runtime/mem_linux.go,这里说明程序进行了比较频繁的GC,参考博客
runtime.suspendG: 和 futex 类似,和 协程之间的状态切换有关系
runtime.epollwait:从名字上看应该是和HTTP 请求调度相关,但是不太明白没有发请求的时候为什么也这么高,还需要进一步确认
综上所述,当你能看到系统调用持续占用非常高的时候,就要怀疑业务代码是否有什么地方一直在执行内存的申请以及GC 操作了。
当然,profile 本身还有 channel 同步是否会阻塞、锁竞争是否会导致死锁的检查,这不是本节的重点,后续再补充。
指令:
go tool pprof -inuse_space 可执行文件 http://localhost:8082/debug/pprof/heap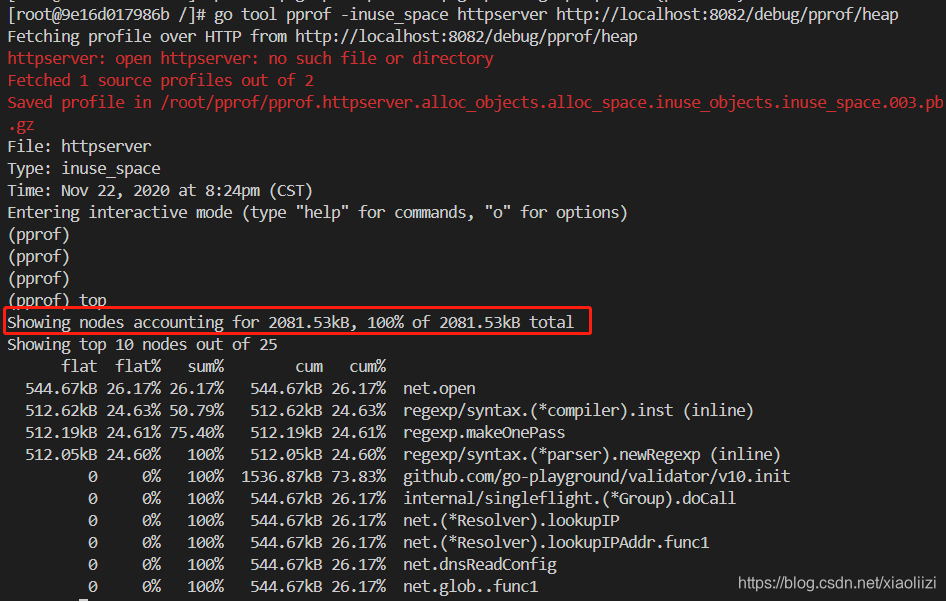
可以看到程序占用的内存大小,大概是2m。当然这里和 /proc/pid/status 看到的数据不太一致,可能是因为pprof 中不包含 go 本身运行环境的内存。
(注意:这个数据并不是实时刷新的,每次执行top 看到的信息都一样。需要先exit 退出去再重新进来)
然后同样的思路,和刚才测试CPU一样的代码,查看从内存申请数组的情况
可以看到明显的内存占用的上升(从2M 多直接到33M),并且都集中在新开启的协程上。
参考博客
业务可能存在这种场景:有的接口调用比较频繁,因此从一个时间点看确实内存上涨很多,但是它不一定是有问题的,这些申请的小内存在接口调用完成之后就会被释放。
这个时候可以将连续两个时间点的内存打印出来,再使用 go tool pprof --base 进行两个内存使用情况的对比: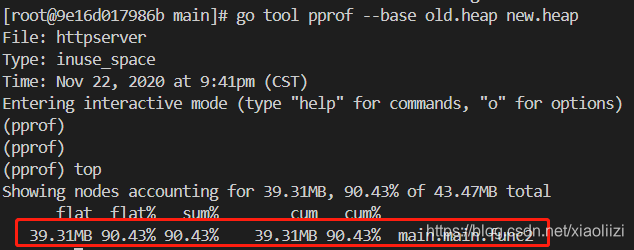
可以看到内存上涨确实是由新写的这个协程导致的。
go tool pprof http://localhost:6060/debug/pprof/goroutine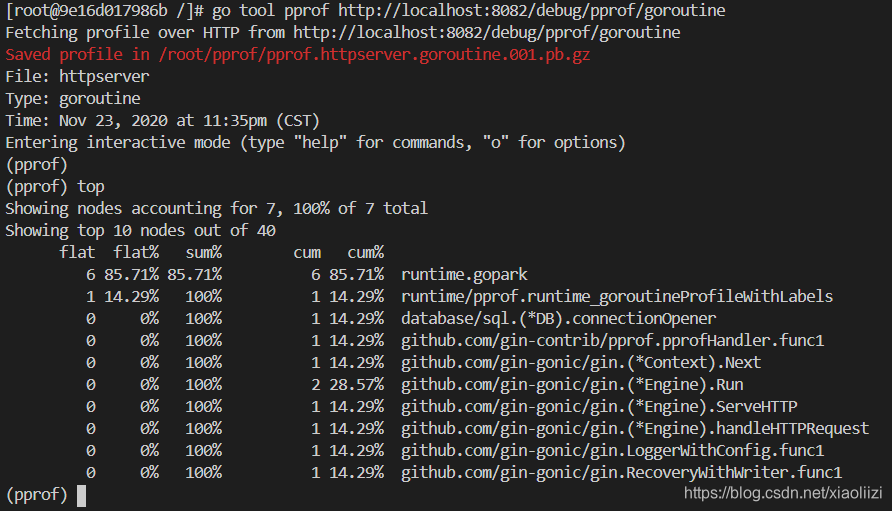
其中,runtime.gopark 表示是一个负责调度执行中的协程的任务。
正常情况下routine 在执行完成之后肯定资源能被释放的。那么routine 泄漏的场景当然是本来应该结束,但是实际并没有结束的情况,于是可以写出下面的代码:
func TestRoutineLeak() {
channel := make(chan int, 1)
go func() {
index := <-channel
log.Printf("[TestRoutineLeak] routine 1: %d", index)
}()
go func() {
index := <-channel
log.Printf("[TestRoutineLeak] routine 2: %d", index)
}()
go func() {
index := <-channel
log.Printf("[TestRoutineLeak] routine 3: %d", index)
}()
channel <- 1
time.Sleep(10 * time.Second)
//close(channel)
}
Channel 最后如果被关闭掉了,当然没什么问题。但是如果没close,其中两个协程就会一直等待结束。
这样就可以看到有两个协程一直没有被释放: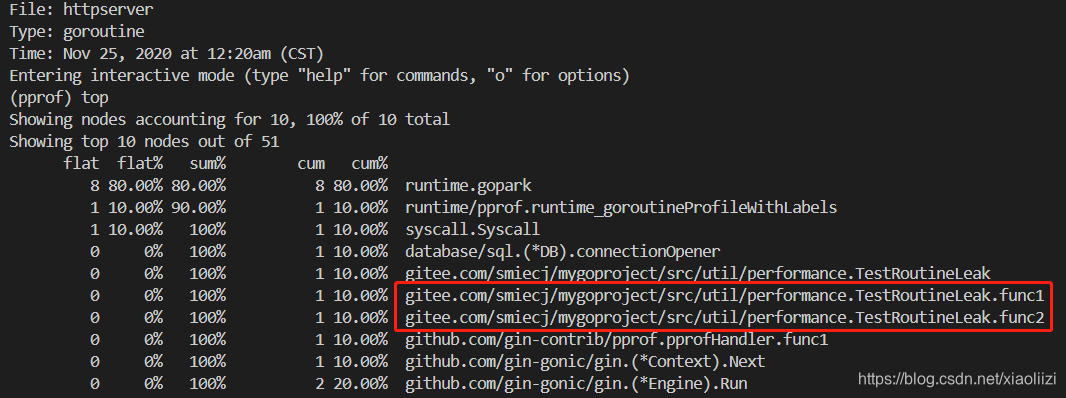
| 参数 | 含义 | 默认值 |
|---|---|---|
| GOMAXPROCS | go 的runtime 结构 GPM 中的M,表示同时间内最多有多少个processor 在运行。注意是用户态线程,和go 通过系统调用触发创建的线程数没有关系。 | 没有限制。默认和机器的CPU保持一致,但是如果是IO 密集型程序,可以再调高一些。 |
| GOGC | GC 触发比例,新申请的内存大小 / 上一次GC 之后剩余的空间大小 | 100,调试的时候可设置为OFF |
| NextGC | GC 出发条件,堆大小超过 NextGC 之后就会开始GC | 依赖GOGC 和上次GC 情况,计算后结果 |
| GODEBUG | 开启debug 的意思,下面还有很多参数可以调试 | 一些工具:gcvis-gotrace |
| GODEBUG-gctrace | 打印每次GC 的详细信息 | |
| GODEBUG-schedtrace | GC周期设置 | 单位:毫秒 |
| GODEBUG-scheddetail | GPM模型的详细状态 | |
| GODEBUG-tracebackancestors | 设置tracebackancestors = N,将会在触发堆栈信息打印的时候,打印N个“祖先”routine的数量 | |
| GODEBUG-asyncpreemptoff | 设置 = 1,将会禁止基于信号造成的goroutine 抢占。一般用于定位GC 的问题 |
GC打印内容详细分析可以参考后续的专题
GOMAXPROCS=8 GOGC=100 GODEBUG=‘gctrace=1’ nohup ./可执行文件 > test.log 2>&1 &
可以看到一开始数组扩容比较频繁,所以GC 也是比较频繁的。后续内存扩到有几个G 之后,GC 就明显放缓了,设置会触发到2分钟一次的强制GC
这段强制清理的逻辑在源码runtime/proc.go 中,开头的注释中也非常详细地介绍了 GPM 模型,值得一看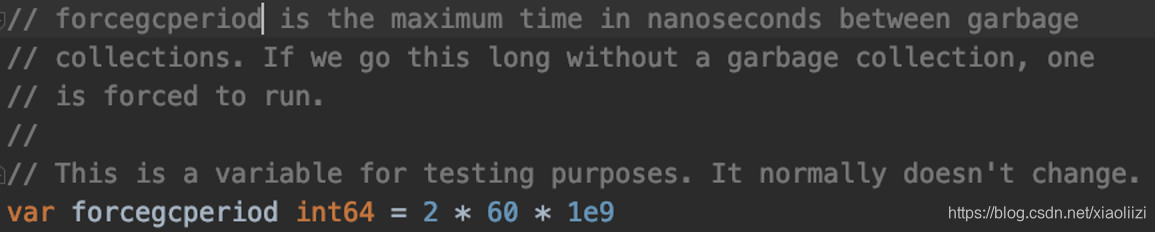
GOMAXPROCS=8 GOGC=100 GODEBUG=‘schedtrace=1000’ nohup ./可执行文件 > test.log 2>&1 &
这里会打印一些GC 的信息,前面表格中有说过了,但是比较简单,如果想要分析GC 的详细信息需要加上 tracebackancestors 参数。详细内容后续开专题详细讲解。
线上环境和测试环境不同之处在于我们可能没有给程序单独开一个端口,可以直接访问pprof 相关数据,这种情况下我们可能只能借助系统工具来单独分析了:
这里我们运行前面运行过的,频繁申请新数组空间的程序,然后查看:
perf top -p 25573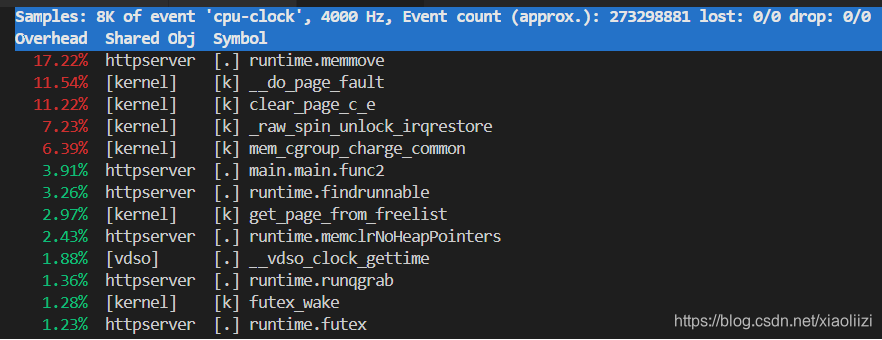
可以看到是runtime.memmove 占用最高,这也印证了实际情况:对slice 频繁的扩容,确实会对性能造成影响。
(注意:其中CPU 的占比是开始执行perf 到现在的整体情况,因此需要运行一段时间之后才能看的出来)
perf record -g -p 25573 – sleep 120
perf report --no-children
效果: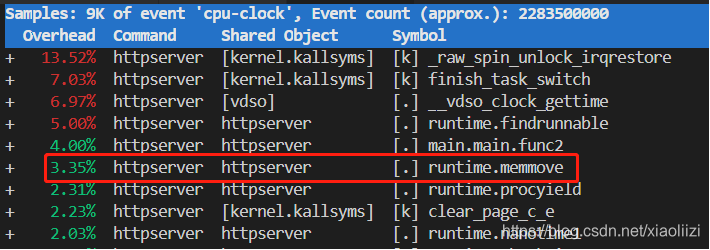
对于内存来说,其实线上程序是比较难操作的,我们可能只能通过top、pmap 等语句查看进程的总内存大小,但是也不好分析具体是哪块内存占用多。还是需要打开pprof 之后才能更好地分析。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
